【论文解读】PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
PV-RCNN
- 摘要
- 引言
- 方法
-
- 3D Voxel CNN for Efficient Feature Encoding and Proposal Generation
- Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
- Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
- 实验
- 结论
摘要
我们提出了一种新的高性能3D对象检测框架,称为PointVoxel RCNN(PV-RCNN),用于从点云中精确检测3D对象。我们提出的方法深度集成了三维体素卷积神经网络(CNN)和基于PointNet的集合抽象,以学习更具判别力的点云特征。它利用了3D体素CNN的高效学习和高质量建议以及基于PointNet的网络的灵活感受野。具体而言,所提出的框架通过新颖的体素集抽象模块将具有3D体素CNN的3D场景总结为一小组关键点,以节省后续计算并对代表性场景特征进行编码。给定体素CNN生成的高质量3D提案,提出了RoIgrid池,以通过关键点集抽象将提案特定特征从关键点抽象到RoI网格点。与传统的池化操作相比,RoI网格特征点编码了更丰富的上下文信息,用于准确估计对象的置信度和位置。在KITTI数据集和Waymo Open数据集上进行的大量实验表明,我们提出的PV-RCNN以显著的优势超过了最先进的3D检测方法。
引言
我们提出了一种新的3D对象检测框架PVRCNN(如图1所示),它通过结合基于点和基于体素的特征学习方法的优点来提高3D检测性能。
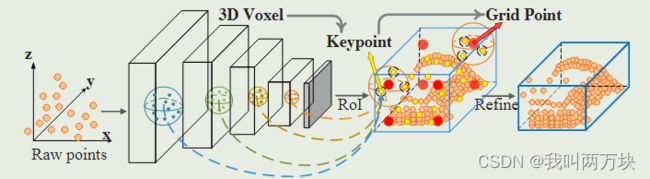
PV-RCNN的原理在于,基于体素的操作有效地编码了多尺度特征表示,并可以生成高质量的3D建议,而基于PointNet的集合抽象操作通过灵活的感受野保留了准确的位置信息。我们认为,这两种类型的特征学习框架的集成可以帮助学习更具鉴别力的特征,以实现精确的细粒度盒子细化。
主要挑战是如何将两种类型的特征学习方案,特别是具有稀疏卷积的3D体素CNN和基于PointNet的集合抽象有效地结合到一个统一的框架中。一个直观的解决方案是在每个3D提案中对几个网格点进行均匀采样,并采用集合抽象来聚合这些网格点周围的3D体素特征,以进行提案细化。然而,这种策略是高度内存密集型的,因为体素的数量和网格点的数量都可能非常大,以至于难以实现令人满意的性能。
因此,为了更好地集成这两种类型的点云特征学习网络,我们提出了一种两步策略,第一步是体素到关键点场景编码步骤,第二步是关键点到网格RoI特征提取步骤。
主要贡献:
- (1) 我们提出了PV-RCNN框架,该框架有效地利用了基于体素和基于点的3D点云特征学习方法的优势,从而在可管理的内存消耗的情况下提高了3D对象检测的性能。
- (2) 我们提出了体素到关键点场景编码方案,该方案通过体素集抽象层将整个场景的多尺度体素特征编码为一个小的关键点集。这些关键点特征不仅保持了准确的位置,而且对丰富的场景上下文进行了编码,显著提高了3D检测性能。
- (3) 我们为每个提议中的网格点提出了一个多尺度RoI特征抽象层,该层聚合了来自场景的更丰富的上下文信息,用于精确的框细化和置信度预测。
- (4) 我们提出的方法PV-RCNN以显著的优势优于以前的所有方法,在竞争激烈的KITTI 3D检测基准中排名第一,在大规模Waymo Open数据集上也以较大的优势超过了以前的方法。
方法
