AOT-GAN-for-Inpainting项目解读|使用AOT-GAN进行图像修复
项目地址: https://github.com/researchmm/AOT-GAN-for-Inpainting 基于pytorch实现
论文地址: https://arxiv.org/abs/2104.01431
开源时间: 2021年
项目简介: AOT-GAN-for-Inpainting是一个开源的图像修复项目,其对 Places2 数据集的效果表明,我们的模型在 FID 方面明显优于最先进的模型,相对改进了 1.8%。一项包括 365 多名受试者的用户研究进一步验证了 AOT-GAN 的优越性。我们进一步评估了所提出的AOT-GAN在实际应用中的应用,例如,logo去除、面部修复和物体移除。结果表明,我们的模型在现实的广泛数据数据中取得了良好的效果。


预训练模型:CELEBA-HQ |Places2
1、论文主要创新点
1.1 基本介绍
当前的图像修复方法可能会在高分辨率图像(例如 512x512)中产生扭曲的结构和模糊的纹理。这些挑战主要来自:
(1)来自较远区域的图像内容推理,
(2)对大缺失区域的细粒度纹理合成。
为了克服这两个挑战,提出了一种增强的基于GAN的模型,称为(AOT-GAN),用于高分辨率图像修复。具体来说,为了增强上下文推理,AOT-GAN-for-Inpainting通过堆叠所提出的 AOT 块的多层来构建 AOT-GAN 的生成器。AOT-block来自各种感受野的聚合上下文转换,从而允许捕获信息丰富的远距离图像上下文和丰富的感兴趣模式以进行上下文推理。为了改善纹理合成,AOT-GAN-for-Inpainting通过使用量身定制的掩码预测任务来训练AOT-GAN的判别器。这样的训练目标迫使判别器区分真实和合成补丁的详细外观,进而促进生成器合成清晰的纹理。
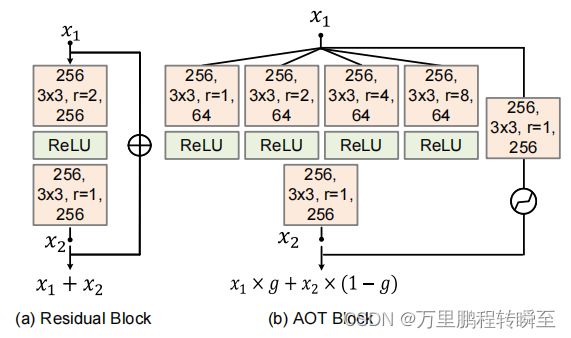
1.2 AOT-block
AOT-block是本文提出的一大创新点,其认为普通的残差结构无法捕捉的全局信息,因此提出一种类似于aspp的多尺度的孔洞卷积卷积结构,同时又将残差结构与类aspp结构联合在一起(以带可训练权重的方式进行联合)。这种aot-block结构很适合进行场景解析,其类assp结构可以获取多尺度全局信息,右侧的分支可以按照正常的卷积模型提取特征,附带的可训练参数g可以根据反向传播调整多尺度全局信息与具备信息的比例。
其对应的代码实现如下
class AOTBlock(nn.Module):
def __init__(self, dim, rates):
super(AOTBlock, self).__init__()
self.rates = rates
for i, rate in enumerate(rates):
self.__setattr__(
'block{}'.format(str(i).zfill(2)),
nn.Sequential(
nn.ReflectionPad2d(rate),
nn.Conv2d(dim, dim//4, 3, padding=0, dilation=rate),
nn.ReLU(True)))
self.fuse = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(dim, dim, 3, padding=0, dilation=1))
self.gate = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(dim, dim, 3, padding=0, dilation=1))
def forward(self, x):
out = [self.__getattr__(f'block{str(i).zfill(2)}')(x) for i in range(len(self.rates))]
out = torch.cat(out, 1)
out = self.fuse(out)
mask = my_layer_norm(self.gate(x))
mask = torch.sigmoid(mask)
return x * (1 - mask) + out * mask
1.3 SM-PatchGAN
作者指出持相对于PatchGAN直接将整图作为虚假目标,另一种掩模预测任务的另一种可能的设计HM-PatchGAN,如图4所示,HMPatchGAN通过在不进行高斯滤波的情况下进行硬二值patch掩模训练,增强了PatchGAN鉴别器。HM-PatchGAN考虑了所修复图像的原来真实部分,但忽略了mask的不规则性,其中标签为0中的部分patch中,尤其是靠近标签为1的patch,必然有部分是真实值。
作者推测这样的设计会削弱鉴别器的训练。为了避免上述问题,所提出的SM-PatchGAN采用高斯滤波处理对HM-Patch进行软换。我们进行了广泛的消融研究,以显示SM-PatchGAN的优越性。

可以看出所提出的SM-PatchGAN方式能使FID有显著提升

其进行高斯模糊的代码如下所示,具体作用在loss.py种的smgan loss中
def gaussian(window_size, sigma):
def gauss_fcn(x):
return -(x - window_size // 2)**2 / float(2 * sigma**2)
gauss = torch.stack([torch.exp(torch.tensor(gauss_fcn(x)))
for x in range(window_size)])
return gauss / gauss.sum()
def get_gaussian_kernel(kernel_size: int, sigma: float) -> torch.Tensor:
r"""Function that returns Gaussian filter coefficients.
