强化学习原理python篇02——贝尔曼公式推导和求解
强化学习原理python篇02——贝尔曼公式
- 概念
-
- bootstrapping(自举法)
- state value
- 贝尔曼公式(Bellman Equation)
- 贝尔曼公式以及python实现
-
- 解法1——解析解
- 解法2——迭代法
- atcion value
- Ref
本章全篇参考赵世钰老师的教材 Mathmatical-Foundation-of-Reinforcement-Learning State Values and Bellman Equation章节,请各位结合阅读,本合集只专注于数学概念的代码实现。
概念
以bootstrapping来介绍状态值
bootstrapping(自举法)

让v代表从s1,…,s4的回报
v 1 = r 1 + γ r 2 + γ r 3 2 + . . . = r 1 + γ v 2 ; v 2 = r 2 + γ r 2 + γ r 3 2 + . . . = r 2 + γ v 3 ; v 3 = r 3 + γ r 2 + γ r 3 2 + . . . = r 3 + γ v 4 ; v 4 = r 4 + γ r 2 + γ r 3 2 + . . . = r 4 + γ v 1 ; v_1 = r_1 + γ_{r_2} + γ^2_{r_3} + ... =r_1+\gamma v_2;\\ v_2 = r_2 + γ_{r_2} + γ^2_{r_3} + ... =r_2+\gamma v_3;\\ v_3 = r_3 + γ_{r_2} + γ^2_{r_3} + ...=r_3+\gamma v_4 ;\\ v_4 = r_4 + γ_{r_2} + γ^2_{r_3} + ...=r_4+\gamma v_1 ;\\ v1=r1+γr2+γr32+...=r1+γv2;v2=r2+γr2+γr32+...=r2+γv3;v3=r3+γr2+γr32+...=r3+γv4;v4=r4+γr2+γr32+...=r4+γv1;
用矩阵表示为
[ v 1 v 2 v 3 v 4 ] = [ r 1 r 2 r 3 r 4 ] + γ [ 0 , 1 , 0 , 0 0 , 0 , 1 , 0 0 , 0 , 0 , 1 1 , 0 , 0 , 0 ] [ v 1 v 2 v 3 v 4 ] \left [\begin{matrix}v_1\\v_2\\v_3\\ v_4 \end{matrix} \right ] = \left [\begin{matrix}r_1\\r_2\\r_3\\ r_4 \end{matrix} \right ]+\gamma \left [\begin{matrix}0,1,0,0\\0,0,1,0\\0,0,0,1\\1,0,0,0 \end{matrix} \right ]\left [\begin{matrix}v_1\\v_2\\v_3\\ v_4 \end{matrix} \right ] v1v2v3v4 = r1r2r3r4 +γ 0,1,0,00,0,1,00,0,0,11,0,0,0 v1v2v3v4
写作
v = r + γ P v v = ( 1 − γ P ) − 1 r \pmb v = \pmb r + \pmb{γP} v\\ \pmb v =(1- \pmb{γP})^{-1} \pmb{r} v=r+γPvv=(1−γP)−1r
state value
S t → A t S t + 1 ; R t + 1 S_t \stackrel{At} {\rightarrow}S_{t+1}; R_{t+1} St→AtSt+1;Rt+1
表示从状态st做出动作at到 s t + 1 s_{t+1} st+1,并且获得鼓励 R t + 1 R_{t+1} Rt+1,从t开始,可以获得一个trajectory
S t → A t S t + 1 ; R t + 1 → A t + 1 S t + 2 ; R t + 2 → A t + 2 S t + 3 ; R t + 3 . . . S_t \stackrel{At} {\rightarrow}S_{t+1}; R_{t+1}\stackrel{A_{t+1}} {\rightarrow}S_{t+2}; R_{t+2}\stackrel{A_{t+2}} {\rightarrow}S_{t+3}; R_{t+3}... St→AtSt+1;Rt+1→At+1St+2;Rt+2→At+2St+3;Rt+3...
