微信小程序WxPrase中包含文件无法点击解决
文章目录
- 1、如何把HTML通过正则取出文件?
- 2、数据处理
- 3、界面显示和事件
这个菜鸟昨天碰见了这个问题,一开始四处搜索都没有找到解决方案,本来想换一种方式:让后端直接把文件的名字和地址传给我,我根据字段有无来显示到界面上,但是后端说要改的话比较麻烦,所以还是菜鸟来解决了!

本来找到了一个webview,感觉能解决的可能性很大,但是发现不支持个人用户,直接懵逼,后来看到这篇文章给了我思路,富文本内容中的pdf文件,如何通过wxparse点击事件打开预览?
但是这个并没有解决问题,只是给了菜鸟一个思路,既然在WxPrase里面不行,那为什么不取出来之后以附件的形式显示到页面上,虽然会有重复的感觉,但是最起码问题解决了!
1、如何把HTML通过正则取出文件?
这里菜鸟不是很熟正则,只能四处搜索,也没找到个靠谱的,然后只能在这个网站上自己摸索 在线正则表达式测试 ,上面有一个匹配URL,但是并没有什么用,最后还是菜鸟看正则,自己写出来了一个!
const reg = new RegExp('href="https://[^\\s]*?"');
这个确实可以,但发现匹配出来的地址不知道对应的文件是哪一个,后来菜鸟发现后端用富文本编译器传过来的HTML有一定规律,href后面跟着的就是title,所以代码变成这样
const reg = new RegExp('href="https://[^\\s]* title="[\\s\\S]*?"');
这个解决是解决了,但是每次只能匹配一个,然后菜鸟就想到了全局匹配,代码如下
const reg = new RegExp('href="https://[^\\s]* title="[\\s\\S]*?"',"g");
let a = reg.exec(input);
但是令人失望的是,这个全局搜索并不能正常工作。 (这里菜鸟不是很清楚为什么,希望懂的读者指点江山,激扬文字!)
当菜鸟陷入僵局的时候,后端说:既然不行,那就循环取呗,每次取了就把取出来的替换掉不就好了!所以代码变成了这样
let arr = [];
let input =test.content;
while(1){
const reg = new RegExp('href="https://[^\\s]* title="[\\s\\S]*?"');
let a = reg.exec(input);
if(a == null){
break;
}
arr.push(a);
input = input.replace(a," ");
}
console.log(arr);
然后成功取出来了,非常完美!
2、数据处理
取出来了可还不够,你还得显示到页面,那么就得对数据进行处理
let AppdList = [];
for(let i = 0;i < arr.length;i++){
let ApList = [];
// 这个是把href和title分开
let href_title = arr[i][0].split(" ");
// 有的命名不规范,就靠这个拼接回去
if(href_title.length > 2){
let title = "";
for(let j = 1;j < href_title.length;j++){
title = title + href_title[j];
}
ApList[0] = href_title[0].split("=")[1].split('"')[1];
ApList[1] = title.split("=")[1].split('"')[1];
}else{
ApList[0] = href_title[0].split("=")[1].split('"')[1];
ApList[1] = href_title[1].split("=")[1].split('"')[1];
}
AppdList.push(ApList);
// console.log(ApList);
// console.log(AppdList);
}
this.setData({
AppendicesList:AppdList,
});
注意
这里要注意一个问题,那就是字符串打印出来应该是不带引号的,带引号就表示字符串本身是带引号的,就要用 split(’"’)[1] 处理一下!
3、界面显示和事件
wxml
<view wx:if="{{show && AppendicesList.length > 0}}" class="AppendicesList box">
<view>
<text style="color: #555;" bindtap="showAppendices">收起附件:text>
view>
<block wx:for="{{AppendicesList}}">
<text class="Appendices" bindtap="downLoad" data-href="{{item[0]}}">{{item[1]}}\ntext>
block>
view>
<view wx:if="{{!show}}" class="AppendicesList">
<text class="show" bindtap="showAppendices">查看附件text>
view>
wxss
/* 添加附件 */
.AppendicesList{
/* text-align: center; */
margin-bottom: 20rpx;
}
.box{
background-color: gainsboro;
border: solid #333 5rpx;
}
.show{
text-decoration: underline;
color:#555;
}
.Appendices{
position: relative;
color: rgb(14, 122, 247);
font-size: 35rpx;
text-decoration: underline;
line-height: 60rpx;
padding-left: 30rpx;
overflow : hidden;
text-overflow: ellipsis;
display: -webkit-box;
-webkit-line-clamp: 1;
-webkit-box-orient: vertical;
word-break: break-all; /*追加这一行代码*/
}
.Appendices::before{
content: "";
position: absolute;
left: 6rpx;
top: 45%;
width: 10rpx;
height: 10rpx;
border-radius: 50%;
background-color: #333;
}
js
showAppendices:function(){
this.setData({
show:!this.data.show,
})
},
downLoad:function(e){
// console.log(e);
wx.showToast({
title: '已加入下载队列',
icon:"success",
duration:2000,
mask:true
});
// 这里也是后端的坑,当时菜鸟硬是不知道为什么访问不了,直到问了后端才知道,这个 cn// 是后端传的,但是却只能通过 cn/ 访问
let href = e.currentTarget.dataset.href.replace("cn//","cn/");
wx.downloadFile({
url: href,
success (res) {
// 只要服务器有响应数据,就会把响应内容写入文件并进入 success 回调,业务需要自行判断是否下载到了想要的内容
console.log(res);
const filePath = res.tempFilePath
wx.openDocument({
filePath: filePath,
success: function (res) {
console.log('打开文档成功');
}
})
},
fail(err){
console.log(err);
}
})
},
展示效果
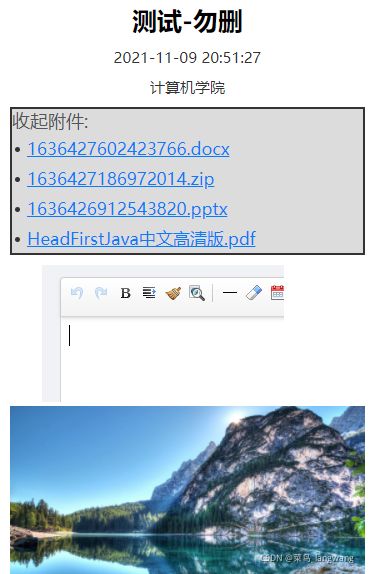

菜鸟感觉要想无重复,就要后端一起改,前端改,这个已经是极限了!