论文阅读《Efficient and Explicit Modelling of Image Hierarchies for Image Restoration》

论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Li_Efficient_and_Explicit_Modelling_of_Image_Hierarchies_for_Image_Restoration_CVPR_2023_paper.pdf
源码地址:https://github.com/ofsoundof/GRL-Image-Restoration
概述
图像复原任务旨在从低分辨率的图像(模糊,子采样,噪声污染,JPEG压缩)中恢复高质量的图像。图像复原是一个不适定的放问题,因为图像在退化过程中丢失了重要的信息。因此,图像复原任务需要充分挖掘低分辨率图像中的丰富信息。
自然场景下的图像包含全局、区域与局部三个尺度的信息。局部信息指的几个像素跨度的特征信息如边缘与局部颜色特征,这些信息可以通过小卷积核来获取。局部区域信息指几十个像素窗口的信息,该范围可以覆盖小物体与大物体部分(如图1中的粉红色框所示),这些信息可以通过transformer的窗口注意力机制来提取,相对于使用大卷积核,该方式可以节省模型参数。全局信息如图中青色部分所示,这些特征具有全局性,如对称性、多尺度的模式重复(图1a)、与同尺度的纹理相似性(图1b)、大物体与内容的结构相似性与一致性(图1c)。需要对图像的全局理解来捕获图像中的全局信息,挖掘图像的全局信息存在以下两个难点:现有基于卷积与窗口注意力的图像恢复网络使用固定的计算模式无法显式地捕获像素间的长程依赖信息。即图像中不同区域之间的相似性和一致性;高分辨率的图像会导致计算复杂度和内存占用的增加,因为需要对每一对像素进行比较和搜索。
文中聚焦于三个问题:如何有效地在高维图像中建模全局范围的特征,用于图像恢复;如何用一个单一的计算模块显式地建模图像的层次结构(局部、区域、全局);如何使这种联合建模的方法能够对不同的图像恢复任务有统一的性能提升。针对以上的问题,文中做出了三个创新性工作:
- 提出了锚定条纹自注意力(anchored stripe self-attention),提出了使用锚点(anchors)作为中间体来近似自注意力中的查询和键之间的精确注意力图。由于锚点将图像信息汇总到一个低维空间中,自注意力的空间和时间复杂度可以显著降低。此外,提出了在垂直和水平条纹内进行锚定自注意力。由于注意力范围的各向异性收缩,使得复杂度进一步降低。轴向条纹的组合也保证了对图像内容的全局视角。当配合条纹移位操作时,四种条纹自注意力模式(水平、垂直、移位水平、移位垂直)在计算复杂度和全局范围依赖建模能力之间达到了一个良好的平衡;