discounted return 为
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . γ ∈ ( 0 ; 1 ) G_t = R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+... \\ \gamma \in (0; 1) Gt=Rt+1+γRt+2+γ2Rt+3+...γ∈(0;1)
state value 被定义为
v π ( s ) = E [ G t ∣ S t = s ] v_\pi(s)=E[G_t|S_t=s] vπ(s)=E[Gt∣St=s]
贝尔曼公式(Bellman Equation)
首先,t 时候的trajectory的discount reward为
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = R t + 1 + γ ( R t + 2 + γ R t + 3 + . . . ) = R t + 1 + γ G t + 1 \begin{align*}G_t =& R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+... \\ =&R_{t+1}+\gamma (R_{t+2}+\gamma R_{t+3}+...)\\ =&R_{t+1}+\gamma G_{t+1} \end {align*} Gt===Rt+1+γRt+2+γ2Rt+3+...Rt+1+γ(Rt+2+γRt+3+...)Rt+1+γGt+1
则该状态值为
v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] \begin{align*} v_\pi(s)=&E[G_t|S_t=s] \\ =&E[R_{t+1}+\gamma G_{t+1}|S_t=s] \\ =&E[R_{t+1}|S_t=s]+\gamma E[G_{t+1}|S_t=s] \end{align*} vπ(s)===E[Gt∣St=s]E[Rt+1+γGt+1∣St=s]E[Rt+1∣St=s]+γE[Gt+1∣St=s]
根据全期望公式(the law of total expectation) E ( E ( Y ∣ X ) ) = E ( Y ) E(E(Y|X))=E( Y) E(E(Y∣X))=E(Y)
E [ R t + 1 ∣ S t = s ] = ∫ r ∈ R r f R ∣ S ( r ∣ S t = s ) d r = ∫ r ∈ R r f R , S ( r , S t = s ) f S ( S t = s ) d r = ∫ r ∈ R r f R , S ( r , S t = s ) f S , A ( S t = s , A t = a ) ⋅ f S , A ( S t = s , A t = a ) f S ( S t = s ) d r = ∫ r ∈ R r f R , S ( r , S t = s ) f S , A ( S t = s , A t = a ) ⋅ f A ∣ S ( a ∣ S t = s ) d r = ∫ r ∈ R r ∫ a ∈ A f R , S , A ( r , a , S t = s ) f S , A ( S t = s , A t = a ) ⋅ f A ∣ S ( a ∣ S t = s ) d r = ∫ r ∈ R r ∫ a ∈ A f R ∣ S , A ( r ∣ a , S t = s ) ⋅ f A ∣ S ( a ∣ S t = s ) d a d r = ∫ a ∈ A ∫ r ∈ R r f R t + 1 ∣ S , A ( r ∣ a , S t = s ) ⋅ π ( a ∣ s ) d a d r = ∫ a ∈ A π ( a ∣ s ) E ( R t + 1 ∣ S = s , A = a ) d a \begin{align*} E[R_{t+1}|S_t=s] =& \int_{r\in R} rf_{R|S}(r|S_t=s) dr\\ =& \int_{r\in R} r\frac{f_{R,S}(r,S_t=s)}{f_S(S_t=s)}dr\\ =& \int_{r\in