Args:
kernel_size (int): filter size. It should be odd and positive.
sigma (float): gaussian standard deviation.
Returns:
Tensor: 1D tensor with gaussian filter coefficients.
Shape:
- Output: :math:`(\text{kernel_size})`
Examples::
>>> kornia.image.get_gaussian_kernel(3, 2.5)
tensor([0.3243, 0.3513, 0.3243])
>>> kornia.image.get_gaussian_kernel(5, 1.5)
tensor([0.1201, 0.2339, 0.2921, 0.2339, 0.1201])
"""
if not isinstance(kernel_size, int) or kernel_size % 2 == 0 or kernel_size <= 0:
raise TypeError(
"kernel_size must be an odd positive integer. Got {}".format(kernel_size))
window_1d: torch.Tensor = gaussian(kernel_size, sigma)
return window_1d
def get_gaussian_kernel2d(kernel_size, sigma):
r"""Function that returns Gaussian filter matrix coefficients.
Args:
kernel_size (Tuple[int, int]): filter sizes in the x and y direction.
Sizes should be odd and positive.
sigma (Tuple[int, int]): gaussian standard deviation in the x and y
direction.
Returns:
Tensor: 2D tensor with gaussian filter matrix coefficients.
Shape:
- Output: :math:`(\text{kernel_size}_x, \text{kernel_size}_y)`
Examples::
>>> kornia.image.get_gaussian_kernel2d((3, 3), (1.5, 1.5))
tensor([[0.0947, 0.1183, 0.0947],
[0.1183, 0.1478, 0.1183],
[0.0947, 0.1183, 0.0947]])
>>> kornia.image.get_gaussian_kernel2d((3, 5), (1.5, 1.5))
tensor([[0.0370, 0.0720, 0.0899, 0.0720, 0.0370],
[0.0462, 0.0899, 0.1123, 0.0899, 0.0462],
[0.0370, 0.0720, 0.0899, 0.0720, 0.0370]])
"""
if not isinstance(kernel_size, tuple) or len(kernel_size) != 2:
raise TypeError(
"kernel_size must be a tuple of length two. Got {}".format(kernel_size))
if not isinstance(sigma, tuple) or len(sigma) != 2:
raise TypeError(
"sigma must be a tuple of length two. Got {}".format(sigma))
ksize_x, ksize_y = kernel_size
sigma_x, sigma_y = sigma
kernel_x: torch.Tensor = get_gaussian_kernel(ksize_x, sigma_x)
kernel_y: torch.Tensor = get_gaussian_kernel(ksize_y, sigma_y)
kernel_2d: torch.Tensor = torch.matmul(
kernel_x.unsqueeze(-1), kernel_y.unsqueeze(-1).t())
return kernel_2d
class GaussianBlur(nn.Module):
r"""Creates an operator that blurs a tensor using a Gaussian filter.
The operator smooths the given tensor with a gaussian kernel by convolving
it to each channel. It suports batched operation.
Arguments:
kernel_size (Tuple[int, int]): the size of the kernel.
sigma (Tuple[float, float]): the standard deviation of the kernel.
Returns:
Tensor: the blurred tensor.
Shape:
- Input: :math:`(B, C, H, W)`
- Output: :math:`(B, C, H, W)`
Examples::
>>> input = torch.rand(2, 4, 5, 5)
>>> gauss = kornia.filters.GaussianBlur((3, 3), (1.5, 1.5))
>>> output = gauss(input) # 2x4x5x5
"""
def __init__(self, kernel_size, sigma):
super(GaussianBlur, self).__init__()
self.kernel_size = kernel_size
self.sigma = sigma
self._padding = self.compute_zero_padding(kernel_size)
self.kernel = get_gaussian_kernel2d(kernel_size, sigma)
@staticmethod
def compute_zero_padding(kernel_size):
"""Computes zero padding tuple."""
