C语言浮点数据类型详解及常见的坑
目录
一、编码格式
二、取值分类
三、范围及精度
3.1 范围
3.2 精度
四、运算方式:
4.1 加减法运算
4.2 乘除法运算
五、常见的坑及处理方法
5.1 输出数据与输入数据不一致
5.2 浮点数据的比较运算
5.3.浮点数据与整形数据强制转换的问题
大家都知道C语言中的浮点数据有取值范围广、计算不易溢出、可使用小数等优点,所以在编码中会常用到。但实际上浮点数据是有很多坑的,只有深入了解浮点数据的编码结构才能在工作中避免误用浮点数据。
本文以C语言单精度(float类型)为例,详细讲解一下浮点数据的格式、范围、精度、计算方法及常见的问题。双精度浮点(double类型)数据与之类似,本文不再做详细分析。
一、编码格式
C语言中的浮点数据类型采用的是工业标准IEEE754,单精度(float类型)32位数据的编码格式如下所示,由左向右分别为bit31~bit0。
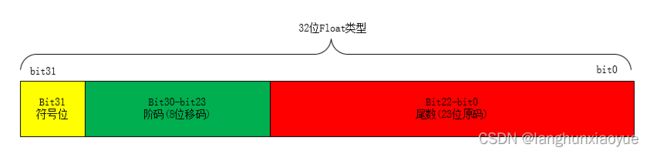
符号位S(bit31):表示浮点数正负,1—负数,0—正数;
阶码E(bit23~bit30):阶码部分(指数部分),长度为8bit,采用移码的编码方式,偏移量为127。
比如,10进制数字“1”用偏移量为127的移码表示为:127+1=128=0x80=1000000b。
注:当阶码为全0时,表示非规格化数据,阶码表示十进制数(-126)。
尾数M(bit0~bit22):尾数部分(底数部分),采用二进制小数原码编码,小数点在最高位(bit22)之前。在规格化数据中,通过平移保证二进制个位为1,既该部分表示为1.xxxxxxxxxxxxxxxxxxxxxxxb, 比如10进制0.75,转化为二进制小数为0.11B,左移1位为1.1b,尾数仅取小数点后部分,尾数二进制表示为.10000000000000000000000b。 在非规格化数据中尾数二进制个位数为0。比如,非规格化尾数.10000000000000000000000b表示10进制数0.5。
二、取值分类
单精度(float类型)浮点分类如下表:
| 单精度分类 | 十进制Dex与Float类型的转换公式 | 数据个数 |
|---|---|---|
| 规格化数据 (阶码二进制值不全为0也不全为1,尾数补1) |
Dex=(-1)*S (1.0b+0.Mb)*2^(E-127) |
=4261412863个数据 注:+0和-0是不同的编码,故此处减去个1。 |
| 非规格化数据: (阶码二进制全为0,此时指数真值为:1-偏移量=1-127=-126,尾数没有补1) |
Dex=(-1)*S (0.Mb)*2^(-126) | 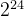 个数据 个数据 |
| 特殊值1 (阶码二进制为全1) |
尾数部分全0,符合位为0表示正无穷。 尾数部分全0,符合位为1表示负无穷。 |
2个数据 |
| 尾数不为0,表示NaN,不存在的数 | (-2)个数据 |
转换举例
例1:十进制10.75转换成float格式的编码
第一步:取符号位,10.75为正数,故符号位S为0。
第二步:将十进制数据转换为二进制,10.75=1010.11b。
第三步:二进制1010.11b右移3位为1.01011b。
阶码(指数)部分应该为3,用移码表示3:E=127+3=130=0x82H=10000010b,
尾数(底数)部分为.0011b,用原码表示为01011000000000000000000b,
将各部分组合后为:0 10000010 01011000000000000000000b。
例2:非规格化数据0 00000000 01011000000000000000000b转换成10进制
第一步:取符号位,符号位S为0,十进制为正数。
第二步:非规格化数据,阶码为-126。
第三步:计算尾数,尾数(底数)部分为.01011b=0.34375, 综合之后的10进制为0.34375 × 。
。
三、范围和精度
3.1 范围
| 功能位置 | 范围 |
| 符号S范围 | -1、1 |
| 指数E范围 | -126~127,注:非规格化数据的指数为-126 |
| 底数M范围 | 最大尾数:1.11111111111111111111111B=(2- 最小尾数:0.00000000000000000000000=0 最小非0尾数:0.00000000000000000000001= |
最大值:(2-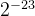 )×
)×![]() =(
=( 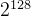 -
-![]() )≈3.402×
)≈3.402×![]()
