【Storm实战】1.1 图解Storm的抽象概念
文章目录
- 0. 前言
- 1. Storm 中的抽象概念
-
- 1.1 流 (Stream)
- 1.2 拓扑 (Topology)
- 1.3 Spout
- 1.4 Bolt
- 1.5 任务 (Task)
- 1.6 工作者 (Worker)
- 2. 形象的理解Storm的抽象概念
-
- 2.1 流 (Stream)
- 2.2 拓扑 (Topology)
- 2.3 Spout
- 2.4 Bolt
- 2.5 任务 (Task)
- 2.6 工作者 (Worker)
- 场景1
- 场景2
- 3.参考文档
0. 前言
Storm 是一个分布式实时计算系统,用于处理大规模流式数据。它基于流处理模型,可以在一个分布式集群上运行,实时地处理和分析数据。Storm 提供了高可靠性、高吞吐量的数据流处理能力,可用于构建实时大数据分析应用和实时流处理任务。
在学习和使用 Storm 之前,我们需要对一些抽象概念有基本的了解。这些抽象概念包括流、拓扑、Spout、Bolt、任务和工作者。流是数据处理的基本单位,可以理解为一个无限的有序的元组序列。拓扑是一个由 Spout 和 Bolt 组成的数据流处理网络,定义了数据流从源头到最终目的地的路径。Spout 是数据源头,负责从外部源读取数据并封装成流。Bolt 是数据处理单元,负责接收输入流并进行处理。任务是在执行拓扑时运行在工作进程中的实际执行实例,每个 Spout 和 Bolt 组件可以配置为多个任务来实现并行处理。工作者是 Storm 运行在集群节点上的进程,可以执行一个或多个任务。
为了更好地理解这些抽象概念,可以将其类比为水力发电或水力传动系统。在这个类比中,流就像是河流,拓扑就像是水力发电系统,Spout 就像是水轮机,Bolt 就像是齿轮和发电机,任务就像是工人,工作者就像是工作站。
1. Storm 中的抽象概念
在学习Storm 之前,我们需要对Storm中的抽象概念有个基本的认识。方便我们后面写DEMO示例。
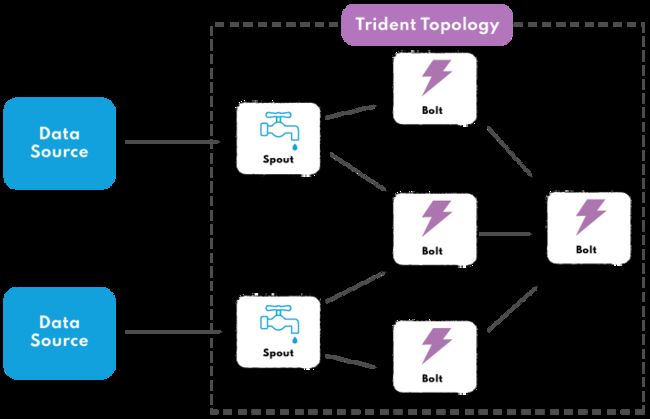
图片来源官方文档https://storm.apache.org/releases/2.6.0/Concepts.html
1.1 流 (Stream)
流是Storm中数据处理的基本概念。一个流可以理解为一个无限的、有序的元组(tuple)序列。在Storm中,元组是数据的基本单位,它是一个可以包含多种数据类型的键值对列表。流是可以在拓扑中的各个组件之间传输的。
1.2 拓扑 (Topology)
拓扑是Storm中最顶层的抽象,它定义了数据流从源头到最终目的地的整个路径。在Storm中,拓扑是由一系列的spouts和bolts组成的网络。Spouts用于生成数据流,而bolts则用于处理流经它们的数据。一旦提交到集群,拓扑将会不断运行,直到被显式地终止。
1.3 Spout
Spout是Storm拓扑中的数据源头,负责从外部源(如数据库、消息队列、文件系统等)读取数据并将其封装成流以供拓扑内的bolts处理。Spout可以发射多个流,并且能够对外部源的数据进行可靠或不可靠的读取。
1.4 Bolt
Bolt是拓扑中的数据处理单元,它负责接收来自spout或其他bolt的输入流,并进行处理,这些处理可以包括过滤、聚合、连接、写数据库等操作。处理完成后,bolt可以发射新的流到拓扑中的其他bolt进一步处理,或者将结果输出到外部系统。
1.5 任务 (Task)
在Storm中,任务是指在执行拓扑时,运行在工作进程中的实际执行实例。每个spout或bolt组件可以配置为多个任务来运行。任务数量决定了可用于处理数据的并行度。每个任务都会在集群某个节点的工作进程中的一个线程上执行。
