二分图带权最大匹配-KM算法详解
文章目录
-
- 零、前言
- 一、红娘再牵线
- 二、二分图带权最大完备匹配
-
- 2.1二分图带权最大匹配
- 2.2概念
- 2.3KM算法
-
- 2.3.1交错树
- 2.3.2顶标
- 2.3.3相等子图
- 2.3.4算法原理
- 2.3.5算法实现
- 三、OJ练习
-
- 3.1奔小康赚大钱
- 3.2Ants
零、前言
关于二分图:二分图及染色法判定-CSDN博客
关于二分图最大匹配:二分图最大匹配——匈牙利算法详解
一、红娘再牵线
红娘刚给上一批男女牵完线,便又遇到了3对男女(即3男3女),这次虽然比之前人少但也没那么好对付,每个男生都对若干个女生都有意思,每个女生也都对若干个男生都有意思,但是每对男女间的好感度不同,固然可以很容易配成3对情侣,但很难让每个人都满意,所以他们来请红娘出出主意。
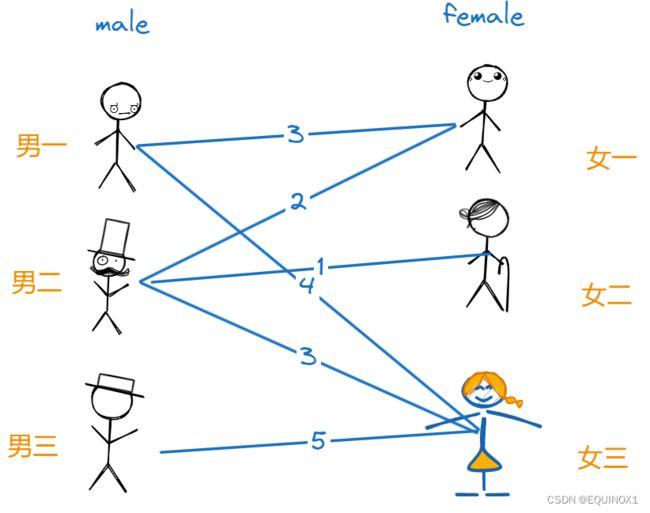
红娘了解了每对男女间的好感度后思索了一会便有了主意,她找来三个男生要求他们根据对三个女生亲密度给出对理想对象的期望值,要求给出的期望值不得小于其对任何一个女生的亲密度,女生那边则先不给出期望值。三个男生有些不好意思,便都只给出了和三个女生中的最大亲密度为期望值,于是又有了这样一张图:
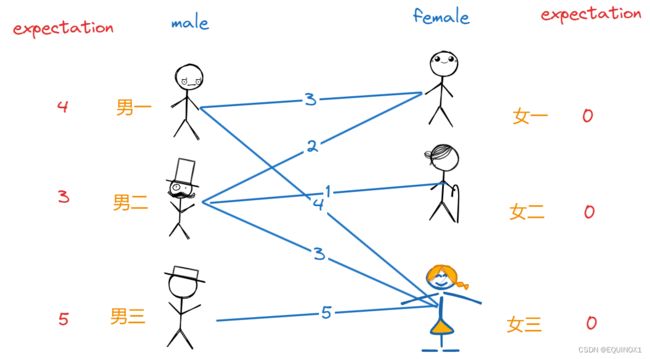
红娘打的什么算盘呢?她要让每个人都能有对象的情况下使得最终配对的情侣的亲密度之和最大,这是尽可能使每个人都满意的最好结局了。她要让最终每对情侣的期望值之和都等于其亲密值。
得到了男生们给出的期望值后,她先去给期望值之和恰好等于亲密度的男女配对(红线代表配对),男一和女三成功牵线:
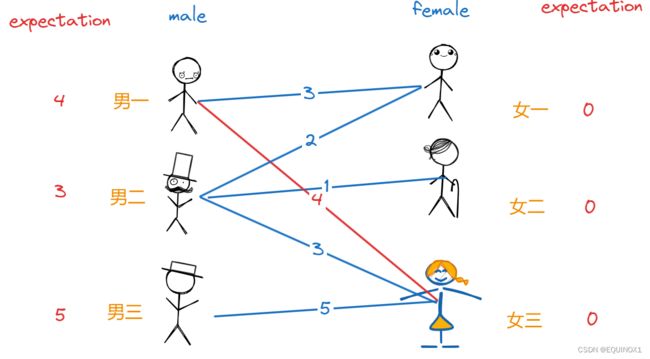
到了男二,发现符合条件的只有女三(期望值之和为亲密度),但是女三已经配对了,于是红娘让男一男二期望值都降低1,女三期望值提高1,如此一来男一女三仍符合条件,男二和女一也符合条件了,于是男儿女一牵线成功:
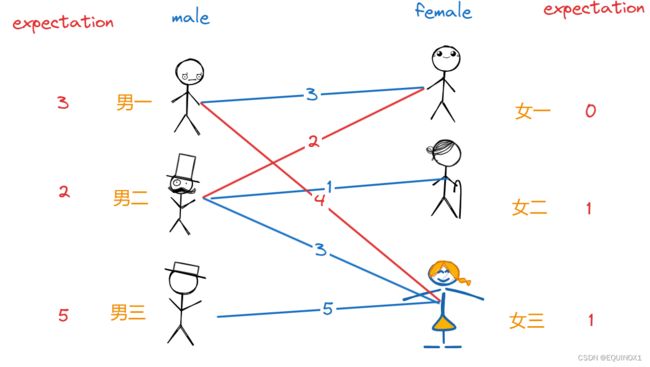
现在只剩男三落单了,对于她而言,只有女三有好感,但是二者期望值不符合条件,于是红娘先让男三降低1期望值:
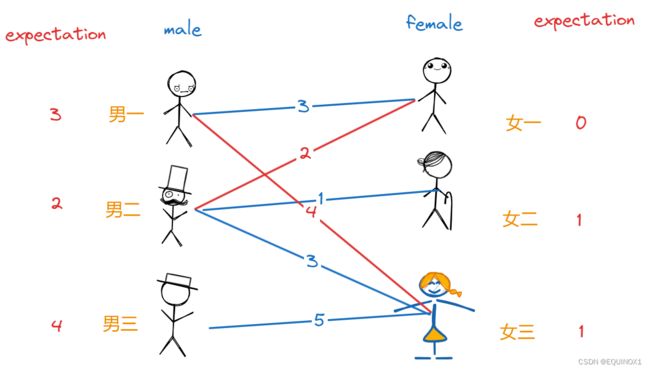
接着让男一、男二、男三都降低1期望值,女一、女三都提高1期望值,这样男一和女一符合条件可以配对,男二和女二符合条件可以配对,男三和女三符合条件可以配对:

这样一来大家都有了归宿,且配对的男女的期望值之和恰为亲密度。显然,这是大家最满意的结局。
二、二分图带权最大完备匹配
2.1二分图带权最大匹配
给定一张二分图,二分图的每条边都带有一个权值。求出该二分图的一组最大匹配,使得匹配边的权值总和最大。这个问题称为二分图的带权最大匹配,也称二分图最优匹配。注意,二分图带权最大匹配的前提是匹配数最大,然后再最大化匹配边的权值总和。
2.2概念
如果一个二分图的带权最大匹配还是一个完备匹配,那么我们称其为二分图带权最大完备匹配,如引例”红娘再牵线“就是一个二分图带权最大完备匹配的例子。
二分图带权最大完备匹配是二分图带权最大匹配的子问题,能解决二分图带权最大匹配自然能解决二分图带权最大完备匹配。
对于二分图带权最大匹配我们通用方法是费用流,其自然也可以解决二分图带权最大完备匹配,也是我们最常用的方法,当然,对于二分图带权最大完备匹配有一专门解决方法——KM算法。
2.3KM算法
KM算法是对匈牙利算法的改造,我们从匈牙利算法入手,分析如何改造得以求解二分图带权最大完备匹配问题。
2.3.1交错树
在匈牙利算法中,如果从某个左部节点出发寻找匹配失败,那么在DFS的过程中,所有访问过的节点,以及为了访问这些节点而经过的边,共同构成一棵树。
这棵树的根是一个左部节点,所有叶子节点也都是左部节点(因为最终匹配失败了),并且树上第1,3,5,… 层的边都是非匹配边,第2,4,6,…层的边都是匹配边。因此,这棵树被称为交错树。
2.3.2顶标
