kafka基本使用及结合Java使用
一、Kafka介绍
Kafka是一个分布式、支持分区、多副本的消息系统,最大特点是实时处理大量数据以满足各种需求场景。它可以用于日志收集、消息系统、用户活动跟踪、运营指标等。Kafka是用Scala语言编写的,于2010年贡献给了Apache基金会并成为顶级开源项目。
1.Kafka的使用场景
- 实时数据流处理:Kafka可以接收和传递实时数据,使得数据可以在各种系统或应用之间进行实时通信。
- 日志收集:Kafka可以用于收集各种服务的日志,使得这些日志可以集中存储和分析。
- 事件驱动架构:通过将事件发布到Kafka主题,可以触发各种事件处理程序,构建事件驱动的系统。
- 缓存数据:Kafka可以作为缓存数据的存储,提供高吞吐量的读取服务。
- 数据管道:Kafka可以用于将数据从一个系统传输到另一个系统,实现数据同步和集成。
由于Kafka的高吞吐量、可扩展、可靠和分布式等特点,它在很多大型的互联网应用中得到广泛的应用。
2.Kafka基本概念
Kafka是一个分布式的、分区的消息服务,提供了消息系统应该具备的功能。它借鉴了JMS规范的思想,但是并没有完全遵循JMS规范。JMS是一种类似于JDBC对于数据库的,对于Java调用消息队列的接口规范。
Kafka主要用于处理实时数据流,提供高吞吐量、可扩展、可靠和分布式的数据处理能力。
首先,让我们来看一下基础的消息(Message)相关术语:
- 主题(Topic):Kafka将消息分为不同的主题。每个主题都是消息的分类,消息发布到特定的主题。
- 生产者(Producer):生产者负责将消息发送到Kafka。它可以将消息发送到任何可用的Kafka代理,并使用特定的主题。
- 代理(Broker):消息中间件处理节点,⼀个Kafka节点就是⼀个broker。代理是Kafka服务的核心,它们提供对Kafka集群的接口。Kafka集群由一个或多个代理组成。
- 消费者(Consumer):消费者从Kafka中读取消息。它可以订阅一个或多个主题,并按照订阅的顺序处理消息。
- 分区(Partition):为了实现可扩展性和容错性,Kafka将每个主题分为多个分区。每个分区都是一个独立的消息队列,消息按照它们到达的时间顺序存储。
- 副本(Replica):Kafka提供副本机制来保证数据的安全性。每个分区都有一定数量的副本,分布在不同的代理上。
- 消费者组(ConsumerGroup):每个Consumer属于⼀个特定的Consumer Group,⼀条消息可以被多个不同的Consumer Group消费,但是⼀个Consumer Group中只能有⼀个Consumer能够消费该消息。
因此,从一个较高的层面上来看,producer通过网络发送消息到Kafka集群,然后consumer 来进行消费,如下图:
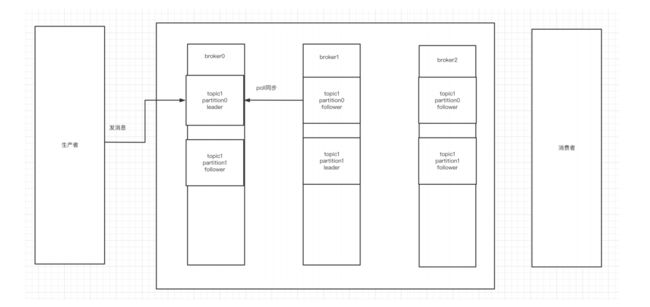
服务端(brokers)和客户端(producer、consumer)之间通信通过 TCP协议 来完成。
二、kafka基本使用
点击查看官方文档
1.安装
- 安装jdk
- 安装zk
ZooKeeper主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。 使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了。
在云服务器上使用docker安装Kafka:
确保使用"free -h"命令, 确保剩余内存空间至少有600MB, 让自己的系统只保留redis和mysql服务, 其他的全部关闭
安装zookeeper
docker run --name some-zookeeper -dit -p 2181:2181 zookeeper
将云服务器中的2181端口放开 稍微等待15s等待 zookeeper彻底启动成功
将云服务器中的9092端口放开
安装kafka
docker run -d --name=kafka2 \
-p 9092:9092 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=服务器IP地址:2181 \
-e KAFKA_BROKER_ID=2 \
-e KAFKA_NODE_ID=2 \
-e KAFKA_ENABLE_KRAFT=false \
-e KAFKA_HEAP_OPTS="-Xmx180m -Xms180m" \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-e BITNAMI_DEBUG=true \
bitnami/kafka
docker ps查看kafka和zookeeper容器,是否成功启动

重新安装kafka的时候, 先docker rm删除掉kafka和zookeeper容器, 然后重新安装一下zookeeper容器
docker rm -f kafka2 some-zookeeper
注意: 命令的末尾千万不要携带 /bin/bash 否则会引起kafka容器无法启动
参数释义:
- e KAFKA_BROKER_ID=2 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
- e KAFKA_CFG_ZOOKEEPER_CONNECT=服务器IP地址:12181 kafka 配置zookeeper的连接地址
- e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9092 把kafka的地址端口注册给zookeeper
- e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口 (是容器内部的端口)
- e KAFKA_HEAP_OPTS=“-Xmx180m -Xms180m” 设置kafka占用的内存
2.创建主题topic