最小值:-(2-)×![]() =-( -
=-( -![]() )≈-3.402×
)≈-3.402×![]()
最小非0正数: ×=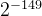
最大非0负数: -×=-
单精度浮点数(float)在内占32个bit,所以最多有 种组合方式,去掉特殊值和重复的数据,可以使用的有效数据为(--1)=4278190079个。我们在各个资料上看到浮点float数据的范围大约是-3.4E+38 ~ 3.4E+38,这个说法很笼统。换个说法可能更好理解,浮点float数是从 -( -
种组合方式,去掉特殊值和重复的数据,可以使用的有效数据为(--1)=4278190079个。我们在各个资料上看到浮点float数据的范围大约是-3.4E+38 ~ 3.4E+38,这个说法很笼统。换个说法可能更好理解,浮点float数是从 -( -![]() ) ~ ( -
) ~ ( -![]() )内抽出的4278190079个离散的数据。所以,单精度浮点数据是一组固定的离散数据集合,当我们给浮点类型的变量赋的值不在这个集合中时,就会造成了精度的损失。比如:给浮点变量赋值“float a=20.3;”,实际上a赋值后的值为20.2999992。
)内抽出的4278190079个离散的数据。所以,单精度浮点数据是一组固定的离散数据集合,当我们给浮点类型的变量赋的值不在这个集合中时,就会造成了精度的损失。比如:给浮点变量赋值“float a=20.3;”,实际上a赋值后的值为20.2999992。
3.2 精度
阶码的取值范围决定了浮点数范围的大小,而尾数(底数)部分则决定了数据精度的大小。从编码方式我们可以看出,单精度浮点规格化数据的最大误差应该为原始数据的![]() 倍,非规格化为 倍。很多资料中显示浮点有效数据为10进制的6~7有效数字,其实这个说法容易误解,只能说浮点可以表示的十进制位数是6~7位,但是因误差造成10进制退位的原因,并不能保证6~7位10进制数据的可靠性。比如:20.3赋值为浮点数据后会有一定的精度损失,再转换为10进制就成了20.29999924,虽然误差很小,但是因为误差导致的退位,仅能保证整数部分的正确。
倍,非规格化为 倍。很多资料中显示浮点有效数据为10进制的6~7有效数字,其实这个说法容易误解,只能说浮点可以表示的十进制位数是6~7位,但是因误差造成10进制退位的原因,并不能保证6~7位10进制数据的可靠性。比如:20.3赋值为浮点数据后会有一定的精度损失,再转换为10进制就成了20.29999924,虽然误差很小,但是因为误差导致的退位,仅能保证整数部分的正确。
综上所述正确的精度描述应该用二进制的位数表示:归格化数据可以保证24位二进制有效数据,最大误差为原始数据的![]() 倍。非规格化数据可以保证23位二进制有效数据 ,最大误差为原始数据的倍。
倍。非规格化数据可以保证23位二进制有效数据 ,最大误差为原始数据的倍。
四、运算方式:
4.1 加减法运算
浮点加减运算步骤如下:
1.对阶:调整小的数据,尾码向右平移,阶码增大,向大的数据进行对阶。
2.尾数运算:尾数进行加减运算,如果结果的整数部分不是1,计算阶码补偿。
3.阶码运算:阶码增加补偿。
例:解析运算 32.5-2.5
-2.5转化为float类型的编码为:1 10000000 01000000000000000000000b
32.5转化为float类型的编码为:0 10000100 00000100000000000000000b
步骤1 对阶:32.5的阶码比2.5大4;将2.5向32.5对阶,阶码加4,尾数向右平移4位,对阶结果为:0 10000100 00010100000000000000000b。
步骤2 底数相加: 32.5底数为1.000001b,符号为正;2.5对阶完成的底数为0.000101b,符号为负。1.000001b-0.000101b=0.1111b,
步骤3 补偿阶码并组合:将尾数0.1111b向左平移1位得到新的尾数.111b,同时将阶码减1后为10000011。最终结果为0 10000011 11100000000000000000000b=30.0。
4.2 乘除法运算
1.尾数运算:尾数进行乘除法运算,运算完成进行平移。
2.阶码运算:乘法运算阶码相加,除法运算阶码相减;再加上尾数结果平移的位数。
3.符号位确认。
五、常见的坑及处理方法
5.1 输出数据与输入数据不一致
比如:单晶度浮点赋值20.3,然后将该浮点打印输出,代码及打印结果如下,
float a=20.3f;
printf("%f\n",a)
为什么结果与预期不一样,就是因为20.3并不在浮点的数据集合中,编译器会选择最接近20.3的一个数据,这个数据的编码为0x41a26666,转化为10进制为20.2999992。