- 提出了一种新的Transformer结构GRL(Global, Regional, and Local),能够在单个计算模块中显式地建模全局范围、区域范围和局部范围的依赖。通过提出的锚定条纹自注意力、窗口自注意力和通道注意力增强卷积的并行计算,实现了图像的分层建模。
- 将提出的GRL应用到不同的图像恢复任务中并在多个任务上达到了新的最优性能。
Self-attention for dependency modelling
自注意力是一种可以对像素间长程依赖建模的方式:
Y = S o f t m a x ( Q ⋅ K T / d ) ⋅ V , (1) \mathbf{Y}=\mathrm{Softmax}\left(\mathbf{Q}\cdot\mathbf{K}^T/\sqrt{d}\right)\cdot\mathbf{V},\tag{1} Y=Softmax(Q⋅KT/d)⋅V,(1)
其中 Q = X ⋅ W Q , K = X ⋅ W K , V = X ⋅ W V , W Q , W K , W V ∈ R d × d \mathbf{Q}=\mathbf{X}\cdot\mathbf{W}_Q,\mathbf{K}=\mathbf{X}\cdot\mathbf{W}_K,\mathbf{V}=\mathbf{X}\cdot\mathbf{W}_V, \mathbf{W}_Q,\mathbf{W}_K,\mathbf{W}_V\in\mathbb{R}^{d\times d} Q=X⋅WQ,K=X⋅WK,V=X⋅WV,WQ,WK,WV∈Rd×d 且 X , Y ∈ R N × d \mathbf{X},\mathbf{Y}\in\mathbb{R}^{N\times d} X,Y∈RN×d。 N , d N, d N,d 分别代表token的数量与维度。 M = S o f t m a x ( Q ⋅ K T / d ) \mathbf{M}=\mathrm{Softmax}(\mathbf{Q}\cdot\mathbf{K}^{T}/\sqrt{d}) M=Softmax(Q⋅KT/d) 表示注意力权重图。传统自注意力的时间复杂度为 O ( N 2 d ) \mathcal{O}(N^2d) O(N2d),空间复杂度为 O ( N 2 ) \mathcal{O}(N^2) O(N2),其计算复杂度与显存消耗随着token的增长呈二次增长。针对该问题,文中提出了在一个窗口内进行自注意力的方法来降低显存消耗,窗口自注意力机制可以捕捉图像中不同区域之间的相互关系,而只能在一个较小的窗口范围内进行相似度比较,而不能考虑到更远距离的依赖关系,这可能会导致图像恢复的效果不佳。为了在控制计算成本的同时,保持对长距离依赖关系的建模能力,文中提出了一种锚定条带自注意力机制,它可以有效地在不同的尺度和方向上进行相似度比较。
Motivation I: cross-scale similarity