topic是什么概念?topic可以实现消息的分类,不同消费者订阅不同的topic。

执行以下命令创建名为“test”的topic,这个topic只有一个partition,并且备份因子也设置为1
先进入到kafka2容器系统中
docker exec -it kafka2 /bin/bash
kafka的安装目录位于/opt/bitnami/kafka
cd /opt/bitnami/kafka/bin
cd bin
创建topic
./kafka-topics.sh --create --topic test --bootstrap-server 服务器IP地址:9093 --replication-factor 1 --partitions 1
查看当前kafka内有哪些topic
./kafka-topics.sh --bootstrap-server 服务器IP地址:9093 --list
3.发送消息
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。使用kafka的发送消息的客户端,指定发送到的kafka服务器地址的topic中
./kafka-console-producer.sh --broker-list 服务器IP地址:9093 --topic test
4.消费消息
对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输 出, 默认是消费最新的消息 。使用kafka的消费者消息的客户端,从指定kafka服务器的指定 topic中消费消息
方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --topic test
方式二:从头开始消费:“--from-beginning”
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --from-beginning --topic test
几个注意点:
- 消息会被存储
- 消息是顺序存储
- 消息是有偏移量的
- 消费时可以指明偏移量进行消费
三、Kafka中的关键细节
1.消息的顺序存储
消息的发送方会把消息发送到broker中,broker会存储消息,消息是按照发送的顺序进行存储。因此消费者在消费消息时可以指明主题中消息的偏移量。默认情况下,是从最后一个消息的下一个偏移量开始消费。
一个broker相当于是一个节点 -> 一个kafka容器就是一个broker
读取和写入的顺序都是先进先出
2. 单播消息的实现
单播消息:一个消费组里 只会有一个消费者能消费到某一个topic中的消息。于是可以创建多个消费者,这些消费者在同一个消费组中。
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --consumer-property group.id=testGroup --topic test
3.多播消息的实现
在一些业务场景中需要让一条消息被多个消费者消费,那么就可以使用多播模式 。
kafka实现多播,只需要让不同的消费者处于不同的消费组即可。
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9093 --consumer-property group.id=testGroup2 --topic test
4.查看消费组及信息
# 查看当broker下有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server 服务器IP地址:9093 --list
# 查看当前topic 中的 消费组中的具体信息:比如当前偏移量、最后一条消息的偏移量、堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server 服务器IP地址:9093 --describe --group testGroup1
- Currennt-offset: 当前消费组的已消费偏移量 * Log-end-offset: 主题对应分区消息的结束偏移量(HW) * Lag: 当前消费组未消费的消息数
运行结果:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testGroup1 test 0 12 12 0 console-consumer-e8490316-aa97-40ff-8e7b-36e8c68e9a6e /81.70.199.213 console-consumer
四、主题、分区的概念
1.主题Topic
主题Topic可以理解成是一个类别的名称。
2.partition分区
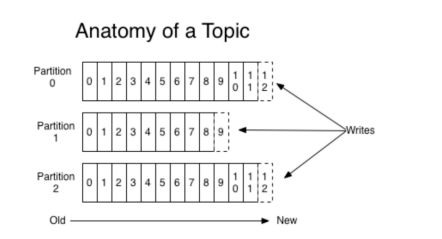
一个主题中的消息量是非常大的,因此可以通过分区的设置,来分布式(集群)存储这些消息。比如一个topic创建了 3 个分区。那么topic中的消息就会分别存放在这三个分区中。
为一个主题创建多个分区
./kafka-topics.sh --create --topic test1 --bootstrap-server 服务器IP地址:9093 --replication-factor 1 --partitions 2
可以通过这样的命令查看topic的分区信息
./kafka-topics.sh --bootstrap-server 服务器IP地址:9093 --topic test1 --describe
test的结果
##结果
Topic: test1 TopicId: UBg9xwGhSKyaeWV-RdiNcQ PartitionCount: 2 ReplicationFactor: 1 Configs:
Topic: test1 Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2 Isr: 2
通过查看topic信息,其中的关键数据:
