Debezium发布历史64
原文地址: https://debezium.io/blog/2019/07/12/streaming-cassandra-at-wepay-part-1/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
在 WePay 上流式传输 Cassandra - 第 1 部分
七月 12, 2019 作者: Joy 高
卡桑德拉
这篇文章最初出现在WePay Engineering 博客上。
从历史上看,MySQL 一直是 WePay 微服务选择的事实上的数据库。随着 WePay 的扩展,写入我们一些微服务数据库的大量数据要求我们在分片 MySQL(即Vitess)和切换到本机分片 NoSQL 数据库之间做出扩展决策。经过一系列评估,我们选择了 Cassandra 这个 NoSQL 数据库,主要是因为它的高可用性、水平可扩展性以及处理高写入吞吐量的能力。
批量 ETL 选项
将 Cassandra 引入我们的基础设施后,我们的下一个挑战是找到一种方法将 Cassandra 中的数据公开给我们的数据仓库BigQuery,以进行分析和报告。我们快速构建了一个 Airflow hook和操作符来执行满载。这显然无法扩展,因为它会在每次加载时重写整个数据库。为了扩展管道,我们评估了两种增量加载方法,但两者都有其缺点:
范围查询。这是一种常见的 ETL 方法,其中通过范围查询定期(例如每小时或每天)提取数据。任何熟悉Cassandra 数据建模的人都会很快意识到这种方法是多么不切实际。Cassandra 表需要建模以优化生产中使用的查询模式。在大多数情况下,添加此查询模式进行分析意味着使用不同的集群键克隆表。RDBMS 人员可能会建议二级索引来支持这种查询模式,但Cassandra 中的二级索引是本地的,因此这种方法本身会带来性能和扩展问题。
处理未合并的 SSTable。SSTables 是 Cassandra 的不可变存储文件。Cassandra 提供了sstabledump CLI 命令,可将 SSTable 内容转换为人类可读的 JSON。然而,Cassandra 是建立在日志结构合并 (LSM) 树概念之上的,这意味着 SSTable 会定期合并到新的压缩文件中。根据压缩策略,在带外检测未合并的 SSTable 文件可能具有挑战性(我们后来了解了Cassandra 中的增量备份功能,该功能仅备份未压缩的 SSTable;因此这种方法也能发挥作用。)
考虑到这些挑战,在为 MySQL构建和运营流数据管道后,我们开始探索 Cassandra 的流选项。
流媒体选项
双写
图片来自于官网原文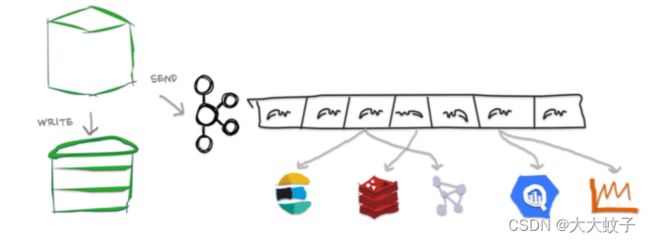
显示作者发送两个不同写入的图像
这个想法是每次在 Cassandra 上执行写入操作时都会发布到 Kafka。这种双重写入可以通过内置触发器或客户端周围的自定义包装器来执行。这种方法存在性能问题。首先,由于我们现在需要写入两个系统而不是一个系统,因此写入延迟增加了。更重要的是,当对一个系统的写入由于超时而失败时,写入是否成功是不确定的。为了保证两个系统上的数据一致性,我们必须实现分布式事务,但多次往返共识会增加延迟并进一步降低吞吐量。这违背了高写入吞吐量数据库的目的。
Kafka 作为事件源
图片来自于官网原文
该图显示写入发送到 Kafka,然后发送到下游数据库
这个想法是写给 Kafka,而不是直接写给 Cassandra;然后通过消费来自 Kafka 的事件将写入应用到 Cassandra。事件溯源是当今非常流行的方法。但是,如果您已有直接写入 Cassandra 的现有服务,则需要更改应用程序代码并进行重要的迁移。这种方法还违反了读你所写的一致性:如果一个进程执行写入,则执行后续读取的同一进程必须观察写入的效果。由于写入是通过 Kafka 路由的,因此发出写入和应用写入之间会存在延迟;在此期间,读取 Cassandra 将导致数据过时。这可能会导致不可预见的生产问题。
解析提交日志
图片来自于官网原文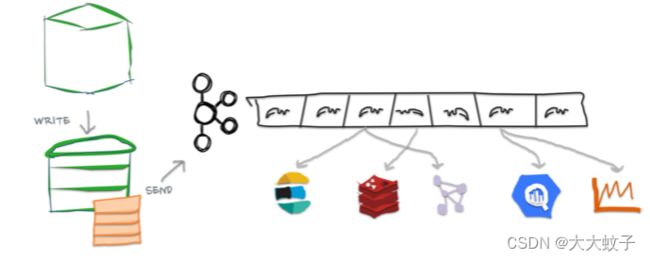
显示发送到 Kafka 的提交日志的图像
Cassandra 在 3.0 中引入了变更数据捕获 (CDC) 功能来公开其提交日志。提交日志是 Cassandra 中的预写日志,旨在在机器崩溃时提供持久性。它们通常在冲洗时被丢弃。启用 CDC 后,它们会在刷新时传输到本地 CDC 目录,然后可由 Cassandra 节点上的其他进程读取。这允许我们使用与 MySQL 流管道中相同的 CDC 机制。它将生产运营与分析分离,因此不需要应用工程师进行额外的工作。
最终,在考虑了吞吐量、一致性和关注点分离之后,最后一个选项——解析提交日志——成为了最有力的竞争者。
提交日志深入探讨
除了公开提交日志之外,Cassandra 还提供了CommitLogReader和CommitLogReadHandler类来帮助进行日志的反序列化。看来艰苦的工作已经完成,剩下的就是应用转换——将反序列化表示转换为 Avro 记录并将其发布到 Kafka。然而,当我们进一步深入研究 CDC 功能和 Cassandra 本身的实现时,我们意识到存在许多新的挑战。
延迟处理
提交日志仅在 CDC 目录已满时到达,在这种情况下,它将被刷新/丢弃。这意味着记录事件和捕获事件之间存在延迟。如果执行很少或不执行写入,则事件捕获的延迟可能会任意长。
空间管理
在MySQL中,您可以设置binlog保留,以便在配置的保留期限后自动删除日志。然而在 Cassandra 中没有这样的选项。一旦提交日志传输到CDC目录,处理后必须进行消费以清理提交日志。如果 CDC 目录的可用磁盘空间超过给定阈值,则对数据库的进一步写入将被拒绝。
重复的事件
单个 Cassandra 节点上的提交日志并不反映对集群的所有写入;它们仅反映对节点的写入。这使得有必要在所有节点上处理提交日志。但如果复制因子为 N,则每个事件的 N 个副本会发送到下游。
无序事件