R} r\frac{f_{R,S}(r,S_t=s)}{f_{S,A}(S_t=s,A_t=a)}·\frac{f_{S,A}(S_t=s,A_t=a)}{f_S(S_t=s)}dr\\ =& \int_{r\in R} r\frac{f_{R,S}(r,S_t=s)}{f_{S,A}(S_t=s,A_t=a)}·f_{A|S}(a|S_t=s)dr\\ =& \int_{r\in R} r \frac{ \int_{a\in A} f_{R,S,A}(r,a,S_t=s) }{ f_{S,A}(S_t=s,A_t=a) }·f_{A|S}(a|S_t=s)dr\\ =& \int_{r\in R} r \int_{a\in A} f_{R|S,A}(r|a,S_t=s) ·f_{A|S}(a|S_t=s)dadr\\ =& \int_{a\in A}\int_{r\in R} r f_{R_{t+1}|S,A}(r|a,S_t=s) ·\pi(a|s)dadr\\ = & \int_{a\in A}\pi(a|s)E(R_{t+1}|S=s,A=a)da \end{align*} E[Rt+1∣St=s]========∫r∈RrfR∣S(r∣St=s)dr∫r∈RrfS(St=s)fR,S(r,St=s)dr∫r∈RrfS,A(St=s,At=a)fR,S(r,St=s)⋅fS(St=s)fS,A(St=s,At=a)dr∫r∈RrfS,A(St=s,At=a)fR,S(r,St=s)⋅fA∣S(a∣St=s)dr∫r∈RrfS,A(St=s,At=a)∫a∈AfR,S,A(r,a,St=s)⋅fA∣S(a∣St=s)dr∫r∈Rr∫a∈AfR∣S,A(r∣a,St=s)⋅fA∣S(a∣St=s)dadr∫a∈A∫r∈RrfRt+1∣S,A(r∣a,St=s)⋅π(a∣s)dadr∫a∈Aπ(a∣s)E(Rt+1∣S=s,A=a)da
同理
E [ G t + 1 ∣ S t = s ] = ∫ s ′ ∈ S p ( s ′ ∣ s ) E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] d s ′ = ∫ s ′ ∈ S p ( s ′ ∣ s ) E [ G t + 1 ∣ S t + 1 = s ′ ] d s ′ ( m a r k o v p r o p e r t y ) = ∫ s ′ ∈ S p ( s ′ ∣ s ) v π ( s ′ ) d s ′ = ∫ s ′ ∈ S v π ( s ′ ) ∫ a ∈ A p ( s ′ ∣ s , a ) p ( a ∣ s ) d a d s ′ = ∫ s ′ ∈ S v π ( s ′ ) ∫ a ∈ A p ( s ′ ∣ s , a ) π ( a ∣ s ) d a d s ′ \begin{align*} E[G_{t+1}|S_t = s]=&\int_{s'\in S}p(s'|s)E[G_{t+1}|S_t = s,S_{t+1}=s']ds'\\ =&\int_{s'\in S}p(s'|s)E[G_{t+1}|S_{t+1}=s'] ds'\ (markov\ property)\\ =&\int_{s'\in S}p(s'|s)v_\pi(s')ds'\\ =&\int_{s'\in S}v_\pi(s')\int_{a\in A}p(s'|s,a)p(a|s)dads'\\ =&\int_{s'\in S}v_\pi(s')\int_{a\in A}p(s'|s,a)\pi(a|s)dads' \end{align*} E[Gt+1∣St=s]=====∫s′∈Sp(s′∣s)E[Gt+1∣St=s,St+1=s′]ds′∫s′∈Sp(s′∣s)E[Gt+1∣St+1=s′]ds′ (markov property)∫s′∈Sp(s′∣s)vπ(s′)ds′∫s′∈Svπ(s′)∫a∈Ap(s′∣s,a)p(a∣s)dads′∫s′∈Svπ(s′)∫a∈Ap(s′∣s,a)π(a∣s)dads′
因此,贝尔曼公式如下