- replicas:当前副本存在的broker节点
- leader:副本里的概念
- 每个partition都有一个broker作为leader。
- 消息发送方要把消息发给哪个broker?就看副本的leader是在哪个broker上面。副本里的leader专⻔用来接收消息。
- 接收到消息,其他follower通过poll的方式来同步数据。
isr: 可以同步的broker节点和已同步的broker节点,存放在isr集合中。
分区的作用:
- 可以分布式存储
- 可以并行写
- producer向3个分区写入消息,consumer从3个分区拉取消息。分区内的消息通过
offset保证连续,但分区之间的消息顺序无法保证。
kafka集群创建topic中的分区和副本选择基本概念
7个broker组成的集群, 创建一个topic, 设置7个分区是最优选择, 如果选择5个分区, 也是可以的, 但是两台机器没有起到作用; 如果选择10个分区, 也是可以的, 但是会有三台机器会做双份工作, 有两个leader
设置7个副本是最优选择, 如果选择5个副本, 也是可以的, 但是又两台机器没有起到备份作用; 如果选择10个副本呢? 是不可以的, 创建逻辑上就存在问题
默认情况下,kafka 会使用三种方式来自动创建主题,下面是三种情况:
-
当一个生产者开始往主题写入消息时
-
当一个消费者开始从主题读取消息时
-
当任意一个客户端向主题发送元数据请求时
五、Kafka集群及副本的概念
1.搭建kafka集群, 2个broker
broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
使用如下命令来启动 2 台服务器
注意: 此kafka的安装依赖于zookeeper的安装,如果之前有安装过zookeeper, 不要重复使用, 重新创建新的zookeeper
前面安装过的zookeeper和kafka两个容器, 请删除掉, 重新创建zookeeper
安装zk
docker run --name some-zookeeper -dit -p 2181:2181 zookeeper
确保安装完成集群后, 至少还有800mb的剩余空间
注意: 两个kafka一个占用9092, 一个占用9093, 确保云服务防火墙中的两个端口都是放开的, 先开放防火墙
#节点1
docker run -d --name=kafka2 \
-p 9092:9092 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=服务器IP地址:2181 \
-e KAFKA_BROKER_ID=2 \
-e KAFKA_NODE_ID=2 \
-e KAFKA_ENABLE_KRAFT=false \
-e KAFKA_HEAP_OPTS="-Xmx180m -Xms180m" \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
bitnami/kafka
# 节点2
docker run -d --name=kafka3 \
-p 9093:9092 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=服务器IP地址:2181 \
-e KAFKA_BROKER_ID=3 \
-e KAFKA_NODE_ID=3 \
-e KAFKA_ENABLE_KRAFT=false \
-e KAFKA_HEAP_OPTS="-Xmx180m -Xms180m" \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9093 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
bitnami/kafka
参数释义:
- e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
- e KAFKA_ZOOKEEPER_CONNECT=服务器IP地址:2181 kafka 配置zookeeper
- e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器IP地址:9092 把kafka的地址端口注册给zookeeper
- e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口 是容器内部kafka占用的端口
- e KAFKA_HEAP_OPTS=“-Xmx180m -Xms180m” 设置kafka占用的内存
2.副本的概念
副本是对分区的备份。在集群中,不同的副本会被部署在不同的broker上。下面例子:创建 1个主题, 2 个分区、 2 个副本。
进入到kafka2容器中, 进入到bin目录下, 执行如下命令
./kafka-topics.sh --create --topic my-replicated-topic --bootstrap-server 服务器IP地址:9092 --replication-factor 2 --partitions 2
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 --topic my-replicated-topic --describe
Topic: my-replicated-topic TopicId: eJ0M58k5RR6MwImWeHBebQ PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2
Topic: my-replicated-topic Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
通过查看topic信息,其中的关键数据:
- replicas:当前副本存在的broker节点
- leader:副本里的概念