computed = [(k - 1) // 2 for k in kernel_size]
return computed[0], computed[1]
def forward(self, x): # type: ignore
if not torch.is_tensor(x):
raise TypeError(
"Input x type is not a torch.Tensor. Got {}".format(type(x)))
if not len(x.shape) == 4:
raise ValueError(
"Invalid input shape, we expect BxCxHxW. Got: {}".format(x.shape))
# prepare kernel
b, c, h, w = x.shape
tmp_kernel: torch.Tensor = self.kernel.to(x.device).to(x.dtype)
kernel: torch.Tensor = tmp_kernel.repeat(c, 1, 1, 1)
# TODO: explore solution when using jit.trace since it raises a warning
# because the shape is converted to a tensor instead to a int.
# convolve tensor with gaussian kernel
return conv2d(x, kernel, padding=self._padding, stride=1, groups=c)
######################
# functional interface
######################
def gaussian_blur(input, kernel_size, sigma):
r"""Function that blurs a tensor using a Gaussian filter.
See :class:`~kornia.filters.GaussianBlur` for details.
"""
return GaussianBlur(kernel_size, sigma)(input)
2、模型结构
2.1 生成器
在代码src\model\aotgan.py 定义了模型的主要实现代码
class InpaintGenerator(BaseNetwork):
def __init__(self, args): # 1046
super(InpaintGenerator, self).__init__()
self.encoder = nn.Sequential(
nn.ReflectionPad2d(3),
nn.Conv2d(4, 64, 7),
nn.ReLU(True),
nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.ReLU(True),
nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.ReLU(True)
)
self.middle = nn.Sequential(*[AOTBlock(256, args.rates) for _ in range(args.block_num)])
self.decoder = nn.Sequential(
UpConv(256, 128),
nn.ReLU(True),
UpConv(128, 64),
nn.ReLU(True),
nn.Conv2d(64, 3, 3, stride=1, padding=1)
)
self.init_weights()
def forward(self, x, mask):
x = torch.cat([x, mask], dim=1)
x = self.encoder(x)
x = self.middle(x)
x = self.decoder(x)
x = torch.tanh(x)
return x
其所对应的网络结构如下所示,其中绿色的是middle,两端的是编码器与解码器。

2.2 判别器
相比于复杂的生成器,判别器结构比较简单。其中比较特别的是spectral_norm,可以参考https://zhuanlan.zhihu.com/p/63957812。spectral_norm是pytorch自带的频谱归一化函数,给设定好的网络进行频谱归一化。其是用于在gan中,修改数据分布,使判别器 D 满足利普希茨连续性,限制了函数变化的剧烈程度,从而使模型更稳定,是训练gan网络的一大利器。 在gan中,判别器训练越好,生成器梯度消失越严重。gan需要简单而稳定的判别器,使用spectral_norm可以达到这一目的。
class Discriminator(BaseNetwork):
def __init__(self, ):
super(Discriminator, self).__init__()
inc = 3
self.conv = nn.Sequential(
spectral_norm(nn.Conv2d(inc, 64, 4, stride=2, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True),
spectral_norm(nn.Conv2d(64, 128, 4, stride=2, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True),
spectral_norm(nn.Conv2d(128, 256, 4, stride=2, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True),
spectral_norm(nn.Conv2d(256, 512, 4, stride=1, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, 4, stride=1, padding=1)
)
self.init_weights()
def forward(self, x):
feat = self.conv(x)
return feat
2.3 common.py
该代码没有重要信息,主要是实现对模型权重的初始化。
import torch
import torch.nn as nn
class BaseNetwork(nn.Module):
def __init__(self):
super(BaseNetwork, self).__init__()
def print_network(self):
if isinstance(self, list):
self = self[0]
num_params = 0
for param in self.parameters():
num_params += param.numel()
print('Network [%s] was created. Total number of parameters: %.1f million. '
'To see the architecture, do print(network).' % (type(self).__name__, num_params / 1000000))
def init_weights(self, init_type='normal', gain=0.02):
'''
initialize network's weights
init_type: normal | xavier | kaiming | orthogonal
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/9451e70673400885567d08a9e97ade2524c700d0/models/networks.py#L39
'''
