Oracle(二)SQL子查询和常用函数
SQL子查询和常用函数
- 1. 子查询
- 2. 伪列
-
- 2.1 ROWID
- 2.2 ROWNUM
- 3. 单行函数
-
- 3.1 字符函数
- 3.2 数字函数
- 3.3 转换函数
- 3.4 日期函数
- 3.5 其他常用函数
-
- 3.5.1 NVL
- 3.5.2 NVL2
- 3.5.3 DECODE
- 3.5.4 CASE WHEN
- 3.5.5 EXISTS
- 4. 分析函数
-
- 4.1 分析函数种类和用法
-
- 4.1.1 聚合函数
- 4.1.2 排序函数
- 4.1.3 位移函数
- 4.2 行列转换
-
- 4.2.1 列转行
- 4.2.2 行转列
- 4.3 同环比
1. 子查询
子查询在 SELECT、UPDATE、DELETE 语句内部可以出现 SELECT 语句。内部的 SELECT 语句结果可以作为外部语句中条件子句的一部分,也可以作为外部查询的临时表。子查询的类型有:
- 单行子查询:不向外部返回结果,或者只返回一行结果。
- 多行子查询:向外部返回零行、一行或者多行结果。
--查询出销售部(SALES)下面的员工姓名,工作,工资
SELECT E.ENAME, E.JOB, E.SAL
FROM EMP E
WHERE E.DEPTNO = (SELECT D.DEPTNO FROM DEPT D WHERE DNAME = 'SALES');
--查询EMP表中每个部门的最低工资的员工信息
SELECT E.*
FROM EMP E
WHERE E.SAL IN (SELECT MIN(A.SAL) FROM EMP A WHERE E.DEPTNO = A.DEPTNO)
2. 伪列
在Oracle的表的使用过程中,实际表中还有一些附加的列,称为伪列。伪列就像表中的列一样,但是在表中并不存储。伪列只能查询,不能进行增删改操作。接下来学习两个伪列:ROWID和ROWNUM。
2.1 ROWID
ROWID是一个用来唯一标记表中行的伪列。它是物理表中行数据的内部地址,包含两个地址,其一为指向数据表中包含该行的块所存放数据文件的地址,另一个是可以直接定位到数据行自身的这一行在数据块中的地址。
语法结构:删除重复数据,相同数据只保留一条
DELETE FROM 表名 别名
WHERE ROWID NOT IN
(SELECT MIN(ROWID) FROM 表名 别名 GROUP BY 列名)
--删除EMP表重复数据
DELETE FROM EMP E
WHERE ROWID NOT IN
(SELECT MIN(ROWID) FROM EMP E GROUP BY EMPNO)
2.2 ROWNUM
在查询的结果集中,ROWNUM为结果集中每一行标识一个行号,第一行返回1,第二行返回2,以此类推。通过ROWNUM伪列可以限制查询结果集中返回的行数。
--查询出员工表中前5名员工的姓名,工作,工资。
SELECT ROWNUM, E.ENAME, E.JOB, E.SAL FROM EMP E WHERE ROWNUM <= 5;
在查询条件中,如果查询条件中ROWNUM大于某一正整数,则不返还任何结果。
ROWNUM与ROWID不同:
ROWID是插入记录时生成,ROWNUM是查询数据时生成。
ROWID标识的是行的物理地址,ROWNUM标识的是查询结果中的行的次序。
3. 单行函数
对每一个函数应用在表的记录中时,只能输入一行结果,返回一个结果,比如:mod(x, y)返回x除以y的余数(x和y可以是两个整数,也可以是表中的整数列)。常用的单行函数有:
- 字符函数:对字符串操作。
- 数字函数:对数字进行计算,返回一个数字。
- 转换函数:可以将一种数据类型转换为另外一种数据类型。
- 日期函数:对日期和时间进行处理。
3.1 字符函数
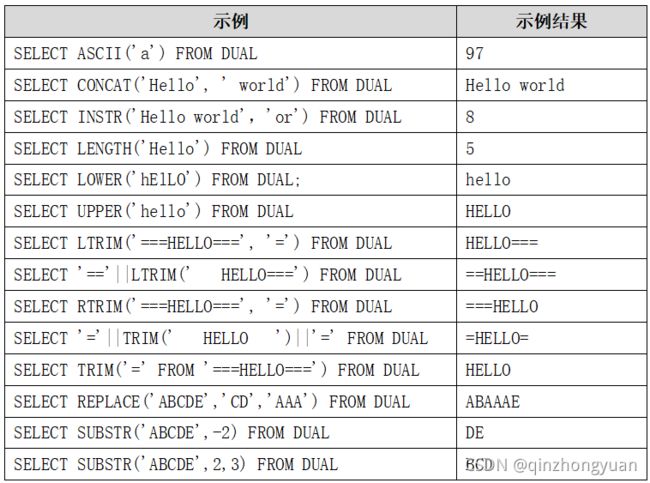
字符函数接受字符参数,这些参数可以是表中的列,也可以是一个字符串表达式。下表列出了常用的字符函数:
| 函数 | 说明 |
|---|---|