- 每个partition都有一个broker作为leader。
- 消息发送方要把消息发给哪个broker?就看副本的leader是在哪个broker上面。副本里的leader专⻔用来接收消息。
- 接收到消息,其他follower通过poll的方式来同步数据。
isr: 可以同步的broker节点和已同步的broker节点,存放在isr集合中。
通过kill掉leader后再查看主题情况
# kill掉leader
docker stop kafka3
# 查看topic情况
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 --topic my-replicated-topic --describe
运行结果:
Topic: my-replicated-topic TopicId: x61TtWHyTzCg1XlAcOQQ5w PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 3,2 Isr: 2
Topic: my-replicated-topic Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2
删除topic命令
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 --delete --topic my-replicated-topic
查看当前topic有哪些
./kafka-topics.sh --bootstrap-server 服务器IP地址:9092 -list
3.broker、主题、分区、副本
- kafka集群中由多个broker组成
- 一个broker中存放一个topic的不同partition——副本
注意: 副本的数量不能超过集群节点的数量
向集群中的某个topic发送数据, 集群会首先计算出来这条数据归哪个patition存储, 确定了patition后, 存储到这个分区对应的leader中,随后,其他副本节点会将这条新的数据同步到自己的kafka副本中, 下面这张图演示的是, 3个broker, 一个topic1, topic1有2个分区, 3个副本
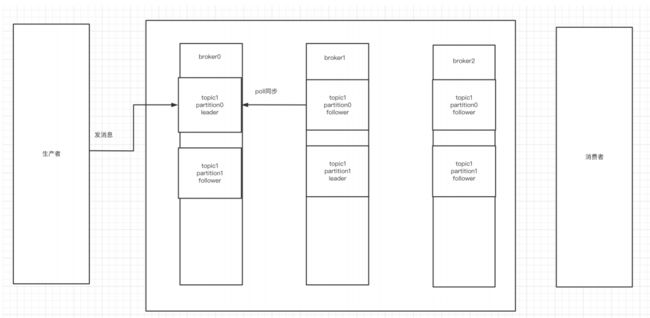
4.kafka集群消息的发送
注意: 刚刚演示的kafka3被关闭了, 启动一下
创建topic
./kafka-topics.sh --create --topic my-replicated-topic --bootstrap-server 服务器IP地址:9092 --replication-factor 2 --partitions 2
发送数据
./kafka-console-producer.sh --broker-list 服务器IP地址:9092,服务器IP地址:9093 --topic my-replicated-topic
5.kafka集群消息的消费
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9092,服务器IP地址:9093 --from-beginning --topic my-replicated-topic
6.关于分区消费组消费者的细节
./kafka-console-consumer.sh --bootstrap-server 服务器IP地址:9092,服务器IP地址:9093 --from-beginning --topic my-replicated-topic --consumer-property group.id=testGroup1
./kafka-consumer-groups.sh --bootstrap-server 服务器IP地址:9092 --describe --group testGroup1
##运行结果:
Consumer group 'testGroup1' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testGroup1 my-replicated-topic 0 3 3 0 - - -
testGroup1 my-replicated-topic 1 0 0 0 - - -
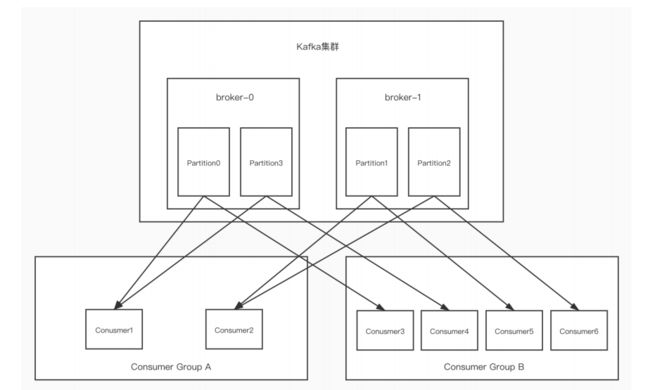
图中Kafka集群有两个broker,每个broker中有多个partition。一个partition只能被一个消费组里的某一个消费者消费,从而保证消费顺序。Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。一个消费者可以消费多个partition。
消费组中消费者的数量不能比一个topic中的partition数量多,否则多出来的消费者消费不到消息。
六、Kafka的Java客户端-生产者
1.引入依赖
kafka的maven依赖需要和docker安装的kafka版本对应上
进入到kafka容器中,查看kafka版本为3.5.1,所以Maven依赖的版本也为3.5.1
cd /opt/bitnami/kafka/libs
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.12artifactId>
<version>3.5.1version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.13.3version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.24version>
dependency>
dependencies>
2.生产者发送消息的基本实现
要向 Kafka 写入消息,首先需要创建一个生产者对象,并设置一些属性。Kafka 生产者有3个必选的属性
-