def init_func(m):
classname = m.__class__.__name__
if classname.find('InstanceNorm2d') != -1:
if hasattr(m, 'weight') and m.weight is not None:
nn.init.constant_(m.weight.data, 1.0)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias.data, 0.0)
elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
if init_type == 'normal':
nn.init.normal_(m.weight.data, 0.0, gain)
elif init_type == 'xavier':
nn.init.xavier_normal_(m.weight.data, gain=gain)
elif init_type == 'xavier_uniform':
nn.init.xavier_uniform_(m.weight.data, gain=1.0)
elif init_type == 'kaiming':
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
nn.init.orthogonal_(m.weight.data, gain=gain)
elif init_type == 'none': # uses pytorch's default init method
m.reset_parameters()
else:
raise NotImplementedError(
'initialization method [%s] is not implemented' % init_type)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias.data, 0.0)
self.apply(init_func)
# propagate to children
for m in self.children():
if hasattr(m, 'init_weights'):
m.init_weights(init_type, gain)
3、数据加载器
3.1 预训练模型
在论文中表述了一共在3个数据集上进行训练,但仅发布了两个预训练模型,关于logo移除的模型或许设计商业因素未公开。
CELEBA-HQ |Places2
其预训练模型数据的基本介绍如下
-
Places2[26]包含来自365种场景的180万张图片。由于其复杂的场景,它是图像内绘制中最具挑战性的数据集之一。我们使用训练/测试的分割(即180万/36500万),遵循大多数内绘画模型[13,17,21]使用的设置。
-
CELEBA-HQ [50]是一个高质量的人脸数据集。毛发和皮肤的高频细节可以帮助我们评估模型的细粒度纹理合成。我们使用28,000张图像进行训练,使用2,000张图像按照通用设置[13,17]进行测试。
-
QMUL-OpenLogo [51]包含了来自352个logo类的27,083个图片。每个图像都有细粒度的标识边界框注释。我们使用15,975张训练图像进行训练,使用2,777张验证图像进行测试。
3.2 训练数据案例
详情请参考https://blog.csdn.net/qq_45790998/article/details/128741301, 通过对数据案例的分析,进行人脸修复应该使用CELEBA-HQ模型,进行通用图像修改则使用Places2数据集。
CELEBA-HQ是一个由高分辨率人脸图像和相关属性标签组成的数据集。它包含了超过 30,000 张高分辨率(1024x1024)的人脸图像,这些图像来自于超过 1,000 位不同的名人。

Places2数据集是一个大型的场景图像数据集,这个数据集共包含了405种不同场景类别的10万张高质量的场景图像。

3.3 dataload代码
其dataload的代码如下,默认是使用pconv的方式(带mask的数据集|png图片);对于不带mask的图片,修改args.mask_type为其他值,则默认将图像中央区域生成mask。
import os
import math
import numpy as np
from glob import glob
from random import shuffle
from PIL import Image, ImageFilter
import torch
import torchvision.transforms.functional as F
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
class InpaintingData(Dataset):
def __init__(self, args):
super(Dataset, self).__init__()
self.w = self.h = args.image_size
self.mask_type = args.mask_type
# image and mask
self.image_path = []
for ext in ['*.jpg', '*.png']:
self.image_path.extend(glob(os.path.join(args.dir_image, args.data_train, ext)))
self.mask_path = glob(os.path.join(args.dir_mask, args.mask_type, '*.png'))
# augmentation
self.img_trans = transforms.Compose([
transforms.RandomResizedCrop(args.image_size),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.05, 0.05, 0.05, 0.05),
transforms.ToTensor()])
self.mask_trans = transforms.Compose([
transforms.Resize(args.image_size, interpolation=transforms.InterpolationMode.NEAREST),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(
(0, 45), interpolation=transforms.InterpolationMode.NEAREST),
])
def __len__(self):
return len(self.image_path)
def __getitem__(self, index):
# load image
image = Image.open(self.image_path[index]).convert('RGB')
filename = os.path.basename(self.image_path[index])
if self.mask_type == 'pconv':
index = np.random.randint(0, len(self.mask_path))
mask = Image.open(self.mask_path[index])
mask = mask.convert('L')
else:
mask = np.zeros((self.h, self.w)).astype(np.uint8)
mask[self.h//4:self.h//4*3, self.w//4:self.w//4*3] = 1
mask = Image.fromarray(mask).convert('L')
# augment
image = self.img_trans(image) * 2. - 1.