| ASCII(x) | 返回字符x的ASCII码。 |
| CONCAT(x,y) | 连接字符串x和y。 |
| INSTR(x, str [,start] [,n]) | 在x中查找str,可以指定从start开始,第n次出现。 |
| LENGTH(x) | 返回x的长度。 |
| LOWER(x) | x转换为小写。 |
| UPPER(x) | x转换为大写。 |
| LTRIM(x[,trim_str]) | 把x的左边截去trim_str字符串,缺省截去空格。 |
| RTRIM(x[,trim_str]) | 把x的右边截去trim_str字符串,缺省截去空格。 |
| TRIM([trim_str FROM] x) | 把x的两边截去trim_str字符串,缺省截去空格。 |
| REPLACE(x,old,new) | 在x中查找old,并替换为new。 |
| SUBSTR(x,start[,length]) | 返回x的字串,从start处开始,截取length个字符,缺省length,默认到结尾。 |
DUAL介绍:
dual是一张虚拟表,只有一行一列,用来构成select的语法规则。
Oracle的查询中,必须使用“select 列 ... from 表”的完整语法,当查询单行函数的时候,from后面使用 dual 表,
dual表在系统中只有一行一列,该表在输出单行函数时为了 select ... from 的语法完整性而使用。
3.2 数字函数
数字函数接受数字参数,参数可以来自表中的一列,也可以是一个数字表达式。
| 函数 | 说明 | 示例 |
|---|---|---|
| ABS(x) | x绝对值 | ABS(-3)=3 |
| MOD(x,y) | x除以y的余数 | MOD(8,3)=2 |
| POWER(x,y) | x的y次幂 | POWER(2,3)=8 |
| ROUND(x[,y]) | x在第y位四舍五入 | ROUND(3.456,2)=3.46 |
| TRUNC(x[,y]) | x在第y位截断 | TRUNC(3.456,2)=3.45 |
说明:
ROUND(X[,Y]),四舍五入。
在缺省y时,默认y=0;比如:ROUND(3.56)=4。
y是正整数,就是四舍五入到小数点后y位。ROUND(5.654,2)=5.65。
y是负整数,四舍五入到小数点左边|y|位。ROUND(351.654,-2)=400。
TRUNC(x[,y]),直接截取,不四舍五入。
在缺省y时,默认y=0;比如:TRUNC (3.56)=3。
y是正整数,就是四舍五入到小数点后y位。TRUNC (5.654,2)=5.65。
y是负整数,四舍五入到小数点左边|y|位。TRUNC (351.654,-2)=300
3.3 转换函数
转换函数将值从一种数据类型转换为另外一种数据类型。常用的转换函数有:
TO_CHAR(d|n[,fmt])
把日期和数字转换为制定格式的字符串。fmt是格式化字符串,日期的格式化字符串前面已经学习过。
--TO_CHAR对日期的处理
SELECT TO_CHAR(SYSDATE, 'YYYYMMDD') FROM DUAL;
--TO_CHAR对数字的处理
SELECT TO_CHAR(123456) FROM DUAL;
TO_DATE(x [,fmt])
把一个字符串以fmt格式转换为一个日期类型。
--TO_DATE函数
SELECT TO_DATE('20170703145533','YYYYMMDD HH24:MI:SS') FROM DUAL;
TO_NUMBER(x[,fmt])
把一个字符串以fmt格式转换为一个数字。
--TO_NUMBER函数
SELECT TO_NUMBER('123456') FROM DUAL;
3.4 日期函数
ADD_MONTHS(d,n),在某一个日期d上,加上指定的月数n,返回计算后的新日期。d表示日期,n表示要加的月数。
LAST_DAY(d),返回指定日期当月的最后一天。
ROUND(d[,fmt]),返回一个以fmt为格式的四舍五入日期值,d是日期,fmt是格式模型。默认fmt为DDD,即月中的某一天。