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∫ a ∈ A π ( a ∣ s ) E ( R t + 1 ∣ S = s , A = a ) + γ ∫ s ′ ∈ S v π ( s ′ ) ∫ a ∈ A p ( s ′ ∣ s , a ) π ( a ∣ s ) = ∫ a ∈ A π ( a ∣ s ) ∫ r ∈ R r f ( r ∣ s , a ) d r d a + γ ∫ a ∈ A f ( s ′ ∣ s , a ) ∫ s ′ ∈ S v π ( s ′ ) π ( a ∣ s ) d s ′ d a = ∫ a ∈ A ∫ r ∈ R π ( a ∣ s ) r f ( r ∣ s , a ) d r d a + γ ∫ a ∈ A ∫ s ′ ∈ S f ( s ′ ∣ s , a ) v π ( s ′ ) π ( a ∣ s ) d s ′ d a = ∫ a ∈ A π ( a ∣ s ) d a [ ∫ r ∈ R r f ( r ∣ s , a ) d r + γ ∫ s ′ ∈ S f ( s ′ ∣ s , a ) v π ( s ′ ) d s ′ ] = ∫ a ∈ A π ( a ∣ s ) d a [ ∫ r ∈ R ∫ s ′ ∈ S r f ( r , s ′ ∣ s , a ) d r + γ ∫ s ′ ∈ S ∫ r ∈ R f ( s ′ , r ∣ s , a ) v π ( s ′ ) d s ′ d r ] = ∫ a ∈ A π ( a ∣ s ) d a [ ∫ r ∈ R ∫ s ′ ∈ S r f ( r , s ′ ∣ s , a ) + γ f ( s ′ , r ∣ s , a ) v π ( s ′ ) d s ′ d r ] = ∫ a ∈ A π ( a ∣ s ) d a [ ∫ r ∈ R ∫ s ′ ∈ S f ( r , s ′ ∣ s , a ) [ r + γ π ( s ′ ) ] d s ′ d r ] \begin{align*} v_\pi(s)=&E[R_{t+1}|S_t=s]+\gamma E[G_{t+1}|S_t=s] \\ =&\int_{a\in A}\pi(a|s)E(R_{t+1}|S=s,A=a)+\gamma\int_{s'\in S}v_\pi(s')\int_{a\in A}p(s'|s,a)\pi(a|s)\\ =& \int_{a\in A}\pi(a|s)\int_{r\in R}rf(r|s,a)drda+\gamma\int_{a\in A}f(s'|s,a)\int_{s'\in S}v_\pi(s')\pi(a|s)ds'da\\ =& \int_{a\in A}\int_{r\in R}\pi(a|s)rf(r|s,a)drda+\gamma\int_{a\in A}\int_{s'\in S}f(s'|s,a)v_\pi(s')\pi(a|s)ds'da\\ =&\int_{a\in A} \pi(a|s)da[\int_{r\in R}rf(r|s,a)dr+\gamma \int_{s'\in S}f(s'|s,a)v_\pi(s')ds']\\ =&\int_{a\in A} \pi(a|s)da[\int_{r\in R}\int_{s'\in S}rf(r,s'|s,a)dr+\gamma \int_{s'\in S}\int_{r\in R}f(s',r|s,a)v_\pi(s')ds'dr]\\ =&\int_{a\in A} \pi(a|s)da[\int_{r\in R}\int_{s'\in S}rf(r,s'|s,a)+\gamma f(s',r|s,a)v_\pi(s')ds'dr]\\ =&\int_{a\in A} \pi(a|s)da[\int_{r\in R}\int_{s'\in S}f(r,s'|s,a)[r+\gamma \pi(s') ]ds'dr] \end{align*} vπ(s)========E[Rt+1∣St=s]+γE[Gt+1∣St=s]∫a∈Aπ(a∣s)E(Rt+1∣S=s,A=a)+γ∫s′∈Svπ(s′)∫a∈Ap(s′∣s,a)π(a∣s)∫a∈Aπ(a∣s)∫r∈Rrf(r∣s,a)drda+γ∫a∈Af(s′∣s,a)∫s′∈Svπ(s′)π(a∣s)ds′da∫a∈A∫r∈Rπ(a∣s)rf(r∣s,a)drda+γ∫a∈A∫s′∈Sf(s′∣s,a)vπ(s′)π(a∣s)ds′da∫a∈Aπ(a∣s)da[∫r∈Rrf(r∣s,a)dr+γ∫s′∈Sf(s′∣s,a)vπ(s′)ds′]∫a∈Aπ(a∣s)da[∫r∈R∫s′∈Srf(r,s′∣s,a)dr+γ∫s′∈S∫r∈Rf(s′,r∣s,a)vπ(s′)ds′dr]∫a∈Aπ(a∣s)da[∫r∈R∫s′∈Srf(r,s′∣s,a)+γf(s′,r∣s,a)vπ(s′)ds′dr]∫a∈Aπ(a∣s)da[∫r∈R∫s′∈Sf(r,s′∣s,a)[r+γπ(s′)]ds′dr]