mask = F.to_tensor(self.mask_trans(mask))
return image, mask, filename
if __name__ == '__main__':
from attrdict import AttrDict
args = {
'dir_image': '../../../dataset',
'data_train': 'places2',
'dir_mask': '../../../dataset',
'mask_type': 'pconv',
'image_size': 512
}
args = AttrDict(args)
data = InpaintingData(args)
print(len(data), len(data.mask_path))
img, mask, filename = data[0]
print(img.size(), mask.size(), filename)
对于这种dataload,可以考虑随机生成多边形mask,来丰富训练数据。同时,在模型训练稳定后改用复杂的transform进行数据增强。
4、loss实现
4.1 具体代码
其所对应的loss有4种,Ladv对应代码中的nsgan函数,也就是作者所提出的SM-PatchGAN部分。

import torch
import torch.nn as nn
import torch.nn.functional as F
from .common import VGG19, gaussian_blur
class L1():
def __init__(self,):
self.calc = torch.nn.L1Loss()
def __call__(self, x, y):
return self.calc(x, y)
class Perceptual(nn.Module):
def __init__(self, weights=[1.0, 1.0, 1.0, 1.0, 1.0]):
super(Perceptual, self).__init__()
self.vgg = VGG19().cuda()
self.criterion = torch.nn.L1Loss()
self.weights = weights
def __call__(self, x, y):
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
content_loss = 0.0
prefix = [1, 2, 3, 4, 5]
for i in range(5):
content_loss += self.weights[i] * self.criterion(
x_vgg[f'relu{prefix[i]}_1'], y_vgg[f'relu{prefix[i]}_1'])
return content_loss
class Style(nn.Module):
def __init__(self):
super(Style, self).__init__()
self.vgg = VGG19().cuda()
self.criterion = torch.nn.L1Loss()
def compute_gram(self, x):
b, c, h, w = x.size()
f = x.view(b, c, w * h)
f_T = f.transpose(1, 2)
G = f.bmm(f_T) / (h * w * c)
return G
def __call__(self, x, y):
x_vgg, y_vgg = self.vgg(x), self.vgg(y)
style_loss = 0.0
prefix = [2, 3, 4, 5]
posfix = [2, 4, 4, 2]
for pre, pos in list(zip(prefix, posfix)):
style_loss += self.criterion(
self.compute_gram(x_vgg[f'relu{pre}_{pos}']), self.compute_gram(y_vgg[f'relu{pre}_{pos}']))
return style_loss
class nsgan():
def __init__(self, ):
self.loss_fn = torch.nn.Softplus()
def __call__(self, netD, fake, real):
fake_detach = fake.detach()
d_fake = netD(fake_detach)
d_real = netD(real)
dis_loss = self.loss_fn(-d_real).mean() + self.loss_fn(d_fake).mean()
g_fake = netD(fake)
gen_loss = self.loss_fn(-g_fake).mean()
return dis_loss, gen_loss
class smgan():
def __init__(self, ksize=71):
self.ksize = ksize
self.loss_fn = nn.MSELoss()
def __call__(self, netD, fake, real, masks):
fake_detach = fake.detach()
g_fake = netD(fake)
d_fake = netD(fake_detach)
d_real = netD(real)
_, _, h, w = g_fake.size()
b, c, ht, wt = masks.size()
# Handle inconsistent size between outputs and masks
if h != ht or w != wt:
g_fake = F.interpolate(g_fake, size=(ht, wt), mode='bilinear', align_corners=True)
d_fake = F.interpolate(d_fake, size=(ht, wt), mode='bilinear', align_corners=True)
d_real = F.interpolate(d_real, size=(ht, wt), mode='bilinear', align_corners=True)
d_fake_label = gaussian_blur(masks, (self.ksize, self.ksize), (10, 10)).detach().cuda()
d_real_label = torch.zeros_like(d_real).cuda()
g_fake_label = torch.ones_like(g_fake).cuda()
dis_loss = self.loss_fn(d_fake, d_fake_label) + self.loss_fn(d_real, d_real_label)
gen_loss = self.loss_fn(g_fake, g_fake_label) * masks / torch.mean(masks)
return dis_loss.mean(), gen_loss.mean()
4.2 VGG19
在4.1中的3个loss函数中,都利用到了vgg19对数据提取特征,然后在计算loss。以下代码在src\loss\common.py中,实现了对VGG19模型的分层编码,抽取了VGG19种每一个stage中的conv的输出。其中prefix 用于描述stage,posfix 用于描述stage中conv的位置。

import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
from torch.nn.functional import conv2d
class VGG19(nn.Module):
def __init__(self, resize_input=False):
super(VGG19, self).__init__()
features = models.vgg19(pretrained=True).features
self.resize_input = resize_input
self.mean = torch.Tensor([0.485, 0.456, 0.406]).cuda()
self.std = torch.Tensor([0.229, 0.224, 0.225]).cuda()
prefix = [1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5]
posfix = [1, 2, 1, 2, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]
names = list(zip(prefix, posfix))
self.relus = []
for pre, pos in names:
self.relus.append('relu{}_{}'.format(pre, pos))
self.__setattr__('relu{}_{}'.format(
pre, pos), torch.nn.Sequential())
nums = [[0, 1], [2, 3], [4, 5, 6], [7, 8],
[9, 10, 11], [12, 13], [14, 15], [16, 17],
[18, 19, 20], [21, 22], [23, 24], [25, 26],