亦即”顶点标记值“,在二分图中,给第i(1 <= i <= n)个左部节点一个整数值la[i],给第j(1 <= j <= n)个右部节点一个整数值lb[j]。同时满足:∀i,j,la[i] + lb[j] >= w[i][j],其中w[i][j]为第i个左部节点和第j个右部节点之间的边权(没有边权时设为负无穷),这些整数值la[i]、lb[j]称为节点的顶标。
2.3.3相等子图
二分图中所有节点 和 满足la[i] + lb[j] = w[i][j]的边构成的子图,称为二分图的相等子图。
定理:
若相等子图中存在完备匹配,则这个完备匹配就是二分图的带权最大匹配。
证明十分容易:
在相等子图中,完备匹配的边权之和等于Σ(la[i] + lb[j]),即所有顶标之和。因为顶标满足Vi,j, la[i] + lb[j] ≥ w(i,j),所以在整个二分图中,任何一组匹配的边权之和都不可能大于所有顶标的和。
2.3.4算法原理
KM算法的基本思想就是,先在满足∀i,j, la[i] + lb[j] ≥ w[i][j]的前提下,给每个节点随意赋值一个顶标, 然后采取适当策略不断扩大相等子图的规模,直至相等子图存在完备匹配。例如,我们可以赋值la[i] = max(w[i][j]),lb[j] = 0
对于一个相等子图,我们用匈牙利算法求它的最大匹配。若最大匹配不完备,则说明一定有一个左部节点匹配失败。该节点匹配失败的那次DFS形成了一棵交错树,记为T。
我们要找到相等子图中的完备匹配,此时失败说明相等子图中的边没有全部包含进来,所以我们要对顶标进行调整,使得相等子图得到扩充。
对于交错树中的边无非两种:
- la[i] + lb[j] = w[i][j]的匹配边(这也是和匈牙利不同的一点),那么对于匹配边我们不需要修改顶标和,可以使得左边减少Δ,右边增加Δ
- la[i] + lb[j] > w[i][j]的非匹配边(因为顶标和不小于权值,所以只能是大于),我们通过使左部节点减小Δ来减小顶标和,从而逼近权值
那么如何取Δ呢?
令Δ为min(la[i] + lb[j] - w[i][j]),w为非匹配边,那么每次左部根节点匹配失败,进行一次调整都会使得相等子图增加至少一条边,而又不减少相等子图中的边。
2.3.5算法实现
- 初始化la,lb
- 对每个左部点进行修改后的匈牙利算法,找左部点的匹配右部点
- 匹配失败,就根据delta进行调整,再次匹配
- 对于匈牙利算法的修改:
- 只挑选顶标和为权值的边作为匹配边
- 利用顶标和大于权值的边维护delta
时间复杂度:O(N^4)
代码实现:
#define N 110
int w[N][N]; // 边权
int la[N], lb[N]; // 左、右部点顶标
bool va[N], vb[N]; // 左、右部点是否在交错树中
int match[N]; // 右部点的匹配点
int n, delta;
bool dfs(int u)
{
va[u] = true; // 在交替树中
for (int v = 1; v <= n; v++)
if (!vb[v])
if (la[u] + lb[v] - w[u][v] == 0)
{
vb[v] = true; // 进入交替树
if (!match[v] || dfs(match[v]))
{
match[v] = u;
return true; // 找到增广路
}
}
else// 维护delta,同时避免非匹配边右部点进入交替树,保证非匹配边只有左部点顶标减小
delta = min(delta, la[u] + lb[v] - w[u][v]);
return false;
}
int KM()
{
memset(match, 0, sizeof(match)), memset(lb, 0, sizeof(lb));
for (int i = 1; i <= n; i++)
{
la[i] = w[i][1];
for (int j = 2; j <= n; j++)
la[i] = max(la[i], w[i][j]);
}
for (int i = 1; i <= n; i++)
while (true) // 直到找到匹配
{
memset(va, 0, sizeof(va)), memset(vb, 0, sizeof(vb));
delta = 1 << 30; // inf
if (dfs(i))