bootstrap.servers:该属性指定 broker 的地址清单,地址的格式为 host:port。清单里不需要包含所有的 broker 地址,生产者会从给定的 broker 里查找到其他的 broker 信息。不过建议至少要提供两个 broker 信息,一旦其中一个宕机,生产者仍然能够连接到集群上。 -
key.serializer:broker 需要接收到序列化之后的 key/value值,所以生产者发送的消息需要经过序列化之后才传递给 Kafka Broker。生产者需要知道采用何种方式把 Java 对象转换为字节数组。key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer接口的类,生产者会使用这个类把键对象序列化为字节数组。这里拓展一下 Serializer 类Serializer是一个接口,它表示类将会采用何种方式序列化,它的作用是把对象转换为字节,实现了 Serializer 接口的类主要有 ByteArraySerializer、StringSerializer、IntegerSerializer ,其中 ByteArraySerialize 是 Kafka 默认使用的序列化器,其他的序列化器还有很多,你可以通过 这里 查看其他序列化器。要注意的一点:key.serializer 是必须要设置的,即使你打算只发送值的内容。
-
value.serializer:与 key.serializer 一样,value.serializer 指定的类会将值序列化。实现了org.apache.kafka.common.serialization.Serializer接口
此处属性详解参考文章Kafka 入门知识
/**
* 替代黑窗口中的生产者
*/
public class KafkaProducerClient {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "服务器IP地址:9092,服务器IP地址:9093");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
//String -> Object -> HashCode -> 这个字符串在内存中的地址值, 唯一值
ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic", "hello, kafka3");
RecordMetadata recordMetadata = kafkaProducer.send(record).get();
System.out.println("recordMetadata = " + recordMetadata);
}
}
以上代码
- 首先创建了一个 Properties 对象
- 使用 StringSerializer 序列化器序列化 key / value 键值对
- 在这里我们创建了一个新的生产者对象,并为键值设置了恰当的类型,然后把 Properties 对象传递给他。
3.发送消息到指定分区上
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(TOPIC_NAME, 0 , "555", objectMapper.writeValueAsString(order));
4.未指定分区,则会通过业务key的hash运算,算出消息往哪个分区上发
String -> Object -> HashCode -> 这个字符串在内存中的地址值, 唯一值
//String -> Object -> HashCode -> 这个字符串在内存中的地址值, 唯一值
//1.0 不指明分区[最常用]
ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic", "hello, kafka3");
//2.0 指明key "1" => 7 7%2= [同样的key的数据会被放在同一个分区]
ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic","hello", "Hi!!!Dog");
//3.0 直接指明分区
ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic",1, null, "five step ");
//4.0 发送对象
Student stu1 = new Student();
stu1.setId("15321");
stu1.setAge(20);
stu1.setName("贝拉");
//使用json进行转换
ObjectMapper objectMapper = new ObjectMapper();
String stuStr = objectMapper.writeValueAsString(stu1);
System.out.println("stuStr = " + stuStr);//stuStr = {"id":"15321","name":"贝拉","age":20}
ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic", stuStr);
RecordMetadata recordMetadata = kafkaProducer.send(record).get();
System.out.println("该条数据被分配到了分区" + recordMetadata.partition());
运行结果:
stuStr = {"id":"15321","name":"贝拉","age":20}
callback所在线程名称 = Thread[kafka-producer-network-thread | producer-1,5,main]
消息对方已收到, 消息被分配到了-> my-replicated-topic-1@16
当前线程名称:main
当前线程名称:main
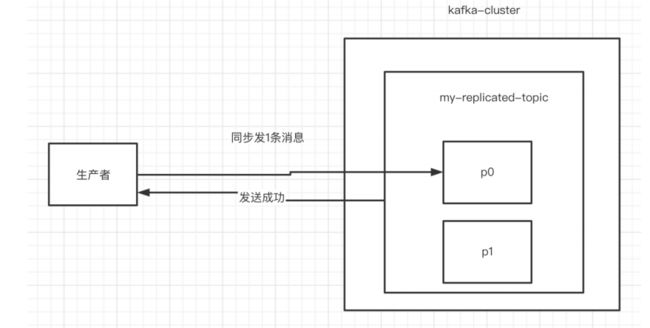
