实体关系抽取与属性补全的技术浅析
目录
- 前言
- 1. 实体关系抽取
- 2 实体关系抽取的方法
-
- 2.1 基于模板的方法
- 2.2 基于监督学习的关系抽取
- 2.3 基于深度学习的关系抽取
- 2.4 基于预训练语言模型的关系抽取
- 3 属性补全
-
- 3.1 属性补全任务简介
- 3.1 抽取式属性补全
- 3.2 生成式属性补全
- 4 未来发展趋势
- 结语
前言
在信息爆炸时代,文本数据蕴含着丰富的知识,但要将这些知识整理成结构化的形式,关系抽取和属性补全成为至关重要的任务。本文将深入探讨实体关系抽取的任务定义、分类、技术手段,以及属性补全的各种方法和应用。
1. 实体关系抽取
实体关系抽取是自然语言处理领域中一项重要任务,其目标在于从文本中识别和提取出两个或多个实体之间的关系。这一任务的核心应用领域之一是知识图谱构建,通过抽取实体之间的关系,可以构建结构化的知识表示,为计算机理解和推理文本信息提供基础。

实体关系抽取的重要性在于它能够将非结构化的文本信息转化为结构化的知识表示,使得计算机能够更好地理解语言中蕴含的关系信息。这对于构建智能系统、搜索引擎以及推荐系统等应用有着深远的影响。
在现实应用中,实体关系抽取广泛应用于医学、金融、社交网络分析等领域。例如,在医学领域,可以通过抽取文本中的疾病和药物之间的关系,帮助医学研究人员更好地了解疾病治疗方面的信息。
2 实体关系抽取的方法
2.1 基于模板的方法
实体关系抽取的一种传统方法是基于模板的方法,包括基于触发词匹配和基于依存句法匹配的关系抽取。在触发词匹配中,系统会寻找文本中是否存在特定的触发词,这些词往往与某种关系的存在相关联。在依存句法匹配中,通过分析句子中实体之间的依存关系来推断它们之间的关系。尽管这种方法小规模容易实现且构建简单,但需要专家构建规则,难以维护,可移植性差且规则召回率低。
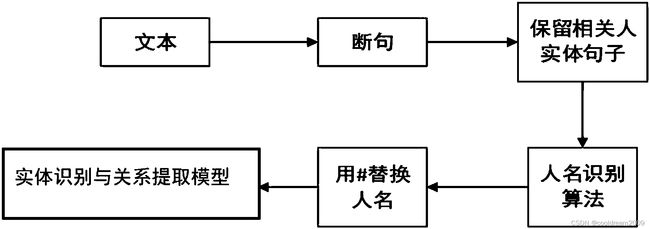
2.2 基于监督学习的关系抽取
采用监督学习的方法,其中at-least-one hypothesis是基本假设,即如果两个实体之间存在关系,则会有句子描述这种关系。在此过程中,需要设计合适的特征,包括实体和关系的特征。通常使用机器学习框架,如最大熵模型,结合特征函数进行建模。核函数的使用,例如字符串核、句法树核函数,通常需要词性标注和句法分析的支持。
2.3 基于深度学习的关系抽取
近年来,深度学习方法在实体关系抽取中取得了显著的进展。基于卷积神经网络(CNN)的方法通过卷积操作捕捉局部信息,基于双向长短时记忆网络(BiLSTM)的方法则能够更好地捕捉序列信息。此外,基于图神经网络的方法充分利用实体之间的拓扑结构,提高了关系抽取的准确性。
2.4 基于预训练语言模型的关系抽取
引入预训练语言模型(如BERT、GPT)的方法对实体关系抽取进行了进一步的拓展。通过在大规模语料上进行预训练,模型能够学到更丰富的语言表示,提高关系抽取的泛化能力。同时,探讨了一些拓展问题,包括实体关系联合抽取、误差传播问题等。
这些不同方法代表了实体关系抽取领域在不同阶段的技术演进,从传统的规则匹配到深度学习和预训练模型的兴起。这种演进为实体关系抽取提供了更为灵活和高效的解决方案,使其在应对复杂文本数据中的关系提取任务上更具优势。
3 属性补全
3.1 属性补全任务简介
在知识图谱和实体关系抽取的背景下,属性补全是一项关键任务,旨在从文本中获取实体的属性信息,进一步丰富知识图谱。属性补全主要涉及属性知识和描述性的属性,同时采用不同的方法,主要包括抽取式属性补全和生成式属性补全。
属性知识是指与实体相关的各种属性信息,例如一个人的出生日期、公司的创办时间等。描述性的属性则是对实体属性的详细描述,使得这些属性更具可解释性和语义丰富性。属性知识的获取对于知识图谱的完善和实体关系的更全面理解至关重要。
3.1 抽取式属性补全
抽取式属性补全是指从文本中直接抽取已知的实体属性,通常限制在已经出现过的属性值上。这种方法的优势在于准确度较高,有一定的解释性。然而,其局限性在于只能提供已知属性值的信息,对于新出现的属性值无法进行有效的预测。
3.2 生成式属性补全
生成式属性补全的目标是预测不在文本中出现过的属性值,从而使实体的属性信息更加完整。这种方法更灵活,但也面临着一些挑战,特别是对于低频或没有出现过的属性,预测的属性值可能缺乏解释性。然而,生成式方法的应用范围更广,能够处理更复杂的属性补全任务。
属性补全的方法和策略的选择取决于具体的应用场景和任务需求。在实际应用中,综合考虑抽取式和生成式的优势,结合深度学习和预训练模型等技术手段,有望进一步提高属性补全的效果和应用范围。未来,属性补全将在知识图谱构建和信息抽取等领域发挥越来越重要的作用。
4 未来发展趋势
智能化与高效性。 未来的方法将更加注重模型的智能化和高效性,通过结合多模态信息、跨领域知识融合,提高模型的全局理解和推断能力。
多模型融合。将不同的关系抽取方法进行融合,如结合图神经网络和预训练语言模型,以利用它们各自的优势,提高综合性能。

对抗性学习应对噪声。针对标注数据中的噪声,未来的方法可能更多地采用对抗性学习,以提高模型对噪声的鲁棒性。
自监督学习。自监督学习可能成为一种重要的方向,通过设计任务来利用未标注数据,提高模型在有限标注数据情况下的性能。
领域适应与迁移学习。 针对特定领域的数据,领域适应和迁移学习将变得更为重要,以提高模型在不同领域上的泛化能力。
综合来看,未来实体关系抽取技术的发展趋势将更加注重综合性能和应对多样化挑战,使得模型在真实世界的复杂语境中更具鲁棒性和适应性。
结语
实体关系抽取和属性补全作为自然语言处理领域的关键任务,在不断演进中为构建知识图谱和挖掘文本信息提供了有力支持。从基于规则的方法到深度学习和预训练模型的兴起,我们见证了这一领域的巨大发展。未来,随着技术的不断创新,实体关系抽取和属性补全将在更多领域展现出强大的应用前景。