1.6 工作者 (Worker)
工作者是Storm中运行在集群节点上的进程。工作者进程可以执行一个或多个任务。一个工作者进程只属于一个拓扑,但可以运行拓扑中多个任务(即,可以运行多个spout和bolt的实例)。通过分配更多的工作者进程,可以提高拓扑的并发度和处理能力。
以上概念构成了Storm的核心架构,理解它们可以帮助把握Storm的数据流处理和分布式计算模型。
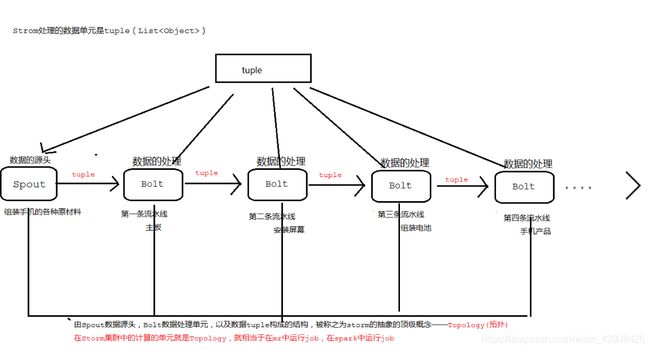
2. 形象的理解Storm的抽象概念
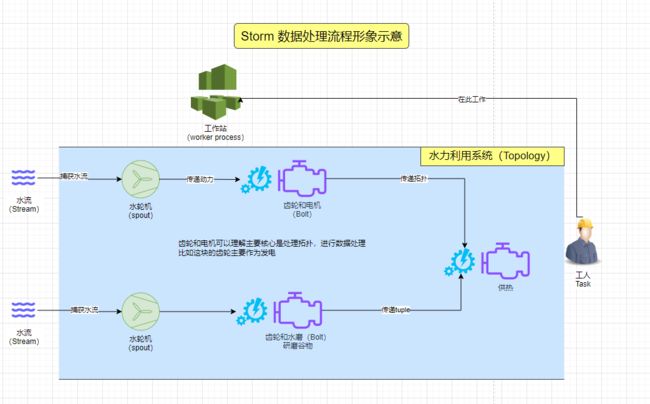
可能很多同学看完上面的概念和图,也感觉似懂非懂的。好吧,那么我们通俗的利用水力发电或者水力传动系统这种常见的模型,来理解Storm 抽象概念的设计思想。
我搞了一个图来类比解释Storm的概念,我相信大家应该会有一定的收获。
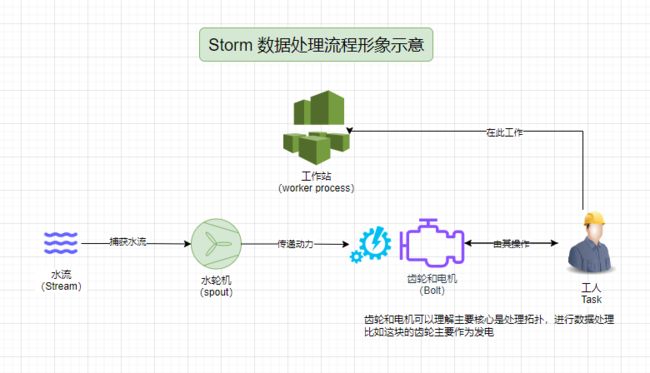
通过这个水力发电系统的比喻,我相信大家一定可以直观地理解Storm中的流、拓扑、Spout、Bolt、任务和工作者是如何协同工作处理数据的。
2.1 流 (Stream)
想象一条河流,河流不断地流动,携带着水分子(这里的水分子可以类比为数据的元组)。流在Storm中就像这条河流,是连续不断地数据(元组)序列。
2.2 拓扑 (Topology)
把拓扑想象成是一个水力发电系统。这个系统由水轮机(Spouts)和一系列的齿轮与发电机(Bolts)组成。水轮机从河流(Stream)中捕捉水流(数据流),然后通过一系列的齿轮(处理步骤)传输至发电机,最终产生电力(处理后的数据)。
2.3 Spout
Spout可以视为水力发电系统中的水轮机,它不断从河流(外部数据源)中截取水流,并开始推动整个系统的运作。在Storm中,Spout负责不断地捕获外部数据,并将其封装成流,供后续的Bolts处理。
2.4 Bolt
Bolt就像是沿着水轮机的齿轮和发动机,它们接收从水轮机传来的动力(元组),执行各种操作(处理数据),比如研磨谷物或发电。在Storm中,Bolts可以执行多种数据转换操作,如过滤、聚合、写入数据库等。
2.5 任务 (Task)
任务可以想象成是工人在水轮机和发电机之间的每个环节上工作。如果这个系统需要处理更多的水流(数据),我们就需要更多的工人(任务)。在Storm中,增加任务的数量可以提高系统处理数据的能力。
2.6 工作者 (Worker)
工作者可以看作是整个水力发电系统的工作站或工厂。在这些工作站里,每个工人(任务)负责操作一套齿轮与发动机(执行Spout和Bolt的逻辑)。工厂越多,系统的处理能力就越强。在Storm中,我们可以增加工作者(进程)的数量来扩展拓扑的处理能力。
场景1
基于水轮发电机的思想。假设水流过发电机Bolt 后,此处的水流还具有动力,那么我们是不是可以再串行接一个齿轮和管道,用来供热(处理数据)。这时候我们上面的处理结构就会变成。如下
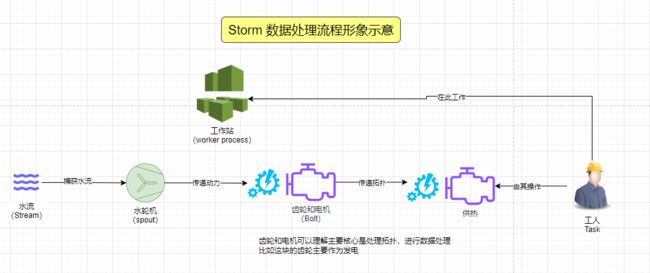
场景2
基于水轮发电机的思想。假设水流过发电机Bolt 后,此处的水流还具有动力,那么我们是不是可以再串行接一个齿轮和水磨,用来研磨谷物(处理数据),研磨完我们依然可以将水流分子(tuple)作为热源传递给供热管道(Bolt)进行供热处理。这时候我们上面的处理结构就会变成。如下
3.参考文档
storm 官方文档 https://storm.apache.org/releases/current/index.html