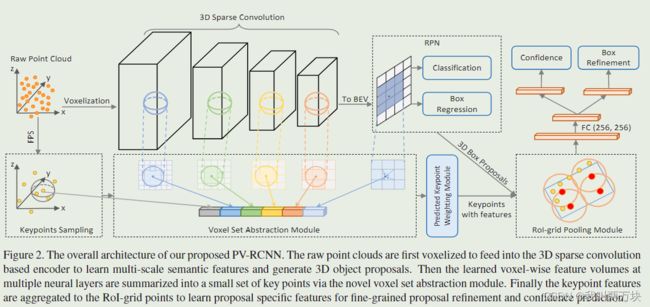
图2:我们提出的PV-RCNN的总体架构。首先对原始点云进行体素化,以馈送到基于3D稀疏卷积的编码器中,从而学习多尺度语义特征并生成3D对象建议。然后,通过新颖的体素集抽象模块,将多个神经层上学习到的体素特征量总结为一小组关键点。最后,将关键点特征聚合到RoI网格点,以学习用于细粒度提案细化和置信度预测的提案特定特征。
3D Voxel CNN for Efficient Feature Encoding and Proposal Generation
具有3D稀疏卷积的体素CNN是最先进的3D检测器的热门选择,用于有效地将点云转换为稀疏的3D特征体,由于其效率高、精度高,我们采用它作为特征编码和3D提议生成框架的主干。
3D voxel CNN
首先将输入点P划分为空间分辨率为L × W × H的小体素,其中非空体素的特征直接计算为内部所有点的逐点特征(即三维坐标、反射率强度)的平均值。该网络利用一系列3×3×3三维稀疏卷积,逐步将点云转换为下采样大小分别为1x、2x、4x、8x的特征体。这种稀疏特征体可以看作是一组体素特征向量。
3D proposal generation
通过将编码的8×downsampled 3D特征体转换为2D鸟瞰特征图,可以按照基于锚点的方法生成高质量的3D提案。具体来说,我们沿着Z轴叠加3D特征体,得到了L/8 × W/8鸟瞰特征图。每个类有2个× L/8 × W/8个3D锚盒,锚盒采用该类3D对象的平均尺寸,鸟瞰特征图的每个像素分别评估0◦、90◦两个方向的锚。
Discussions.(为下一模块做铺垫)
最先进的检测器大多采用两阶段框架。它们需要从生成的3D特征体积或2D地图中汇集RoI特定特征,以进行进一步的提案细化。然而,来自3D体素CNN的这些3D特征体积在以下方面具有主要限制。(i) 这些特征体积通常具有低空间分辨率,因为它们被下采样高达8倍,这阻碍了对象在输入场景中的精确定位。(ii)即使可以上采样以获得更大空间大小的特征体积/图,它们通常仍然相当稀疏。因此,传统的池化方法将获得大部分为零的特征,并浪费大量的计算和内存用于第二阶段的细化。
另一方面,在PointNet的变体中提出的集合抽象操作已经显示出对来自任意大小的邻域的特征点进行编码的强大能力。因此,我们建议将3D体素CNN与一系列集合抽象操作集成,以进行准确和稳健的第2阶段建议细化。
使用集合抽象操作来池化场景特征体素的一个简单解决方案是将多尺度特征体直接聚合到RoI网格。然而,由于大量的稀疏体素,这种直观的策略只是占用了大量的GPU内存来计算集合抽象中的成对距离。
为了解决这个问题,我们提出了一种分两步的方法,首先将整个场景的不同神经层的体素编码为少量关键点,然后将关键点特征聚合到RoI网格中进行框建议细化。
Voxel-to-keypoint Scene Encoding via Voxel Set Abstraction
我们的框架首先将表示整个场景的多尺度特征体素聚合为少量关键点,这些关键点充当3D体素CNN特征编码器和提案细化网络之间的桥梁。
Keypoints Sampling
具体而言,我们采用最远点采样(FPS)算法从点云P中采样少量n个关键点K={p1,···,pn},其中KITTI数据集n=2048,Waymo数据集n=4096。这种策略鼓励关键点均匀分布在非空体素周围,并且可以代表整个场景。
【FPS(Furthest Point Sampling)】是一种用于点云采样的算法。FPS 旨在从点云中选择一组代表性的点,以便在减少数据量的同时保留关键信息。FPS 的基本思想是从点云中选择一个起始点,然后在剩余的点中找到距离已选点最远的点作为下一个选定点,如此循环直到达到所需的采样数量。这确保了所选点的分布较为均匀,并且覆盖了原始点云的关键特征。