5.同步发送
生产者同步发消息,在收到kafka的ack告知发送成功之前一直处于阻塞状态
//等待消息发送成功的同步阻塞方法
RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("同步方式发送消息结果:" + "topic-" +metadata.topic() + "|partition-"+ metadata.partition() + "|offset-" +metadata.offset());
6.异步发消息
生产者发消息,发送完后不用等待broker给回复,直接执行下面的业务逻辑。
可以提供callback,让broker异步的调用callback,告知生产者,消息发送的结果
函数式接口 (Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。 函数式接口可以被隐式转换为 lambda 表达式。以下的Callback就是一个官方的函数式接口。
public interface Callback {
void onCompletion(RecordMetadata var1, Exception var2);
}
java中所有的线程可以分为守护线程或者用户线程(非守护线程)。当所有的用户线程都结束后, 无论守护线程是否完成了任务, 都会被强行中止结束。
//callback:回调 异步发消息: 生产者发消息,发送完后不用等待broker给回复,直接执行下面的业务逻辑。
kafkaProducer.send(record,(recordMetadata, e) ->{
System.out.println("callback所在线程名称 = " + Thread.currentThread());
if (e == null){
System.out.println("消息对方已收到, 消息被分配到了-> " + recordMetadata);
}else {
System.out.println("消息kafka接收失败, 具体失败原因");
e.printStackTrace();
}
});
while (true){
TimeUnit.SECONDS.sleep(2);
System.out.println("当前线程名称:" + Thread.currentThread().getName());
}
7.关于生产者的ack参数配置
在同步发消息的场景下:生产者发到broker上后,ack会有 3 种不同的选择:
- ( 1 )acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。
- ( 2 )acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。
- ( 3 )acks=-1或all: 需要等待 min.insync.replicas(默认为 1 ,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。
//ack配置 1. "1" 2."0" 3."-1/all/4"
properties.setProperty(ProducerConfig.ACKS_CONFIG, "1");
8.其他一些细节
- 发送会默认会重试 3 次,每次间隔100ms
- 发送的消息会先进入到本地缓冲区(32mb),kakfa会跑一个线程,该线程去缓冲区中取16k的数据,发送到kafka,如果到10毫秒数据没取满16k,也会发送一次。 (微批处理)
七、消费者
1.消费者消费消息的基本实现
在读取消息之前,需要先创建一个 KafkaConsumer 对象。创建 KafkaConsumer 对象与创建 KafkaProducer 对象十分相似 — 把需要传递给消费者的属性放在 properties 对象中,使用3个属性分别是 bootstrap.server,key.deserializer,value.deserializer 。
还有一个属性是 group.id 这个属性不是必须的,它指定了 KafkaConsumer 是属于哪个消费者群组。创建不属于任何一个群组的消费者也是可以的。
class KafkaConsumerClient{
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "服务器IP地址:9092,服务器IP地址:9093");
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "java23");
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("my-replicated-topic"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println("我是消费者, 我拿到了一条数据:");
System.out.println(record.value());
}
}
}
}
2.自动提交offset
- 设置自动提交参数 - 默认
// 是否自动提交offset,默认就是true 自动提交偏移量
//false: 关闭自动提交, 变成了手动提交
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
//自动提交offset的间隔时间: 每隔1s自动提交一次偏移量
properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");
消费者poll到消息后默认情况下,会自动向broker的_consumer_offsets主题提交当前主题-分区消费的偏移量。
自动提交会丢消息: 因为如果消费者还没消费完poll下来的消息就自动提交了偏移量,那么此时消费者挂了,于是下一个消费者会从已提交的offset的下一个位置开始消费消息。之前未被消费的消息就丢失掉了。