贝尔曼公式以及python实现
r π ( s ) 代表该状态得分的期望值 r π ( s ) = ∫ a ∈ A π ( a ∣ s ) ∫ r ∈ R r f ( r ∣ s , a ) d r d a p π ( s ′ ∣ s ) 代表 s 转移到 s ‘的概率值 p π ( s ′ ∣ s ) = ∫ a ∈ A f ( s ′ ∣ s , a ) π ( a ∣ s ) r_\pi(s)代表该状态得分的期望值\\ r_\pi(s)=\int_{a\in A}\pi(a|s)\int_{r\in R}rf(r|s,a)drda\\ p_\pi(s'|s)代表s转移到s‘的概率值\\ p_\pi(s'|s)=\int_{a\in A}f(s'|s,a)\pi(a|s) rπ(s)代表该状态得分的期望值rπ(s)=∫a∈Aπ(a∣s)∫r∈Rrf(r∣s,a)drdapπ(s′∣s)代表s转移到s‘的概率值pπ(s′∣s)=∫a∈Af(s′∣s,a)π(a∣s)
v π ( s ) = ∫ a ∈ A π ( a ∣ s ) ∫ r ∈ R r f ( r ∣ s , a ) d r d a + γ ∫ a ∈ A f ( s ′ ∣ s , a ) ∫ s ′ ∈ S v π ( s ′ ) π ( a ∣ s ) d s ′ d a = r π ( s i ) + γ ∫ s ′ ∈ S v π ( s ′ ) p π ( s ′ ∣ s ) d s ′ \begin{align*} v_\pi(s) =& \int_{a\in A}\pi(a|s)\int_{r\in R}rf(r|s,a)drda+\gamma\int_{a\in A}f(s'|s,a)\int_{s'\in S}v_\pi(s')\pi(a|s)ds'da\\ =& r_π(s_i)+\gamma \int_{s'\in S}v_\pi(s') p_\pi(s'|s)ds' \end{align*} vπ(s)==∫a∈Aπ(a∣s)∫r∈Rrf(r∣s,a)drda+γ∫a∈Af(s′∣s,a)∫s′∈Svπ(s′)π(a∣s)ds′darπ(si)+γ∫s′∈Svπ(s′)pπ(s′∣s)ds′
在离散状态下,该式子表现为
v π ( s ) = ∫ a ∈ A π ( a ∣ s ) ∫ r ∈ R r f ( r ∣ s , a ) d r d a + γ ∫ a ∈ A f ( s ′ ∣ s , a ) ∫ s ′ ∈ S v π ( s ′ ) π ( a ∣ s ) d s ′ d a v π ( s i ) = r π ( s i ) + γ ∑ s j ∈ S v π ( s j ) p π ( s j ∣ s i ) \begin{align*} v_\pi(s) =& \int_{a\in A}\pi(a|s)\int_{r\in R}rf(r|s,a)drda+\gamma\int_{a\in A}f(s'|s,a)\int_{s'\in S}v_\pi(s')\pi(a|s)ds'da\\ v_\pi(s_i)=& r_π(s_i)+\gamma \sum_{s_j\in S}v_\pi(s_j) p_\pi(s_j|s_i) \end{align*} vπ(s)=vπ(si)=∫a∈Aπ(a∣s)∫r∈Rrf(r∣s,a)drda+γ∫a∈Af(s′∣s,a)∫s′∈Svπ(s′)π(a∣s)ds′darπ(si)+γsj∈S∑vπ(sj)pπ(sj∣si)
用矩阵形式表现为
v = r + γ P v v = ( 1 − γ P ) − 1 r \pmb v = \pmb r + \pmb{γP} v\\ \pmb v =(1- \pmb{γP})^{-1} \pmb{r} v=r+γPvv=(1−γP)−1r
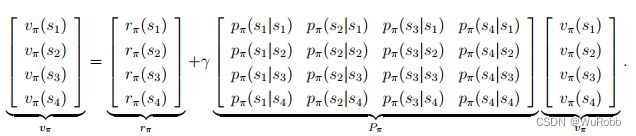
考虑以下情况

解法1——解析解
求解逆矩阵就可以获得该解
import numpy as np
## 贝尔曼公式状态值求解
def closed_form_solution(R,P,gamma):
