机器学习 -- 余弦相似度
场景
我有一个 页面如下(随便找的):
我的需求是拿到所有回答的链接,
再或者我在找房子网上,爬到所有的房产信息,我们并不想做过多的处理,我只要告诉程序,请帮我爬一个类似 xxx 相似度为0.5的就可以了,然后我自会写一小段代码去给数据清洗,这就免去了每次不同网站写不同的一套脚本的痛苦。这里就用到了 余弦相似度。
余弦相似度
余弦相似度,又称为余弦相似性,是通过测量两个向量的夹角的余弦值来度量它们之间的相似性。两个方向完全相同的向量的余弦相似度为1,而两个彼此相对的向量的相似度为-1。 注意,它们的大小并不重要,因为这是方向的度量。
余弦定理:
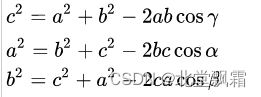
所以余弦的计算公式如下:

有向量 a,b 他们的余弦值的公式是:
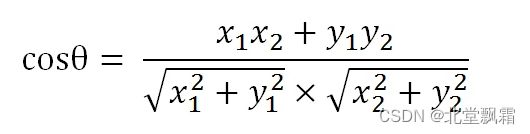
这个可能和k近邻算法听起来有些相似。但是也有不同
余弦相似度通常用于计算两个向量间的相似度,尤其常见于文本处理中。它通过测量两个向量间夹角的余弦值来判断它们的相似度。而k近邻算法是一种基于实例的学习或非泛化学习,它不试图构造一个通用内部模型,而是简单地存储实例数据。在分类时,新的数据点会被分配到它最近邻的类别。
所以余弦相似度更适合比较文本的相似程度,而k近邻算法常用于分类问题
优缺点
余弦相似度是一种测量两个向量在方向上的相似度的度量。它广泛用于文本分析,特别是在计算文档或文本片段之间的相似性时。
优点
1.不受大小影响:余弦相似度仅考虑向量间的角度,而不受其大小(即向量的长度或幅度)的影响,这使得它特别适用于文本数据,其中词频(长度)可能不是很重要。
2.效率较高:在稀疏数据集(如文本数据)上计算余弦相似度通常比其他相似度测量更高效。
适合高维数据:它适用于高维数据集,例如文本数据,其中每个维度代表一个不同的单词。
缺点
1.不考虑非共有特征:仅考虑两个向量共有的特征(即同时在两个向量中出现的元素),这可能会忽略某些重要信息。
2.对数据分布敏感:在某些情况下,数据的分布会影响余弦相似度的结果,尤其是当两个向量的长度相差悬殊时。
业务应用
1.获取html文本内容,我有两个html文件(获取html很容易,自动化和http请求都可以做到,但是要注意robot.txt协议),h6是一个整体的大html ,h7是案例html,我要拿的是 所有回答的链接,所以h7就是随机一个链接的html
file_path = 'D:/herche_ai/h6.html'
with open(file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
file_path = 'D:/herche_ai/h7.html'
with open(file_path, 'r', encoding='utf-8') as file:
target_html = file.read()
- 构建特征向量,我们利用BeautifulSoup将所有元素都趴下来,随后我们将其转为字符串表示
def build_feature_vector(html):
"""构建特征向量"""
soup = BeautifulSoup(html, 'html.parser')
elements = soup.find_all()
elements_str = [element_to_string(el) for el in elements]
return elements_str, elements
def element_to_string(element):
"""将元素转换为字符串表示"""
return f"{element.name} {' '.join([f'{k}={v}' for k, v in element.attrs.items()])}"
3.构建源html和目标html的特征
# 构建原始html特征向量
html_elements_str, html_elements = build_feature_vector(html)
# 构建目标html特征向量
target_elements_str, _ = build_feature_vector(target_html)
4.处理文本
vectorizer = CountVectorizer().fit(html_elements_str + target_elements_str)
CountVectorizer主要用于文本处理,它通过计数每个单词在文本中出现的频率来将文本转换为数值向量。这个过程可以分为以下几个步骤:
分词:将每个文本(在这种情况下是HTML元素的字符串表示)分割成单词或标记。
构建词汇表:从所有文本中提取出所有不同的单词,构建一个词汇表。
计数:对于每个文本,计算词汇表中每个单词的出现次数。
转换为向量:每个文本最终被转换为一个向量,向量的每个元素代表词汇表中对应单词的出现次数。
5.将两个html文本转为向量数值
html_vec = vectorizer.transform(html_elements_str)
target_vec = vectorizer.transform(target_elements_str)
6.比较相似度并且拿出相似度大于0.5的元素
similarities = cosine_similarity(target_vec, html_vec)
similar_elements = []
for index, similarity in enumerate(similarities[0]):
if similarity >= threshold:
similar_elements.append(html_elements[index])
return similar_elements
7.顺利拿到h6 html中所有和h7相似的元素
结束
余弦相似度应用爬虫场景结束