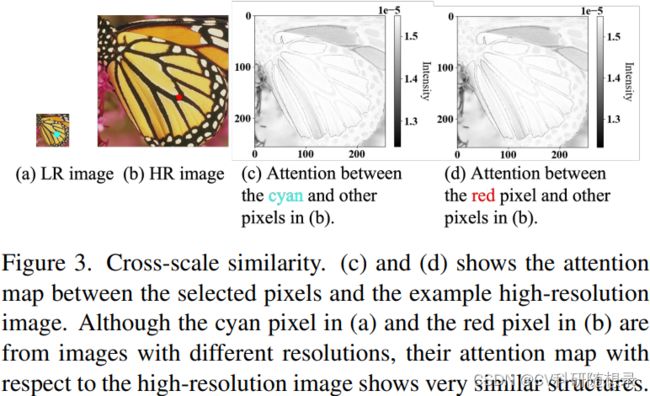
受启发于图像跨尺度相似性,自然图像中的基本结构,如线条与边缘在不同的缩放因子下都保持不变,如图3所示,无论像素来自高分辨率的图像还是降采样的图像,它们与高分辨率图像的热图都显示出图像的基本结构。
Anchored self-attention
为了降低全局自注意力的复杂度,文中在不同分辨率的特征图上进行自注意力,并引入锚点注意力。锚点是对图像中信息的综合,可以作为Query与Key之间想速度比较的中间变量,可以通过锚点来近视Q与K之间的注意力矩阵:
Y = M e ⋅ Z = M e ⋅ ( M d ⋅ V ) , M d = Softmax ( A ⋅ K T / d ) , M e = Softmax ( Q ⋅ A T / d ) , (2) \begin{aligned} \text{Y}& =\mathbf{M}_e\cdot\mathbf{Z}=\mathbf{M}_e\cdot\left(\mathbf{M}_d\cdot\mathbf{V}\right), \\ \mathbf{M}_{d}& =\text{Softmax}(\mathbf{A}\cdot\mathbf{K}^T/\sqrt{d}), \\ \mathbf{M}_{e}& =\operatorname{Softmax}(\mathbf{Q}\cdot\mathbf{A}^T/\sqrt{d}), \end{aligned}\tag{2} YMdMe=Me⋅Z=Me⋅(Md⋅V),=Softmax(A⋅KT/d),=Softmax(Q⋅AT/d),(2)
其中 M ≪ N , A ∈ R M × d M\ll N,\mathbf{A}\in\mathbb{R}^{M\times d} M≪N,A∈RM×d 为锚点。 M e ∈ R N × M \mathbf{M}_e\in\mathcal{R}^{N\times M} Me∈RN×M 与 M d ∈ R M × N \mathrm{M}_d\in\mathcal{R}^{M\times N} Md∈RM×N 代表 query-anchor 与 anchor-key 之间的注意力图。第一步是先对锚点和键进行自注意力,得到一个注意力矩阵 M d \mathbf{M}_{d} Md,它将键对应的值 V \mathbf{V} V压缩成一个中间特征 Z \mathbf{Z} Z。第二步是再对查询和锚点进行自注意力,得到另一个注意力矩阵 M e \mathbf{M}_e Me,它将中间特征 Z \mathbf{Z} Z扩展成输出特征 Y \mathbf{Y} Y,并且恢复了值 V \mathbf{V} V中的信息。