模式识别与机器学习第一章
一、模式的概念
广义:存在于时间和空间中可观察的物体。如果可以区别它们是否相同或是否相似,都可以称之为模式。
狭义:模式所指的不是事物本身,而是从事物获得的信息,模式往往表现为具有时间和空间分布的信息。
模式的直观特性:可观察性、可区分性、相似性。
二、模式识别的概念
模式识别:直观,无所不在,“人以类聚,物以群分”。
目的:利用计算机对物理对象进行分类,在错误概率最小的条件下,使识别的结果尽量与客观物体相符合。
三、机器学习的概念
机器学习:研究如何构造理论、算法和计算机系统,让机器通过从数据中学习后可以进行如下工作:分类和识别事物、推理决策、预测未来等。
四、模式识别方法
模式识别系统的目标:在特征空间和解释空间之间找到一种映射关系,这种映射也称之为假说。
特征空间:从模式得到的对分类有用的度量、属性或基元构成的空间。
解释空间:将c个类别表示为![]() 其中 Ω 为所属类别的集合,称为解释空间。
其中 Ω 为所属类别的集合,称为解释空间。
机器学习的目标:针对某类任务T,用P衡量性能,根据经验来学习和自我完善,提高性能。
五、主要分类和学习方法
1.数据聚类(非监督学习,数据驱动)
用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据集。
2.统计分类(监督分类,概念驱动)
基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法。
3.结构模式识别
通过考虑识别对象的各部分之间的联系来达到识别分类的目的。识别采用结构匹配的形式,通过计算一个匹配程度值来评估一个未知的对象或未知对象某些部分与某种典型模式的关系如何。
4.神经网络(监督和非监督学习)
由一系列互相联系的、相同的单元(神经元)组成。相互间的联系可以在不同的神经元之间传递增强或抑制信号。 增强或抑制是通过调整神经元相互间联系的权重系数来实现。
5.监督学习(常用于分类和回归)
监督学习是从有标记的训练数据来推断或建立一个模型,并依此模型推测新的实例。 训练数据包括一套训练实例。在监督学习中,每个实例是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。
6.无监督学习(常用于聚类、概率密度估计)
无监督学习与监督学习的不同之处在于,事先没有任何训练样本,需要直接对数据进行建模,寻找数据的内在结构及规律,如类别和聚类。
7.半监督学习
是监督学习与无监督学习相结合的一种学习方法。主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。
半监督学习的主要算法有五类:基于概率的算法;在现有监督算法基础上改进的方法;直接依赖于聚类假设的方法;基于多视图的方法;基于图的方法。
8.增强学习
机器人选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈回来。 机器人根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。
9.集成学习
联合训练多个弱分类器并通过集成策略将弱分类器组合使用的方法。
常见的集成策略有:Boosting、Bagging、 Random subspace 、Stacking等。
常见的算法主要有:决策树、随机森林、Adaboost、GBDT、DART等。
10.深度学习
深度学习通过层次化模型结构可从低层原始特征中逐渐抽象出高层次的语义特征,以发现复杂、灵活、高效的特征表示。
常见的深度学习模型有:卷积神经网络, 递归神经网络,深度信任网络,自编码器,变分自编码器等。
11.元学习
利用以往的知识经验来指导新任务的学习,具有学会学习的能力。研究如何让元模型记忆理解以往学习知识,使算法能在小样本训练的情况下完成新任务的学习。
12.多任务学习
通过共享相关任务之间的表征,联合训练多个学习任务的学习范式。联系学习机制使不同任务的学习过程充分共享,可显著减少每个任务所需的训练样本。
多任务学习的主要形式有:联合学习、自主学习和带有辅助任务的学习。
13.多标记学习
所处理的数据集中的每个样本可同时存在多个真实类标。主要用于处理多种标签的语义重叠,如预测歌曲的音乐流派,预测图书、商品的属性标签。
多标记学习算法主要分为两类: 问题转换法:把多标签问题转为其它学习场景,比如转为二分类、标签排序、多分类等。 算法改编法:通过改编流行的学习算法去直接处理多标签数据,比如改编决策树、核技巧等。
14.对抗学习
主要通过恶意输入来误导机器学习算法或模型使其得到错误结果,并在该过程中暴露机器学习算法存在的脆弱性,帮助设计适应复杂环境的鲁棒学习方法。
六、系统构成
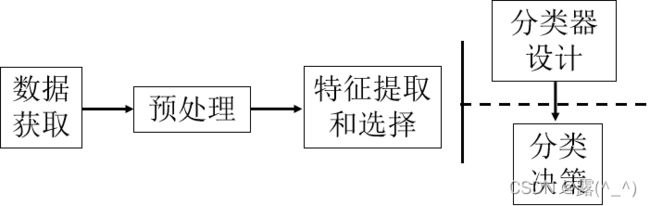
1.模式识别系统的基本构成
2.机器学习的基本构成

3.模式识别系统组成单元
数据获取:用计算机可以运算的符号来表示所研究的对象。
预处理单元:去噪声,提取有用信息,并对输入测量仪器或其它因素所造成的退化现象进行复原。
特征提取和选择:对原始数据进行变换,得到最能反映分类本质的特征。
- 测量空间:原始数据组成的空间
- 特征空间:分类识别赖以进行的空间
- 模式表示:维数较高的测量空间->维数较低的特征空间
分类决策:在特征空间中用模式识别方法把被识别对象归为某一类别。
基本做法:在样本训练集基础上确定某个判决规则,使得按这种规则对被识别对象进行分类所造成的错误识别率最小或引起的损失最小。
4.机器学习系统组成单元
环境:是系统的工作对象(包括外界条件),代表信息来源。
知识库:存储学习到的知识。
学习:是系统的核心模块,是和外部环境的交互接口。
执行:根据知识库执行一系列任务。
5.模式分类器的获取和评测过程
- 数据采集
- 特征选取
- 模型选择
- 训练和测试
- 计算结果和复杂度分析,反馈
七、数学概念
1.数学期望(均值)和方差 


2.协方差矩阵
协方差矩阵说明随机向量X的各分量的分散情况,定义为:
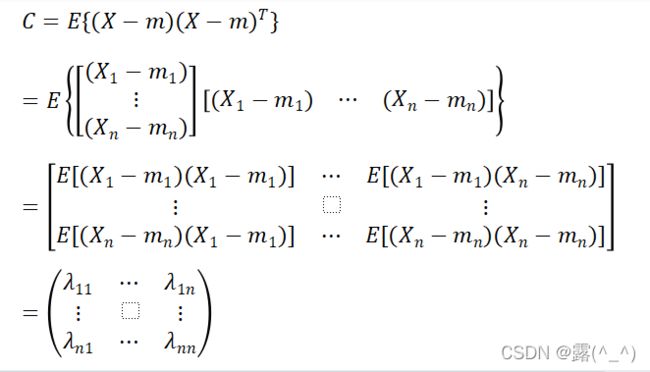
其中,协方差矩阵的各分量为:
3.一维正态密度函数(p(x) ~ N(m, σ2))

4.多维正态密度函数(p(x) ~ N(m, C))