如果fmt为“YEAR”则舍入到某年的1月1日,即前半年舍去,后半年作为下一年。
如果fmt为“MONTH”则舍入到某月的1日,即前月舍去,后半月作为下一月。
默认为“DDD”,即月中的某一天,最靠近的天,前半天舍去,后半天作为第二天。
如果fmt为“DAY”则舍入到最近的周的周日,即上半周舍去,下半周作为下一周周日。
TRUNC(date[,fmt]),将date截取到fmt指定的形式,如果fmt省略,则截取到最近的日期。
3.5 其他常用函数
3.5.1 NVL
NVL(x,value),如果x为空,返回value,否则返回x
--对工资是2000元以下的员工,如果没有发奖金,每人奖金100元
SELECT E.ENAME, E.JOB, E.SAL, NVL(E.COMM, 100)
FROM EMP E
WHERE E.SAL < 2000;
3.5.2 NVL2
NVL2(x,value1,value2),如果x非空,返回value1,否则返回value2
--对EMP表中工资为2000元以下的员工,如果没有奖金,则奖金为200元,如果有奖金,则在原来的奖金基础上加100元。
SELECT E.ENAME, E.JOB, E.SAL, NVL2(E.COMM, E.COMM + 100, 200)
FROM EMP E
WHERE E.SAL < 2000;
3.5.3 DECODE
DECODE(列|表达式,值1,value1,值2,value2, ... , 默认值),当参数的值为判断值1,则返回value1……当参数的值匹配不到时,则返回默认值
--列出EMP员工的姓名,以及工作(中文)
SELECT E.ENAME,
DECODE(E.JOB,
'CLERK',
'业务员',
'SALESMAN',
'销售员',
'MANAGER',
'经理',
'ANALYST',
'分析员',
'PRESIDENT',
'总裁')
FROM EMP E
3.5.4 CASE WHEN
功能与DECODE相似,DECODE只用于多值判断,CASE WHEN适用于多条件判断。
语法格式:CASE WHEN语法1
CASE 参数
WHEN 判断值1 THEN 返回值1
WHEN 判断值2 THEN 返回值2
...
ELSE 默认值 END;
当参数的值为判断值1,则返回返回值1……当参数的值匹配不到时,则返回默认值
语法格式:CASE WHEN语法2
CASE
WHEN 条件1 THEN 返回值1
WHEN 条件2 THEN 返回值2
...
ELSE 默认值 END
当条件成立,则返回对应的返回值,没有条件成立则返回默认值
--列出EMP员工的姓名,以及工作(中文)
SELECT E.ENAME,
CASE E.JOB
WHEN 'CLERK' THEN
'业务员'
WHEN 'SALESMAN' THEN
'销售员'
WHEN 'MANAGER' THEN
'经理'
WHEN 'ANALYST' THEN
'分析员'
WHEN 'PRESIDENT' THEN
'总裁'
END
FROM EMP E
3.5.5 EXISTS
EXISTS(查询结果集):查询结果集有记录则成立,否则不成立
NOT EXISTS(查询结果集):与EXISTS相反
--列出有员工的部门信息
SELECT *
FROM DEPT D
WHERE EXISTS (SELECT 1 FROM EMP E WHERE D.DEPTNO = E.DEPTNO)
由于部门表中部门编号为40的记录,在EMP 表中不能找到与之对应的记录,因此EXISTS不成立,部门编号为40的部门信息就不能展示出来。
注意:
EXISTS、IN、关联必然可以相互转换。
同理NOT EXISTS、NOT IN、外关联+从表IS NULL也能相互转换
EXISTS、IN方法不会发散,但关联性能最好
4. 分析函数
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
语法格式:分析函数语法
FUNCTION_NAME(<参数>,…) OVER ( )
分析函数和聚合函数的不同之处是什么?