锚点的数量比图像像素的数量要小得多,因此,通过锚点近似的两个注意力矩阵 M e \mathrm{M}_e Me和 M d \mathrm{M}_d Md比原始的注意力矩阵 M \mathrm{M} M小。时间复杂度降低到了 O ( N M d ) \begin{aligned}\mathcal{O}(NMd)\end{aligned} O(NMd),空间复杂度降低到了 O ( N M ) \begin{aligned}\mathcal{O}(NM)\end{aligned} O(NM)。
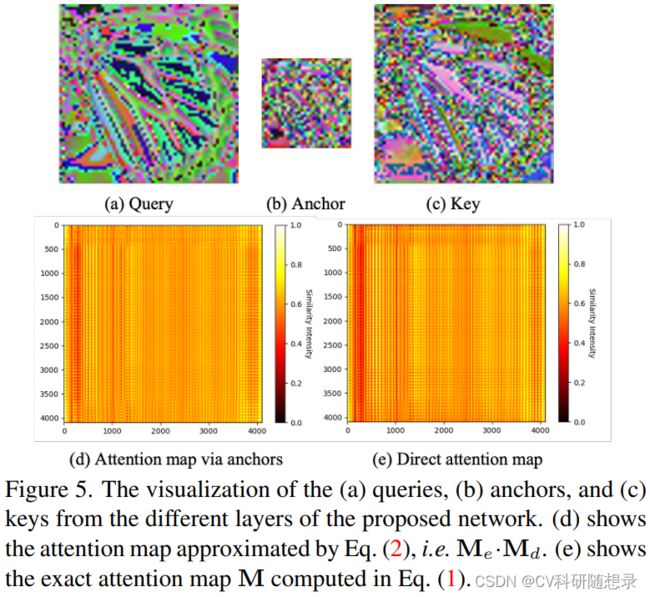
锚定自注意力具有低秩性的优点(低秩性是指一个矩阵的秩,即它的最大线性无关行或列的个数,远小于它的行数或列数。低秩性意味着一个矩阵可以用更少的参数来表示,从而节省存储空间和计算时间)。通过将注意力矩阵 M \mathrm{M} M被分解为两个较小的注意力矩阵 M d \mathrm{M_d} Md和 M e \mathrm{M}_e Me,它们的秩都不大于锚点的数量M。不需要先计算原始的注意力矩阵,就可以用更简单的方式来近似它。图5展示了查询、锚点和键的特征图,以及近似的注意力矩阵 M d \mathrm{M_d} Md和 M e \mathrm{M}_e Me和原始的注意力矩阵 M \mathrm{M} M。从图中可以看出锚点的特征图与查询和键的特征图非常相似,近似的注意力矩阵保留了原始注意力矩阵的主要结构,它们之间的皮尔逊相关系数为0.9505,锚点矩阵是对查询和键的信息的汇总。
Motivation II: anisotropic image features
图像的像素数量是图像的宽度和高度的乘积,这个乘积可能是一个很大的数,锚定自注意力的复杂度仍然很高。考虑到图像各向异性特征,如单个物体(图4c,d)、多尺度相似性(图4h)、对称性(图4e, g)等,它们在图像的不同方向上有不同的范围和分布,而不是均匀地覆盖整个图像。该特性可以减少不必要的相似度比较,从而节省计算资源。
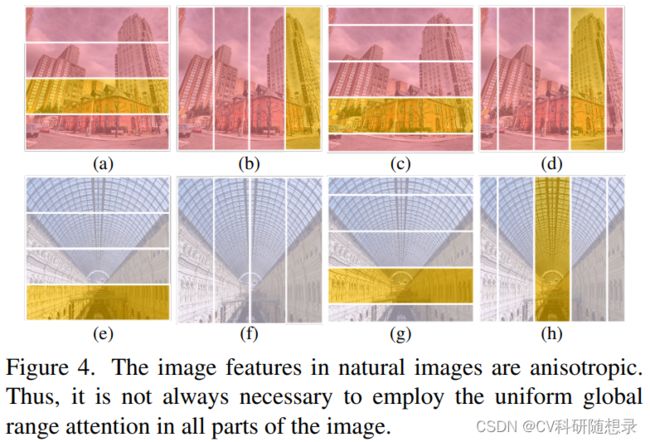
为此,文中提出在各向异性的条纹内进行自注意力的方法,即锚定条纹自注意力机制。这种方法将图像划分为水平和垂直的条纹,然后在每个条纹内使用锚点来近似自注意力。注意力的范围会根据图像特征的方向而收缩,从而降低复杂度。此外,通过组合不同方向的条纹,也能保证对图像内容的全局视角。当配合条纹移位操作时,四种条纹自注意力模式(水平、垂直、移位水平、移位垂直)在计算复杂度和全局范围依赖建模能力之间达到了一个良好的平衡。
在锚定自注意力机制中,查询和键先与锚点进行相似度比较,然后再通过锚点的相似度来近似查询和键之间的相似度,可视为相似性传播过程。利用锚点作为第三个元素,来简化查询和键之间的相似度计算。然而,该过程并不一定满足三角不等式的条件,因为查询和键之间的相似度是用点积而不是距离来定义的,而点积不一定是一个度量。通过逐渐移除或改变网络的一些组成部分,来观察网络的输出和性能的变化。这是一种常用的评估深度神经网络的有效性的方法。通过比较点积和距离作为相似度度量的效果,虽然点积不严格遵循三角不等式,但它仍然保证了更好的图像恢复结果。
