论文浅尝 | 以词-词关系进行分类的统一命名实体识别

笔记整理:曹旭东,东南大学硕士,研究方向为知识图谱构建、自然语言处理
链接:https://arxiv.org/abs/2112.10070
1. 动机
在以前的工作中,命名实体识别(NER)涉及的主要问题有三种类型,包括平面、重叠(也称为嵌套)和不连续的命名实体识别,这些类型大多分别研究。最近,对于统一的NER模型的研究越来越多,它只需一个模型,就可以同时处理上述三种问题。目前表现最佳的方法主要包括基于span的模型和sequence-to-sequence模型,然而,现有的最优方法都有着不足,前者主要关注边界识别,后者可能受到曝光偏差的影响。
为了继续提升统一NER的效果,文章提出了一种新颖的方法,将统一的NER建模为word-word关系分类,即W2NER。该架构通过有效地建模实体词之间的相邻关系,解决了统一的NER的核心瓶颈。基于W2NER方案,文章开发了一个神经框架,其中统一的NER被建模为一个单词对的2D网格。然后,提出了多粒度的2D卷积来更好地调整网格表示。最后,使用共同预测器充分推理单词之间的关系。
2. 贡献
文章的贡献有:
(1)提出了一种创新的方法,将统一的命名实体识别(NER)视为word-word关系分类,同时充分考虑了实体边界词之间的关系和实体内部词之间的关系;
(2)为统一的命名实体识别(NER)开发了一个神经网络框架,在其中提出了一种多粒度的二维卷积方法,以充分捕捉近距离和远距离单词之间的相互作用;
3. 方法
(1)将NER看作word-word关系分类
任务可以形式化如下: 给定一个由N个token或word组成的输入句子X = {x1, x2,…, xN},任务旨在提取每个标记对(xi, xj)之间的关系R,其中R是预定义的,包括NONE, Next-Neighboring-Word (NNW)和Tail-Head-Word-* (THW-*)。这些关系如图1所示的示例:
I am having aching in legs and shoulders

图1 关系分类示例
• NONE,表示该单词对在本文中没有定义任何关系。
• Next-Neighboring-Word(NNW):NNW关系表示该单词对属于一个实体
• Tail-Head-Word-*(THW):THW关系表示网格中某一行的单词是实体提及的尾部,而网格中某一列的单词是实体提及的头部。“*”表示实体类型。
在示例中,说明aching-in, in-legs, in-shoulders之间是NNW,aching-legs, aching-shoulders之间是THW-S(symptom)
(2)模型框架:如下图2所示为本文提出的统一的命名实体识别(NER)的神经网络框架W2NER。
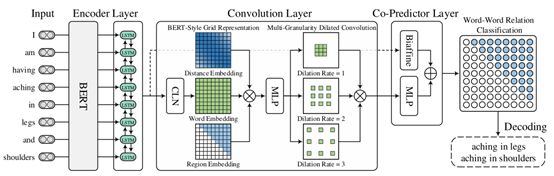
图2神经框架
框架的体系结构如图2所示,它主要由三个组件组成。
•编码器层:
利用BERT作为模型的输入。给定一个输入句子 ,将每个标记或单词 转换为词块,然后将它们输入预训练的BERT模块。经过BERT计算后,每个句子词可能包含几个片段的向量表示。为了进一步增强上下文建模,采用双向LSTM生成最终的单词表示。
•卷积层:
卷积层包括三个模块,包括一个具有规范化的条件层,用于生成词对网格的表示,一个BERT风格的网格表示构建,以丰富词对网格的表示,以及一个多粒度扩展卷积,用于捕获近词和远词之间的相互作用。
条件层:由于NNW关系和THW关系都是有方向的,因此,单词对 的表示 可以认为是 的表示 和 的表示 的组合,这种组合应该意味着 以 为条件。采用条件层归一化(Conditional Layer Normalization, CLN)机制来计算 :
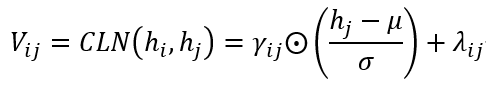
其中, 为产生层归一化增益参数 γαα 和偏置 λββ 的条件。µ和σ是 各元素之间的均值和标准差。
BERT风格的网格:在BERT的启发下,用类似的思路丰富了词对网格的表示,其中张量 表示单词信息,张量 表示每对单词之间的相对位置信息,张量 表示网格中用于区分上下三角形区域的区域信息。然后,将三种嵌入连接起来,并采用多层感知器(MLP)将其降维并混合这些信息,以获得网格 的位置区域感知表示。
多粒度扩展卷积:在TextCNN的启发下,采用不同扩展率l(例如,l∈[1,2,3])的多个二维扩展卷积(DConv)来捕捉不同距离的单词之间的相互作用。
•共同预测层:
同时使用Biaffine和MLP这两个预测器来计算两个独立的词对 的关系分布,并将它们组合起来作为最终的预测。
(3)损失函数
对于每个句子 ,的训练目标是最小化负对数似然损失形式化为:

其中N是句子中的单词数, 是表示单词对 的关系标签的二进制向量, 是预测的概率向量。r表示预定义关系集R的第r个关系。
4. 实验
(1)实验相关数据集
为了评估三个NER子任务框架,在14个数据集上进行了实验。
扁平的NER数据集有:CoNLL-2003,OntoNotes 5.0,OntoNotes 4.0,Weibo,Resume
实体重叠的NER数据集:ACE 2004中文和英文,ACE 2005中文和英文,GENIA
实体不连续的NER数据集:CADEC,ShARe13,ShARe14
选取的baselines有:Tagging-based方法,Span-based方法,Hypergraph-based方法,Seq2Seq方法等等。
(2)实验结果
对比实验:
在六个扁平数据集上评估框架。如表1所示,W2NER模型在CoNLL 2003和OntoNotes 5.0数据集上获得了93.07% F1和90.50% F1的最佳性能。W2NER模型在OntoNotes 5.0上的F1比另一个统一的NER框架高出0.23%。中文数据集的结果如表2所示,其中基线均为基于标注的方法。发现W2NER模型在OntoNotes 4.0、MSRA、Resume和Weibo上分别比之前的SoTA结果高出0.27%、0.01%、0.54%和1.82%。
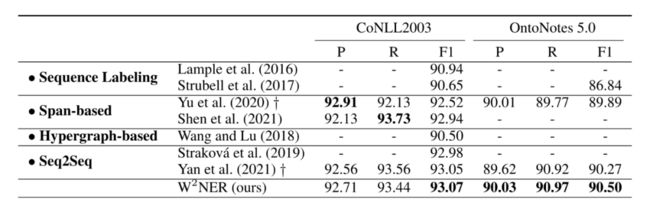
表1 英文扁平NER数据集的结果

表2 中文扁平NER数据集的结果
表3给出了重叠的NER数据集和不连续NER数据集的结果。W2NER模型优于以前的工作。
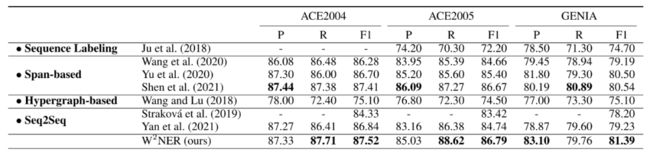
表3 英文重叠NER数据集的结果
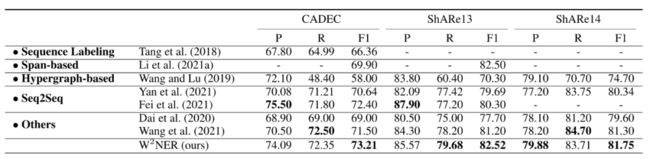
表4 不连续NER数据集的结果
消融实验:
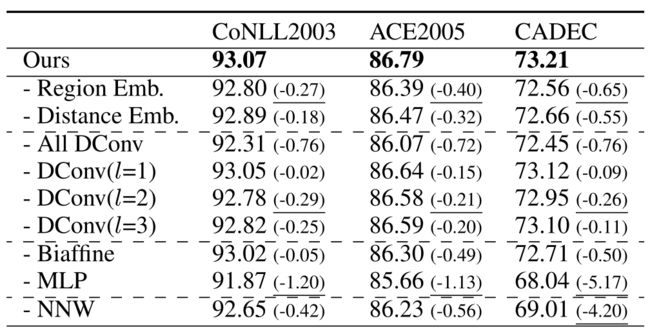
表5 消融实验结果
在CoNLL2003、ACE2005和CADEC数据集上消融了模型的各个部分。验证了多粒度扩展卷积的有效性,同时也证明了NNW关系对结果的重要性。
5. 总结
本文提出了一种对NER任务新颖的建模方法,看作word-word的关系预测,并且验证了NONE, Next-Neighboring-Word (NNW)和Tail-Head-Word-* (THW-*)的关系预测,可以很好的支撑NER的进行,同时解决了统一NER的问题,提出的新的模型表现优于已有模型。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。