普通的聚合函数用group by分组,每个分组返回一个统计值,
而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。
分析函数是一个整体,不可分割。
例如:对求平均值的分析函数做空值转换:
NVL(AVG(SAL) OVER PARTITION BY DEPTNO ORDER BY 1), 0)
4.1 分析函数种类和用法
4.1.1 聚合函数
MAX,MIN,SUM,COUNT,AVG
4.1.2 排序函数
ROW_NUMBER
ROW_NUMBER函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。DENSE_RANK
DENSE_RANK函数返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的。RANK
RANK函数返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
--查询EMP表所有员工姓名,工资以部门分组降序排序
SELECT E.ENAME,
E.SAL,
ROW_NUMBER() OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) RN
FROM EMP E
输出结果如下:
ENAME SAL RN
KING 5000.00 1
CLARK 2450.00 2
MILLER 1300.00 3
SCOTT 3000.00 1
FORD 3000.00 2
JONES 2975.00 3
ADAMS 1100.00 4
SMITH 800.00 5
BLAKE 2850.00 1
ALLEN 1600.00 2
TURNER 1500.00 3
MARTIN 1250.00 4
WARD 1250.00 5
JAMES 950.00 6
4.1.3 位移函数
LAG()与LEAD():求之前或之后的第N行
LAG 和 LEAD 函数可以在一次查询中取出同一字段的前N行的数据和后N行的值。这种操作可以使用对相同表的表连接来实现,不过使用 LAG 和 LEAD 有更高的效率。
LAG(ARG1,ARG2,ARG3)第一个参数是列名,第二个参数是偏移的offset,第三个参数是超出记录窗口时的默认值。
--比较EMP表中员工与上一个入职员工晚入职多久
SELECT E.ENAME,
E.HIREDATE - LAG(E.HIREDATE, 1) OVER(ORDER BY E.HIREDATE ASC)
FROM EMP E
4.2 行列转换
4.2.1 列转行
【例】有一张表S,记录了某公司每个月的销售额,如下
Y Q AMT
2015 1 100
2015 2 110
2015 3 130
2015 4 100
2016 1 200
2016 2 150
2016 3 100
2016 4 300
- 用分析函数lead/lag
SELECT S.Y, S.AMT Q1, S.LD1 Q2, S.LD2 Q3, S.LD3 Q4
FROM (SELECT S.*,
LEAD(S.AMT, 1) OVER(PARTITION BY S.Y ORDER BY S.Q) LD1,
LEAD(S.AMT, 2) OVER(PARTITION BY S.Y ORDER BY S.Q) LD2,
LEAD(S.AMT, 3) OVER(PARTITION BY S.Y ORDER BY S.Q) LD3
FROM S) S
WHERE S.Q = 1
- 用DECODE
SELECT S.Y,
SUM(DECODE(S.Q, 1, AMT, NULL)) Q1,
SUM(DECODE(S.Q, 2, AMT, NULL)) Q2,
SUM(DECODE(S.Q, 3, AMT, NULL)) Q3,
SUM(DECODE(S.Q, 4, AMT, NULL)) Q4
FROM S
GROUP BY S.Y
注意:NULL值不参于任何计算
- 部分关联
SELECT S.Y, S.AMT Q1, A.AMT Q2, B.AMT Q3, C.AMT Q4
FROM S,
(SELECT * FROM S WHERE S.Q = 2) A,
(SELECT * FROM S WHERE S.Q = 3) B,
(SELECT * FROM S WHERE S.Q = 4) C
WHERE S.Y = A.Y
AND S.Y = B.Y
AND S.Y = C.Y
AND S.Q=1
4.2.2 行转列
WITH A AS
(SELECT S.Y,
SUM(DECODE(S.Q, 1, AMT, NULL)) Q1,
SUM(DECODE(S.Q, 2, AMT, NULL)) Q2,
SUM(DECODE(S.Q, 3, AMT, NULL)) Q3,
SUM(DECODE(S.Q, 4, AMT, NULL)) Q4
FROM S
GROUP BY S.Y) --将结果集命名为A,把A行转列
SELECT A.Y, 1, A.Q1
FROM A
UNION ALL
SELECT A.Y, 2, A.Q2
FROM A
UNION ALL
SELECT A.Y, 3, A.Q3
FROM A
UNION ALL
SELECT A.Y, 4, A.Q4 FROM A
4.3 同环比
环比=(现阶段-同一周期上一阶段)/同一周期上一阶段
同比=(现阶段-上一周期相同阶段)/上一周期相同阶段