break;
for (int j = 1; j <= n; j++) // 修改顶标,扩充相等子图
{
if (va[j])
la[j] -= delta;
if (vb[j])
lb[j] += delta;
}
}
int ans = 0;
for (int i = 1; i <= n; i++)
ans += w[match[i]][i];
return ans;
}
三、OJ练习
3.1奔小康赚大钱
Problem - 2255 (hdu.edu.cn)
很直白的KM算法板子题,直接跑板子即可
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using pii = pair;
#define sc scanf
#define N 310
#define int long long
#define precision 1e-9
int w[N][N]; // 边权
int la[N], lb[N]; // 左、右部点顶标
bool va[N], vb[N]; // 左、右部点是否在交错树中
int match[N]; // 右部点的匹配点
int n, delta;
bool dfs(int u)
{
va[u] = 1; // 在交替树中
for (int v = 1; v <= n; v++)
if (!vb[v])
if (la[u] + lb[v] - w[u][v] == 0)
{
vb[v] = 1; // 进入交替树
if (!match[v] || dfs(match[v]))
{
match[v] = u;
return true; // 找到增广路
}
}
else
delta = min(delta, la[u] + lb[v] - w[u][v]);
return false;
}
int KM()
{
memset(match, 0, sizeof(match)), memset(lb, 0, sizeof(lb));
for (int i = 1; i <= n; i++)
{
la[i] = w[i][1];
for (int j = 2; j <= n; j++)
la[i] = max(la[i], w[i][j]);
}
for (int i = 1; i <= n; i++)
while (true) // 直到找到匹配
{
memset(va, 0, sizeof(va)), memset(vb, 0, sizeof(vb));
delta = 1 << 30; // inf
if (dfs(i))
break;
for (int j = 1; j <= n; j++) // 修改顶标,扩充相等子图
{
if (va[j])
la[j] -= delta;
if (vb[j])
lb[j] += delta;
}
}
int ans = 0;
for (int i = 1; i <= n; i++)
ans += w[match[i]][i];
return ans;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
//freopen("in.txt", "r", stdin);
while (cin >> n)
{
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
cin >> w[i][j];
cout << KM() << '\n';
}
return 0;
}
3.2Ants
3565 – Ants (poj.org)
一眼看去可能觉得要用到什么计算几何的知识,实际上如图:

由三角形性质可知AD+BC > AB + CD,所以对于一对交叉的边一定可以转化为一对不交叉的边并且权值和变小
所以问题等价为求二分图带权 最小 完备匹配
那么我们把两两黑白点之间距离求出然后取反跑BMKM即可
但是对于这道题直接跑我们的板子会TLE的,因为我们最坏O(N^4)的时间复杂度在这道题刚好被卡了。
有一种比较懒省事的优化方法就是把全局的delta换成一个数组slack,来记录访问到的非匹配边的顶标和和边权之差
好处是slack只用在while循环外初始化一次然后就能用到while结束,而全局变量每次都要从inf开始