[27, 28, 29], [30, 31], [32, 33], [34, 35]]
for i, layer in enumerate(self.relus):
for num in nums[i]:
self.__getattr__(layer).add_module(str(num), features[num])
# don't need the gradients, just want the features
for param in self.parameters():
param.requires_grad = False
def forward(self, x):
# resize and normalize input for pretrained vgg19
x = (x + 1.0) / 2.0
x = (x - self.mean.view(1, 3, 1, 1)) / (self.std.view(1, 3, 1, 1))
if self.resize_input:
x = F.interpolate(
x, size=(256, 256), mode='bilinear', align_corners=True)
features = []
for layer in self.relus:
x = self.__getattr__(layer)(x)
features.append(x)
out = {key: value for (key, value) in list(zip(self.relus, features))}
return out
5、评价指标
评价指标相关的全部代码在src\metric\metric.py中,具体有mae、psnr、ssim、fid。其中fid最为复杂,涉及了InceptionV3模型和calculate_activation_statistics、get_activations、calculate_frechet_distance三个函数。
其中代码的亮点,或可学习点在于其使用Pool.imap_unordered实现对数据的多线程处理,同时又利用tqdm实现了进度条的显示。
def compare_psnr(pairs):
real, fake = pairs
return peak_signal_noise_ratio(real, fake)
def psnr(reals, fakes, num_worker=8):
error = 0
pool = Pool(num_worker)
for val in tqdm(pool.imap_unordered(compare_psnr, zip(reals, fakes)), total=len(reals), desc='compare_psnr'):
error += val
return error / len(reals)
全部代码如下:
import os
import pickle
import numpy as np
from tqdm import tqdm
from scipy import linalg
from multiprocessing import Pool
from skimage.metrics import structural_similarity
from skimage.metrics import peak_signal_noise_ratio
import torch
from torch.autograd import Variable
from torch.nn.functional import adaptive_avg_pool2d
from .inception import InceptionV3
# ============================
def compare_mae(pairs):
real, fake = pairs
real, fake = real.astype(np.float32), fake.astype(np.float32)
return np.sum(np.abs(real - fake)) / np.sum(real + fake)
def compare_psnr(pairs):
real, fake = pairs
return peak_signal_noise_ratio(real, fake)
def compare_ssim(pairs):
real, fake = pairs
return structural_similarity(real, fake, multichannel=True)
# ================================
def mae(reals, fakes, num_worker=8):
error = 0
pool = Pool(num_worker)
for val in tqdm(pool.imap_unordered(compare_mae, zip(reals, fakes)), total=len(reals), desc='compare_mae'):
error += val
return error / len(reals)
def psnr(reals, fakes, num_worker=8):
error = 0
pool = Pool(num_worker)
for val in tqdm(pool.imap_unordered(compare_psnr, zip(reals, fakes)), total=len(reals), desc='compare_psnr'):
error += val
return error / len(reals)
def ssim(reals, fakes, num_worker=8):
error = 0
pool = Pool(num_worker)
for val in tqdm(pool.imap_unordered(compare_ssim, zip(reals, fakes)), total=len(reals), desc='compare_ssim'):
error += val
return error / len(reals)
def fid(reals, fakes, num_worker=8, real_fid_path=None):
dims = 2048
batch_size = 4
block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
model = InceptionV3([block_idx]).cuda()
if real_fid_path is None:
real_fid_path = 'places2_fid.pt'
if os.path.isfile(real_fid_path):
data = pickle.load(open(real_fid_path, 'rb'))
real_m, real_s = data['mu'], data['sigma']
else:
reals = (np.array(reals).astype(np.float32) / 255.0).transpose((0, 3, 1, 2))
real_m, real_s = calculate_activation_statistics(reals, model, batch_size, dims)
with open(real_fid_path, 'wb') as f:
pickle.dump({'mu': real_m, 'sigma': real_s}, f)
# calculate fid statistics for fake images
fakes = (np.array(fakes).astype(np.float32) / 255.0).transpose((0, 3, 1, 2))
fake_m, fake_s = calculate_activation_statistics(fakes, model, batch_size, dims)
fid_value = calculate_frechet_distance(real_m, real_s, fake_m, fake_s)
return fid_value
def calculate_activation_statistics(images, model, batch_size=64,
dims=2048, cuda=True, verbose=False):
"""Calculation of the statistics used by the FID.
Params:
-- images : Numpy array of dimension (n_images, 3, hi, wi). The values
must lie between 0 and 1.
-- model : Instance of inception model
-- batch_size : The images numpy array is split into batches with
batch size batch_size. A reasonable batch size
depends on the hardware.
-- dims : Dimensionality of features returned by Inception
-- cuda : If set to True, use GPU
-- verbose : If set to True and parameter out_step is given, the
number of calculated batches is reported.