对单个 Cassandra 节点的写入在到达时会被连续记录。但是,这些事件从发出时起可能会无序到达。这些事件的下游使用者必须了解事件时间并实现类似于Cassandra 读取路径的最后写入获胜逻辑,才能获得正确的结果。
带外架构更改
表的架构更改通过八卦协议进行通信,并且不会记录在提交日志中。因此,只能尽力检测架构中的更改。
行数据不完整
Cassandra 不会执行先读后写的操作,因此更改事件不会捕获每个列的状态,它们仅捕获已修改列的状态。这使得更改事件不如整行可用时有用。
一旦我们深入了解 Cassandra 提交日志,我们就会根据给定的约束重新评估我们的要求,以设计最小可行的基础设施。
最低限度可行的基础设施
借鉴最小可行产品理念,我们希望设计一个具有最少功能和要求的数据管道,以满足我们的直接客户的需求。对于 Cassandra CDC,这意味着:
引入 CDC 不应对生产数据库的健康状况和性能产生负面影响;运营放缓和系统停机比分析管道延迟的成本要高得多
查询数据仓库中的 Cassandra 表应该与查询生产数据库的结果相匹配(排除延迟);具有重复和/或不完整的行会增加每个最终用户的后处理工作量有了这些标准,我们开始集思广益寻找解决方案,并最终提出了三种方法:
无状态流处理
该解决方案的灵感来自 Datastax 的高级复制博客文章. The idea is to deploy an agent on each Cassandra node to process local commit logs. Each agent is considered as “primary” for a subset of writes based on partition keys, such that every event has exactly one primary agent. Then during CDC, in order to avoid duplicate events, each agent only sends an event to Kafka if it is the primary agent for the event. To handle eventual consistency, each agent would sort events into per-table time-sliced windows as they arrive (but doesn’t publish them right away); when a window expires, events in that window are hashed, and the hash is compared against other nodes. If they don’t match, data is fetched from the inconsistent node so the correct value could be resolved by last write wins. Finally the corrected events in that window will be sent to Kafka. Any out-of-order event beyond the time-sliced windows would have to be logged into an out-of-sequence file and handled separately. Since deduplication and ordering are done in-memory, concerns with agent failover causing data loss, OOM issues impacting production database, and the overall complexity of this implementation stopped us from exploring it further.
有状态流处理
该解决方案功能最丰富。这个想法是,每个 Cassandra 节点上的代理将处理提交日志并将事件发布到 Kafka,而无需重复数据删除和排序。然后,流处理引擎将消耗这些原始事件并完成繁重的工作(例如使用缓存过滤掉重复事件,使用事件时间窗口管理事件顺序,以及通过在状态存储上执行先读后写来捕获未修改列的状态) ),然后将这些派生事件发布到单独的 Kafka 主题。最后,KCBQ将用于使用本主题中的事件并将其上传到 BigQuery。这种方法很有吸引力,因为它一般性地解决了问题——任何人都可以订阅后一个 Kafka 主题,而无需自己处理重复数据删除和排序。然而,这种方法会带来大量的运营开销;我们必须维护一个流处理引擎、一个数据库和一个缓存。
读取时处理
与之前的方法类似,其想法是处理每个 Cassandra 节点上的提交日志并将事件发送到 Kafka,无需重复数据删除和排序。与之前的方法不同,流处理部分被完全消除。相反,原始事件将通过 KCBQ 直接上传到 BigQuery。视图是在原始表之上创建的,用于处理重复数据删除、排序和合并列以形成完整的行。由于 BigQuery 视图是虚拟表,因此每次查询视图时都会延迟处理。为了防止视图查询变得过于昂贵,视图将定期具体化。此方法利用 BigQuery 的大规模并行查询引擎,消除了操作复杂性和代码复杂性。然而,缺点是非 KCBQ 下游消费者必须自己完成所有工作。
鉴于我们流式传输 Cassandra 的主要目的是数据仓库,我们最终决定实现读时处理。它为我们现有的用例提供了基本功能,并提供了将来扩展到上述其他两个更通用的解决方案的灵活性。
开源
在为 Cassandra 构建实时数据管道的过程中,我们收到了对该项目的大量兴趣。因此,我们决定在Debezium 的保护伞下开源 Cassandra CDC 代理作为孵化连接器。如果您想了解更多信息或做出贡献,请查看正在进行的源代码和文档的拉取请求。
在本博客文章系列的后半部分中,我们将更详细地阐述 CDC 实现本身。敬请关注!