但这是个假优化,最坏仍为O(N^4)
正确优化为O(N^3)的方法是bfs优化,优化角度为从每次加入相等子图的那条边接着找增广路,这就需要我们记录上次失败时交错树的某些信息了。这里只给出slack假优化代码,bfs优化有兴趣可以查相关资料、博客,主要太懒感觉没什么用
#include
#include
#include
#include
#include
#include
using namespace std;
#define int long long
const double inf = 1e30;
const double eps = 1e-6;
const int N = 110;
int n;
pair ant[N], tree[N];
double dis(int i, int j)
{
return sqrt(1.0 * (tree[i].first - ant[j].first) * (tree[i].first - ant[j].first) + (tree[i].second - ant[j].second) * (tree[i].second - ant[j].second));
}
double la[N], lb[N], w[N][N];
bool va[N], vb[N];
int match[N];
double upd[N];
bool dfs(int u)
{
va[u] = 1; // 在交替树中
for (int v = 1; v <= n; v++)
if (!vb[v])
if (la[u] + lb[v] - w[u][v] < eps)
{
vb[v] = 1; // 进入交替树
if (!match[v] || dfs(match[v]))
{
match[v] = u;
return true; // 找到增广路
}
}
else
upd[v] = min(upd[v], la[u] + lb[v] - w[u][v]);
return false;
}
void KM()
{
memset(match, 0, sizeof(match)), memset(lb, 0, sizeof(lb));
for (int i = 1; i <= n; i++)
{
la[i] = w[i][1];
for (int j = 2; j <= n; j++)
la[i] = max(la[i], w[i][j]);
}
for (int i = 1; i <= n; i++)
{
memset(upd, 0x3f, sizeof(upd));
while (1) // 直到左部点找到匹配
{
memset(va, 0, sizeof(va)), memset(vb, 0, sizeof(vb));
for (int i = 1; i <= n; i++)
upd[i] = inf;
if (dfs(i))
break;
double delta = inf;
for (int j = 1; j <= n; j++)
if (!vb[j])
delta = min(delta, upd[j]);
for (int j = 1; j <= n; j++) // 修改顶标
{
if (va[j])
la[j] -= delta;
if (vb[j])
lb[j] += delta;
}
}
}
for (int i = 1; i <= n; i++)
cout << match[i] << '\n';
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
while (cin >> n)
{
for (int i = 1; i <= n; i++)
cin >> ant[i].first >> ant[i].second;
for (int i = 1; i <= n; i++)
cin >> tree[i].first >> tree[i].second;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
w[i][j] = -dis(i, j);
KM();
}
return 0;
}