Returns:
-- mu : The mean over samples of the activations of the pool_3 layer of
the inception model.
-- sigma : The covariance matrix of the activations of the pool_3 layer of
the inception model.
"""
act = get_activations(images, model, batch_size, dims, cuda, verbose)
mu = np.mean(act, axis=0)
sigma = np.cov(act, rowvar=False)
return mu, sigma
def get_activations(images, model, batch_size=64, dims=2048, cuda=True, verbose=False):
"""Calculates the activations of the pool_3 layer for all images.
Params:
-- images : Numpy array of dimension (n_images, 3, hi, wi). The values
must lie between 0 and 1.
-- model : Instance of inception model
-- batch_size : the images numpy array is split into batches with
batch size batch_size. A reasonable batch size depends
on the hardware.
-- dims : Dimensionality of features returned by Inception
-- cuda : If set to True, use GPU
-- verbose : If set to True and parameter out_step is given, the number
of calculated batches is reported.
Returns:
-- A numpy array of dimension (num images, dims) that contains the
activations of the given tensor when feeding inception with the
query tensor.
"""
model.eval()
d0 = images.shape[0]
if batch_size > d0:
print(('Warning: batch size is bigger than the data size. '
'Setting batch size to data size'))
batch_size = d0
n_batches = d0 // batch_size
n_used_imgs = n_batches * batch_size
pred_arr = np.empty((n_used_imgs, dims))
for i in tqdm(range(n_batches), desc='calculate activations'):
if verbose:
print('\rPropagating batch %d/%d' %
(i + 1, n_batches), end='', flush=True)
start = i * batch_size
end = start + batch_size
batch = torch.from_numpy(images[start:end]).type(torch.FloatTensor)
batch = Variable(batch)
if torch.cuda.is_available:
batch = batch.cuda()
with torch.no_grad():
pred = model(batch)[0]
# If model output is not scalar, apply global spatial average pooling.
# This happens if you choose a dimensionality not equal 2048.
if pred.shape[2] != 1 or pred.shape[3] != 1:
pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
pred_arr[start:end] = pred.cpu().data.numpy().reshape(batch_size, -1)
if verbose:
print(' done')
return pred_arr
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
"""Numpy implementation of the Frechet Distance.
The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
and X_2 ~ N(mu_2, C_2) is
d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
Stable version by Dougal J. Sutherland.
Params:
-- mu1 : Numpy array containing the activations of a layer of the
inception net (like returned by the function 'get_predictions')
for generated samples.
-- mu2 : The sample mean over activations, precalculated on an
representive data set.
-- sigma1: The covariance matrix over activations for generated samples.
-- sigma2: The covariance matrix over activations, precalculated on an
representive data set.
Returns:
-- : The Frechet Distance.
"""
mu1 = np.atleast_1d(mu1)
mu2 = np.atleast_1d(mu2)
sigma1 = np.atleast_2d(sigma1)
sigma2 = np.atleast_2d(sigma2)
assert mu1.shape == mu2.shape, 'Training and test mean vectors have different lengths'
assert sigma1.shape == sigma2.shape, 'Training and test covariances have different dimensions'
diff = mu1 - mu2
# Product might be almost singular
covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
if not np.isfinite(covmean).all():
msg = ('fid calculation produces singular product; '
'adding %s to diagonal of cov estimates') % eps
print(msg)
offset = np.eye(sigma1.shape[0]) * eps
covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
# Numerical error might give slight imaginary component
if np.iscomplexobj(covmean):
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
m = np.max(np.abs(covmean.imag))
raise ValueError('Imaginary component {}'.format(m))
covmean = covmean.real
tr_covmean = np.trace(covmean)
return (diff.dot(diff) + np.trace(sigma1) + np.trace(sigma2) - 2 * tr_covmean)
6、使用项目
6.1 配置文件
使用项目进行训练、验证、测试的代码在src\utils\option.py中,可以在此修改默认配置。
import argparse
parser = argparse.ArgumentParser(description='Image Inpainting')