Voxel Set Abstraction Module
关键点周围的点现在是由多层三维体素CNN编码的具有多尺度语义特征的规则体素,而不是像PointNet++那样从PointNet学习特征的相邻原始点。
其中,F(lk) = {F(lk) 1,···,F(lk)Nk}为三维体素CNN的第k层体素特征向量集合,V(lk) = {V(lk) 1,···,V(lk)Nk}为它们的三维坐标,由第k层体素指数和实际体素大小计算,其中Nk为第k层非空体素的个数。
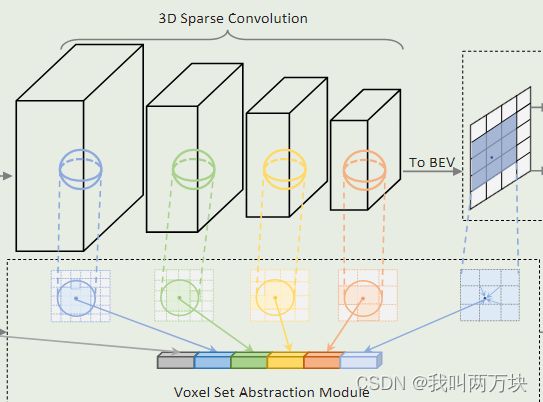
对于每个关键点pi,我们首先在半径rk内的第k层识别其相邻的非空体素,以检索体素方向的特征向量集为
- v(lk)j−pi 局部相对坐标(表示语义体素特征f (lk)j的相对位置。)
通过PointNet对pi的相邻体素集S(lk)i内的体素特征进行变换,以生成关键点pi的特征:
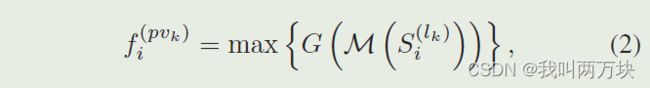
- M(·)表示从相邻集S(lk)i中随机采样最多Tk个体素以节省计算,
- G(·)代表多层感知器网络以对体素特征和相对位置进行编码
- 尽管相邻体素的数量在不同的关键点之间变化,但沿通道最大池化操作max(·)可以将不同数量的相邻体素特征向量映射到关键点pi的特征向量f(pvk)i。
上述策略是在3D体素CNN的不同级别上执行的,并且可以将来自不同级别的聚合特征连接起来,以生成关键点pi的多尺度语义特征
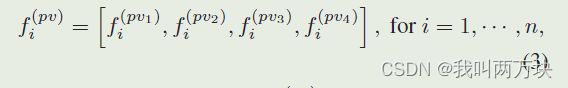
其中生成的特征f(pv)i结合了来自体素特征f(lk)j的基于3D体素CNN的特征学习和来自体素集抽象的基于PointNet的特征。此外,pi的三维坐标还保留了准确的位置信息。
Extended VSA Module
(VSA)Voxel Set Abstraction
我们通过进一步丰富原始点云P和8倍下采样鸟瞰图的关键点特征来扩展VSA模块。其中原始点云部分弥补了点云体素化的量化损失,而2D鸟瞰图沿Z轴具有更大的接受域。原始点云特征f (raw)i也按照Eq.(2)进行聚合。关键点pi的鸟瞰特征f (bev)i则通过对鸟瞰特征映射的双线性插值得到。因此,通过连接pi的所有相关特性,进一步丰富了它的关键点特性
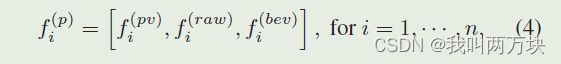
Predicted Keypoint Weighting.
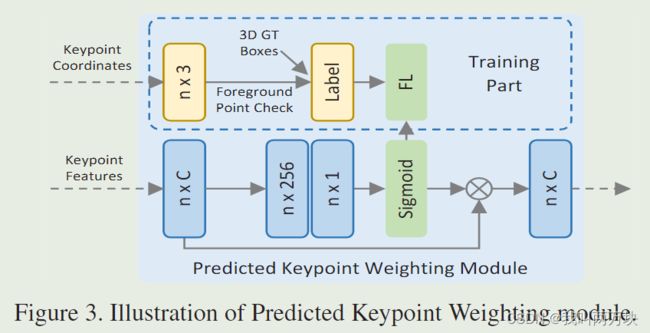
在整个场景由少量关键点编码后,它们将被后续阶段进一步用于进行提案细化。直观地说,属于前景对象的关键点应该对提案的精确细化有更大的贡献,而来自背景区域的关键点的贡献应该更小。
因此,我们提出了一个预测关键点加权(PKW)模块(见图3),通过点云分割的额外监督来重新加权关键点特征。分割标签可以由3D检测框注释直接生成,即通过检查每个关键点是在真实3D框的内部还是外部。每个关键点的特征的预测特征加权可以公式化为
![]()
- A() 表示一个具有Sigmoid函数的三层MLP网络,用于预测[0,1]之间的前景置信度。
通过focal loss来训练
Keypoint-to-grid RoI Feature Abstraction for Proposal Refinement
RoI-grid Pooling via Set Abstraction.