解决办法:通过四舍五入,保证有效位以内的10进制有效数字,代码及打印结果如下所示:
float a=20.3f;
a=a+0.00005;
printf("%.4f\n",a)
5.2 浮点数据的比较运算
在编码过程中最好不要使用浮点数据进行比较运算,因为浮点的精度损失会经常导致判断结果与预期不一致,尤其是“==”的比较运算。
浮点常量默认是双精度类型,单精度需要在数值后面加f,测试代码及结果如下所示:
#include
int main(void)
{
// 测试+0.0f和-0.0是否相等
float a = +0.0f;
float b = -0.0f;
if (a == b)
printf("+0等于-0\n");
else
printf("+0不等于-0\n");
// 测试20.3f和20.3是否相等
a = 20.3;
if (a == 20.3)
printf("20.3f等于20.3\n");
else
printf("20.3f不等于20.3\n");
// 测试20.0f和20.0是否相等
a = 20.0;
if (a == 20.0)
printf("20.0f等于20.0\n");
else
printf("20.0f不等于20.0\n");
// 测试20.3f-4.3f是否与17.0f相等
a = 20.3f; b= 4.3f;
if( (a-b) == 16.0f)
printf("20.3f-4.3f等于16.0f\n");
else
printf("20.3f-4.3f不等于16.0f\n");
} 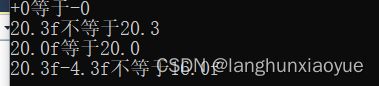
测试1:+0与-0编码不一样,但是数值一样。
测试2:浮点常量20.3默认是双精度(double)类型,20.3f为单精度(float)类型,“a=20.3;”会将20.3强制转换为单精度类型赋值给变量a,等同于"a=20.3f"。因为20.3并不在浮点数据集中,所以双精度(double)类型20.3转换为单精度(float)类型时会有精度损失,所以20.3f会小于20.3。“a==20.3”的比较运算,相当于将变量a强制转换为双精度(double)类型,再和20.3比较,等同于“(double)(20.3f)==20.3”的比较。
测试3:与测试2类似,但是我们选取的数据20.0在浮点的数据集合中,所以将20.0不管转换为双精度还是单精度都不会有精度损失,所以该测试结果相等。
测试4:20.3f转换为浮点编码为:0x41a26666,浮点再转换为10进制为20.29999992。
4.3f转换为浮点编码为:0x4089999a,浮点再转换为10进制为4.30000001。
(20.3f-4.3f)的编码结果为0x417fffff,转化为10进制为15.9999990。
不同数据在转成浮点时造成的精度损失不一定相同,而且编译器会选择最接近于该数据的编码,就造成浮点数据可能小于输入值,也可能大于输入值,所以两个浮点数据计算后的值不一定和预想值一样。
综上,最好不要使用浮点数据进行比较运算。
5.3.浮点数据与整形数据强制转换的问题
在数据通信中,经常会使用数组的方式缓存数据帧,我们在进行解帧时,遇到浮点数据如果直接赋值就存在数据类型强制转换的问题,导致数据接收失败。代码及结果如下所示:
#include
union date
{
unsigned int uresv;
float fresv;
};
int main(void)
{
float recv;
union date Trecv;
// 组帧
unsigned int iSend[16];
*((float*)(&iSend[0])) = 4.5f;
// 解帧方法1:直接赋值--错误
recv =(float)(iSend[0]);
printf("recv1=%f\n", recv);
// 解帧方法2:强制使用浮点地址--正确
recv = *((float*)(&iSend[0]));
printf("recv2=%f\n", recv);
// 解帧方法3:通过共用体转换--正确
Trecv.uresv = iSend[0];
recv = Trecv.fresv;
printf("recv3=%f\n", recv);
return 0;
} 
测试1:将报文中数据强制为float类型,这种方式得到的结果是错误的,因为强制转换导致原编码发生了变化。
测试2:将原始编码存储位置的地址强制为float类型指针,通过指针的方式读取数据,原编码不变,结果正确。
测试3:建立共用体,共用体中的变量取自同一存储位置,同一原编码,所以将报文通过无符号类型读取,再通过浮点转存,结果正确。
综上所述,在解析报文中的浮点数据时,可以使用浮点指针或共用体进行解析。
以上是对浮点数据的总结,希望对大家有所帮助!