# data specifications
parser.add_argument('--dir_image', type=str, default='../../dataset',
help='image dataset directory')
parser.add_argument('--dir_mask', type=str, default='../../dataset',
help='mask dataset directory')
parser.add_argument('--data_train', type=str, default='places2',
help='dataname used for training')
parser.add_argument('--data_test', type=str, default='places2',
help='dataname used for testing')
parser.add_argument('--image_size', type=int, default=512,
help='image size used during training')
parser.add_argument('--mask_type', type=str, default='pconv',
help='mask used during training')
# model specifications
parser.add_argument('--model', type=str, default='aotgan',
help='model name')
parser.add_argument('--block_num', type=int, default=8,
help='number of AOT blocks')
parser.add_argument('--rates', type=str, default='1+2+4+8',
help='dilation rates used in AOT block')
parser.add_argument('--gan_type', type=str, default='smgan',
help='discriminator types')
# hardware specifications
parser.add_argument('--seed', type=int, default=2021,
help='random seed')
parser.add_argument('--num_workers', type=int, default=4,
help='number of workers used in data loader')
# optimization specifications
parser.add_argument('--lrg', type=float, default=1e-4,
help='learning rate for generator')
parser.add_argument('--lrd', type=float, default=1e-4,
help='learning rate for discriminator')
parser.add_argument('--optimizer', default='ADAM',
choices=('SGD', 'ADAM', 'RMSprop'),
help='optimizer to use (SGD | ADAM | RMSprop)')
parser.add_argument('--beta1', type=float, default=0.5,
help='beta1 in optimizer')
parser.add_argument('--beta2', type=float, default=0.999,
help='beta2 in optimier')
# loss specifications
parser.add_argument('--rec_loss', type=str, default='1*L1+250*Style+0.1*Perceptual',
help='losses for reconstruction')
parser.add_argument('--adv_weight', type=float, default=0.01,
help='loss weight for adversarial loss')
# training specifications
parser.add_argument('--iterations', type=int, default=1e6,
help='the number of iterations for training')
parser.add_argument('--batch_size', type=int, default=8,
help='batch size in each mini-batch')
parser.add_argument('--port', type=int, default=22334,
help='tcp port for distributed training')
parser.add_argument('--resume', action='store_true',
help='resume from previous iteration')
# log specifications
parser.add_argument('--print_every', type=int, default=10,
help='frequency for updating progress bar')
parser.add_argument('--save_every', type=int, default=1e4,
help='frequency for saving models')
parser.add_argument('--save_dir', type=str, default='../experiments',
help='directory for saving models and logs')
parser.add_argument('--tensorboard', action='store_true',
help='default: false, since it will slow training. use it for debugging')
# test and demo specifications
parser.add_argument('--pre_train', type=str, default=None,
help='path to pretrained models')
parser.add_argument('--outputs', type=str, default='../outputs',
help='path to save results')
parser.add_argument('--thick', type=int, default=15,
help='the thick of pen for free-form drawing')
parser.add_argument('--painter', default='freeform', choices=('freeform', 'bbox'),
help='different painters for demo ')
# ----------------------------------
args = parser.parse_args()
args.iterations = int(args.iterations)
args.rates = list(map(int, list(args.rates.split('+'))))
losses = list(args.rec_loss.split('+'))
args.rec_loss = {}
for l in losses:
weight, name = l.split('*')
args.rec_loss[name] = float(weight)
6.2 训练验证测试
训练验证测试代码在src目录下,由于其开源模型性能较好,不做深入研究。
参考官网教程即可进行相应操作

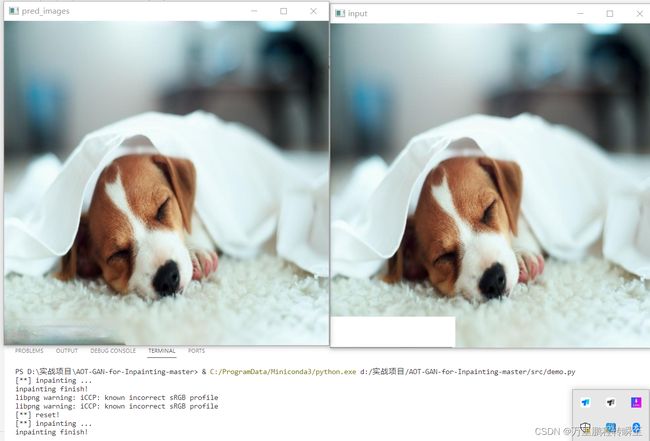
6.3 使用demo进行图像修改
到https://drive.google.com/drive/folders/1bSOH-2nB3feFRyDEmiX81CEiWkghss3i 下载作者发布的G模型,具体如下图所示,并存放到src目录下。

在src目录下创建test_data目录,并将自己的测试图片(jpg或png后缀)存入。

将demo.py的代码修改为以下形式
if __name__ == '__main__':
args.pre_train="src/G0000000.pt"
args.dir_image="src/test_data"
args.painter="bbox" #'freeform', 'bbox'
demo(args)
freeform表示自由涂绘,bbox表示绘制矩形。按下鼠标即可在input窗口内进行绘图,按空格键表示进行图像修复,按 r 键表示情况mask重新绘图,按 n 键表示进入到下一个图像,按 s 键表示保存图像。