模型架构
Modelling Image Hierarchies
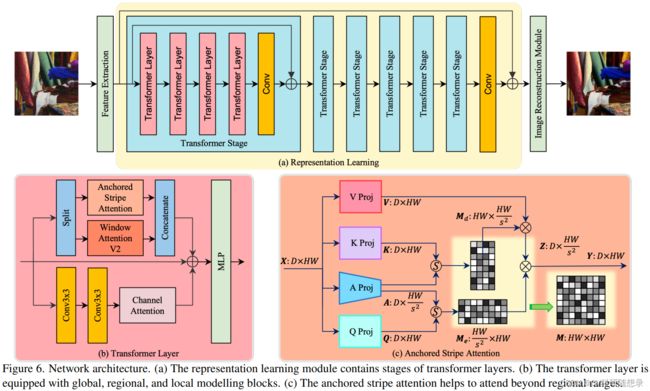
模型的整体架构如图6所示,它主要包含三个部分:特征提取层:将输入的图像转换为特征图;表征学习模块:该模块由多个Transformer组成,作用是丰富和优化特征图中的信息,使其能够更好地表达图像中的相似性和依赖关系。每个变换层都包含一个自注意力机制用于计算每个像素与其他所有像素之间的相似度。最后一层是一个卷积层,将多个Transformer的输出整合为一个特征图。在该模块中使用了跳跃连接(skip connection)用于避免信息的丢失和梯度的消失;图像重建模块:该模块将表征学习模块得到的特征图转换为一个恢复的的高质量的图像,可以更清晰地显示图像的内容和细节。
Transformer Layer.
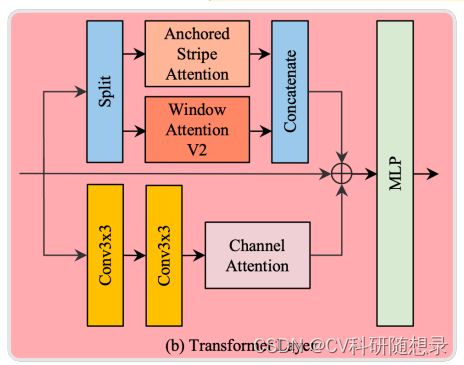
如上图所示,Transformer Layer为表征学习模块的核心部分,该模块可以提取图像中全局、区域和局部范围的上下文信息。先通过并行的自注意力模块和通道注意力增强的卷积来处理输入的特征图。卷积分支的作用是捕捉输入特征图中的局部结构。另一方面,自注意力模块包含了窗口注意力机制与锚点条纹注意力。首先将特征图沿着通道维度平均分割,然后在两个注意力模块内进行并行处理,再沿着通道维度重新拼接。窗口注意力提供了捕捉区域范围依赖关系的机制。然后,卷积模块和注意力模块输出的特征图与输入特征图相加,再由后续的MLP模块进行处理。
Anchored stripe self-attention
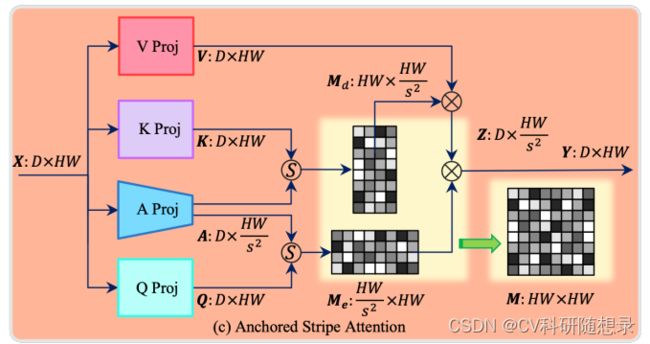
如上图所示,通过简单的线性投影得到 Q , K , V Q,K,V Q,K,V。为了将信息总结为锚点,锚点投影是实现为一个平均池化层,后面跟着一个线性投影。锚点投影之后,图像特征图的分辨率沿着两个方向缩小了一个因子 s s s。注意力图 M d \mathrm{M}_d Md和 M e \mathrm{M}_e Me与原始注意力图 M \mathrm{M} M起着类似的作用,但空间和时间复杂度更低。
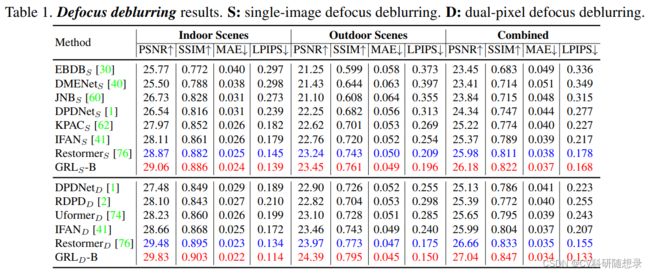
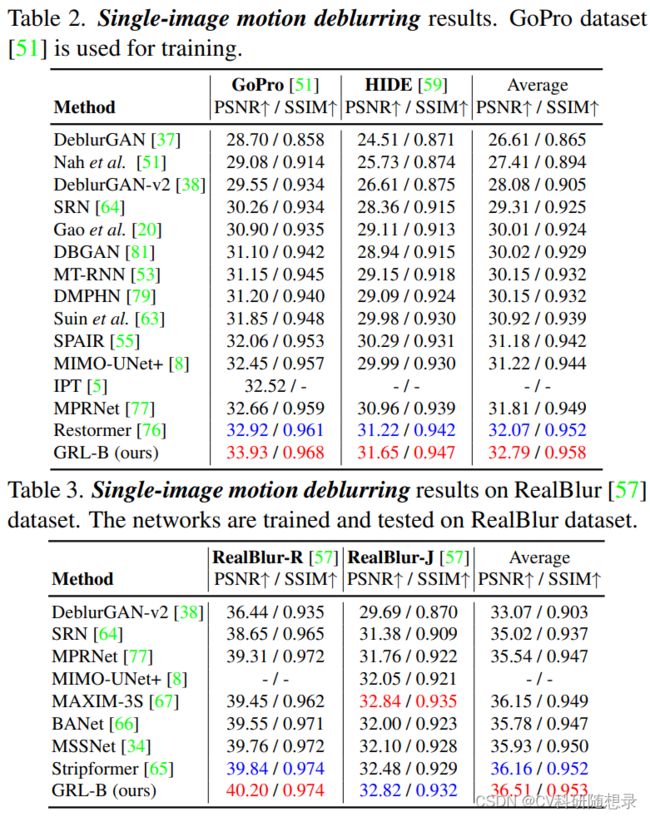
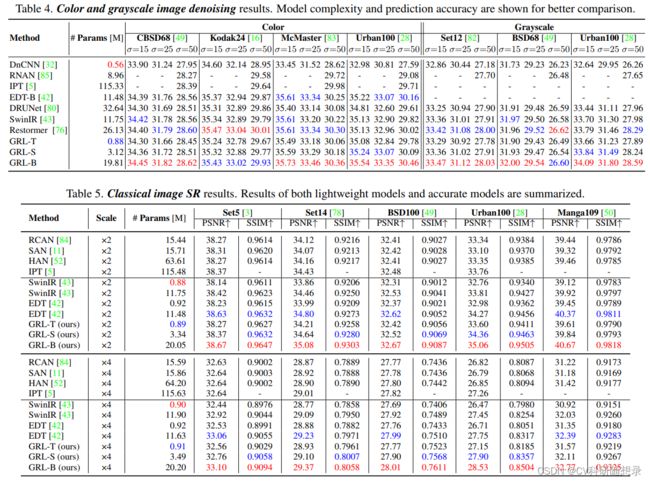
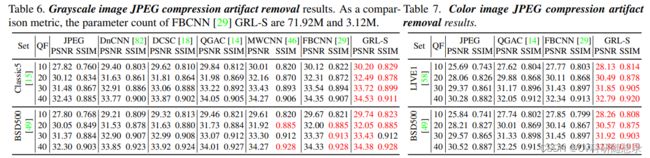
实验结果