# 获取行号
n = R.shape[0]
# 生成单位阵
I= np.identity(n)
matrix_inverse = np.linalg.inv(I-gamma*P)
# 矩阵点乘
return matrix_inverse.dot(R)
R = np.array([(0.5*0+0.5*(-1)),1.,1.,1.]).reshape(-1,1)
P = np.array([
[0,0.5,0.5,0],
[0,0,0,1],
[0,0,0,1],
[0,0,0,1],
])
closed_form_solution(R,P,0.9)
输出:
array([[ 8.5],
[10. ],
[10. ],
[10. ]])
解法2——迭代法
证明


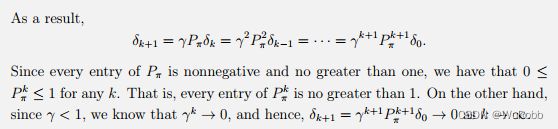
def iterative_solution(n_iter, R, P, gamma):
# n_iter 为迭代次数
# 初始化 vπ
n = R.shape[0]
v = np.random.rand(n, 1)
for iter in range(n_iter):
v = R + (gamma * P).dot(v)
return v
iterative_solution(100, R, P, 0.9)
输出:
array([[8.49974039],
[9.99974039],
[9.99974039],
[9.99974039]])
atcion value
从a状态出发的行动所带来的回报的期望,数学符号表示为
q π ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_\pi(s,a)=E[G_t|S_t=s,A_t=a] qπ(s,a)=E[Gt∣St=s,At=a]
action value 和 state value的联系,由全期望公式
E G t [ G t ∣ S t = s ] = E A t ∣ S t ( E G t [ G t ∣ ( S t = s , A t ∣ S t = a ) ] ) = ∫ a ∈ A E G t [ G t ∣ S t = s ] ⋅ π ( a ∣ s ) d a \begin{align*} E_{G_t}[G_t|S_t=s] =& E_{A_t|S_t}(E_{G_t}[G_t|(S_t=s,A_t|S_t=a)] )\\ =&\int_{a\in A}E_{G_t}[G_t|S_t=s]·\pi(a|s)da \end{align*} EGt[Gt∣St=s]==EAt∣St(EGt[Gt∣(St=s,At∣St=a)])∫a∈AEGt[Gt∣St=s]⋅π(a∣s)da
因此
v π ( s ) = ∫ a ∈ A π ( a ∣ s ) q π ( s , a ) d a \begin{align*} v_\pi(s)=&\int_{a\in A}\pi(a|s)q_\pi(s,a)da \end{align*} vπ(s)=∫a∈Aπ(a∣s)qπ(s,a)da
代表的是state value是action value的期望
因此将贝尔曼公式代入,则
q π ( s , a ) = r π ( s i ∣ a ) + γ ∫ s j ∈ S v π ( s j ) p π ( s j ∣ s i , a ) d s v π ( s ) = ∫ a ∈ A π ( a ∣ s ) [ r π ( s i ∣ a ) + γ ∫ s j ∈ S v π ( s j ) p π ( s j ∣ s i , a ) d s ] d a q_\pi(s,a)= r_π(s_i|a)+\gamma \int_{s_j\in S}v_\pi(s_j) p_\pi(s_j|s_i,a)ds\\ v_\pi(s) = \int_{a\in A}\pi(a|s)[r_π(s_i|a)+\gamma \int_{s_j\in S}v_\pi(s_j) p_\pi(s_j|s_i,a)ds]da qπ(s,a)=rπ(si∣a)+γ∫sj∈Svπ(sj)pπ(sj∣si,a)dsvπ(s)=∫a∈Aπ(a∣s)[rπ(si∣a)+γ∫sj∈Svπ(sj)pπ(sj∣si,a)ds]da
Ref
Mathematical Foundations of Reinforcement Learning,Shiyu Zhao