对于每个3D RoI,如图4所示,我们提出了RoI网格池模块,将关键点特征聚合到具有多个接受域的RoI网格点。我们在每个3D方案中统一采样6 × 6 × 6个网格点,记为G = {g1,···,g216}。采用集合抽象操作,从关键点特征中聚合网格点的特征


具体来说,我们首先识别半径为r的网格点gi的相邻关键点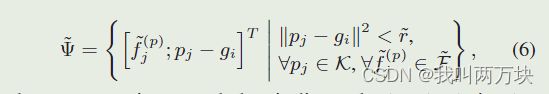
聚合相邻的关键点特征集
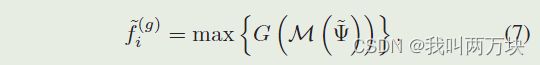
在从其周围的关键点获得每个网格的聚合特征后,可以通过具有256个特征维度的两层MLP对相同RoI的所有RoI网格特征进行矢量化和变换,以表示整个提议。
3D Proposal Refinement and Confidence Prediction.
对于第k个3D RoI,其置信度训练目标yk归一化为介于[0,1]之间的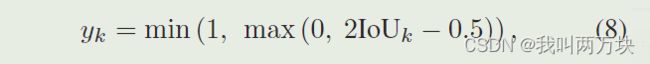
(IOU大于等于0.75时,y刚好是1,所以认为IOU达到0.75就已经很好了)
- confidence利用二值交叉熵损失来进行训练。
- bos regression利用smooth-L1损失函数进行训练
实验
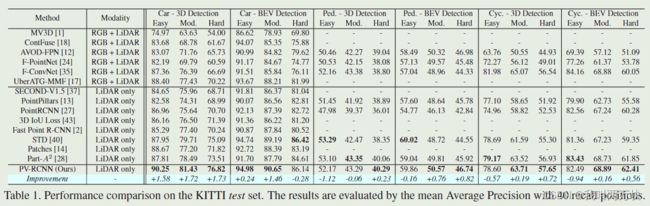
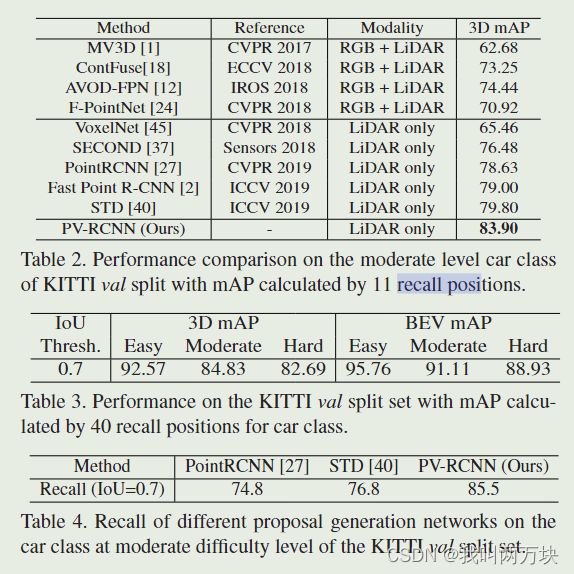
KITTI数据集


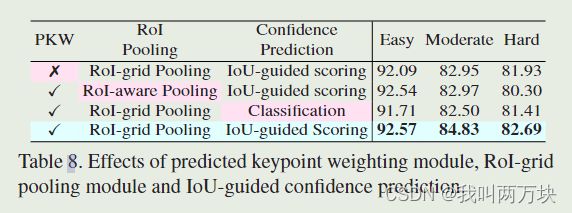
结论
我们提出了PV-RCNN框架,这是一种从点云精确检测三维目标的新方法。该方法通过提出的体素集抽象层将多尺度三维体素CNN特征和基于pointnet的特征集成到一个小的关键点集合中,然后将学习到的关键点的判别特征聚合到具有多个接受域的roi网格点中,以捕获更丰富的上下文信息,用于细粒度提案的细化。在KITTI数据集和Waymo Open数据集上的实验结果表明,我们提出的体素到关键点场景编码和关键点到网格的RoI特征抽象策略与之前最先进的方法相比,显著提高了3D目标检测性能。