3.手动提交offset
当程序代码出现异常的时候, 出现异常的数据会因为没有提交偏移量, 在下一次的拉取中被重新拉取到处理
- 设置手动提交参数
//false: 关闭自动提交, 变成了手动提交
properties.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
如果使用手动提交偏移量的方式进行消费,并且之前已经提交过偏移量了(也是之前的kafka的服务端的当前offset中已经有了偏移量了) ,那么下一次消费时会从已有的那次偏移量开始拉取数据, 从而造成数据的重复消费。
如果使用手动提交偏移量的方式进行消费,并且没有提交偏移量,则会根据消费配置 (默认的消费配置是从最新拉取, 也可以设定成从头拉取)进行拉取数据 这是因为Kafka在进行消费时会根据消费者组、分区、偏移量来判断哪些消息需要被消费,如果没有提交偏移量,那么Kafka就会认为你是一个新的消费者,新的消费者则会依据究竟是从头拉取还是从最新拉取来进行数据的消费。
当提交模式设置为手动提交,因为还没做过提交,所以kafka上没有offset值, 所以依据属性 auto.offset.reset ,默认值 latest,它会让消费者从最后的offset开始消费;
在消费完消息后进行手动提交
- 手动同步提交
if (records.count() > 0 ) {//业务处理代码
// 手动同步提交offset,当前线程会阻塞直到offset提交成功
// 一般使用同步提交,因为提交之后一般也没有什么逻辑代码了
consumer.commitSync();
}
- 手动异步提交
if (records.count() > 0 ) {
// 手动异步提交offset,当前线程提交offset不会阻塞,可以继续处理后面的程序逻辑
//处理逻辑
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
System.err.println("Commit failed for " + offsets);
System.err.println("Commit failed exception: " +exception.getStackTrace());
} else {
System.out.println("提交当前偏移");
}
});
}
4.新消费组的消费偏移量
当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费?
- latest(默认) :只消费自己启动之后发送到主题的消息
- earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费)
//设定新消费者拉取数据的方式, 1.latest(默认) 从最新偏移量开始拉取 2.earliest(最早偏移量拉取)
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
八 、Springboot中使用Kafka
1.引入依赖
<dependency>
<groupId>org.springframework.kafkagroupId>
<artifactId>spring-kafkaartifactId>
dependency>
2.配置文件
server:
port: 8080
spring:
kafka:
bootstrap-servers: 服务器IP地址:9092,服务器IP地址:9093
producer: # 生产者
retries: 3 # 设置大于 0 的值,则客户端会将发送失败的记录重新发送
batch-size: 16384
buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default-group
enable-auto-commit: false
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
max-poll-records: 500
listener:
# 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种
# MANUAL_IMMEDIATE
ack-mode: MANUAL_IMMEDIATE
3.消息生产者
- 发送消息到指定topic
@RestController
public class KafkaController {
private final static String TOPIC_NAME = "my-replicated-topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public void send() {
kafkaTemplate.send(TOPIC_NAME, 0 , "key", "this is a msg");
}
}
4.消息消费者
- 设置消费组,消费指定topic
@KafkaListener(topics = "my-replicated-topic",groupId = "MyGroup1")
public void listenGroup(ConsumerRecord<String, String> record,Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//手动提交offset
ack.acknowledge();
}
kafka 默认存放7天的临时数据,默认使用 log.retention.hours 参数配置时间,默认值是168小时,也就是一周。如果遇到磁盘空间小,存放数据量大,可以设置缩短这个时间。
在实践中,使用Kafka需要注意一些细节,如选择合适的分区策略、处理重复或丢失数据等问题。我们需要根据具体业务需求,综合考虑Kafka的性能、稳定性和可扩展性等因素,合理配置和使用Kafka。