【BEV感知算法概述——下一代自动驾驶感知算法】
文章目录
-
- BEV感知算法概念
- BEV感知算法数据集介绍
- BEV感知算法分类
- BEV感知算法的优劣
- 小结
BEV感知算法概念
Bird’s-Eye-View,鸟瞰图(俯视图)。BEV感知算法存在许多的优势。
首先,BEV视图存在遮挡小的优点,由于视觉的透视效应,现实世界的物体在2D图像中很容易受到其他物体的遮挡,因此,传统的基于2D的感知方式只能感知可见的目标,对于被遮挡的部分算法将无能为力。
而在BEV空间内,时序信息可以很容易地被融合,算法可以基于先验知识,对被遮挡的区域进行预测,“脑补”出被遮挡的区域是否有物体。虽然“脑补”出来的物体固然有“想象”的成分,但对后续的控制模块来说,还是有不少益处。
此外,BEV感知算法的尺度变化小,将尺度相对一致的数据输入到网络中,可以得到更好的感知结果。
BEV感知算法数据集介绍
2.1 kitti-360数据集
kitti-360是一个包含丰富感官信息和完整注释的大规模数据集。我们记录了德国卡尔斯鲁厄的几个郊区,在73.7公里的驾驶距离内,对应超过32万张图像和10万个激光扫描。我们用粗糙的边界基元对静态和动态的三维场景元素进行注释,并将这些信息转移到图像领域,从而为三维点云和二维图像提供了密集的语义和实例注释。
为了收集数据,旅行车两边各配备了一个180°的鱼眼相机,前面一个90°的透视立体相机(基线60厘米)。此外,在车顶上安装了一个Velodyne HDL-64E和一个SICK LMS 200激光扫描装置,采用推杆式配置。这个装置与KITTI使用的装置类似,只是由于额外的鱼眼相机和推帚式激光扫描仪,获得了一个完整的360°视野,而KITTI只提供透视图像和Velodyne激光扫描,垂直视野为26.8°。此外,系统还配备了一个IMU/GPS定位系统。采集车的传感器布置如图所示。
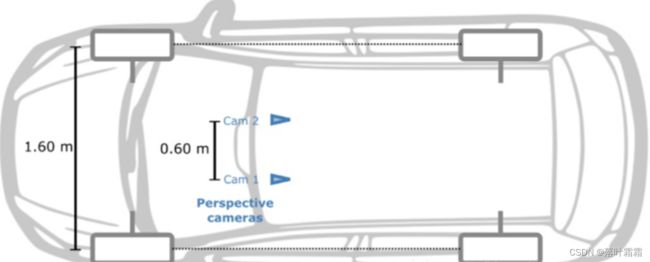
图1 Kitti-360数据集采集车
2.2 nuScenes数据集
nuScenes是第一个提供 自动汽车 全套传感器数据的大型数据集,包括了6个相机、1个激光雷达、5个毫米波雷达、以及GPS和IMU。与kitti数据集相比,其包含的对象注释多了7倍多。采集车的传感器布置如图所示。
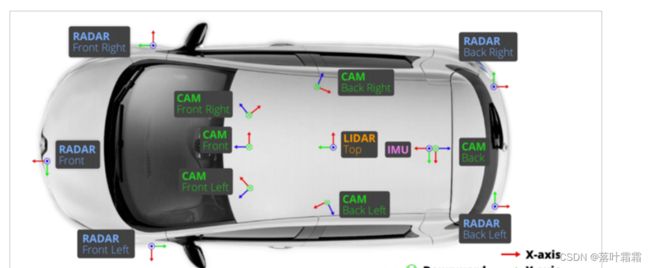
图2 nuScenes数据集采集车模型
BEV感知算法分类
基于输入数据,将BEV感知研究主要分为三个部分——BEV Camera、BEV LiDAR和BEV Fusion。下图描述了BEV 感知家族的概况。具体来说,BEV Camera表示仅有视觉或以视觉为中心的算法,用于从多个周围摄像机进行三维目标检测或分割;BEV LiDAR描述了点云输入的检测或分割任务;BEV Fusion描述了来自多个传感器输入的融合机制,例如摄像头、激光雷达、全球导航卫星系统、里程计、高清地图、CAN总线等。

如图所示,将自主驾驶的基本感知算法(分类、检测、分割、跟踪等)分为三个级别,其中BEV感知的概念位于在中间。基于传感器输入层、基本任务和产品场景的不同组合,某种BEV感知算法可以相应表明。例如,M2BEV和BEVFormer属于视觉BEV方向,用于执行包括3D目标检测和BEV地图分割在内的多项任务。BEVFusion在BEV空间设计了一种融合策略,同时从摄像机和激光雷达输入执行3D检测和跟踪。
BEV Camrea中的代表之作是BEVFormer。BEVFormer 通过提取环视相机采集到的图像特征,并将提取的环视特征通过模型学习的方式转换到 BEV 空间(模型去学习如何将特征从图像坐标系转换到 BEV 坐标系),从而实现 3D 目标检测和地图分割任务,并取得了 SOTA 的效果。
3.1 BEVFormer 的 Pipeline:
1)Backbone + Neck (ResNet-101-DCN + FPN)提取环视图像的多尺度特征;
2)论文提出的 Encoder 模块(包括 Temporal Self-Attention 模块和Spatial Cross-Attention 模块)完成环视图像特征向 BEV 特征的建模;
3)类似 Deformable DETR 的 Decoder 模块完成 3D 目标检测的分类和定位任务;
4)正负样本的定义(采用 Transformer 中常用的匈牙利匹配算法,Focal Loss + L1 Loss 的总损失和最小);
5)损失的计算(Focal Loss 分类损失 + L1 Loss 回归损失);
6)反向传播,更新网络模型参数;
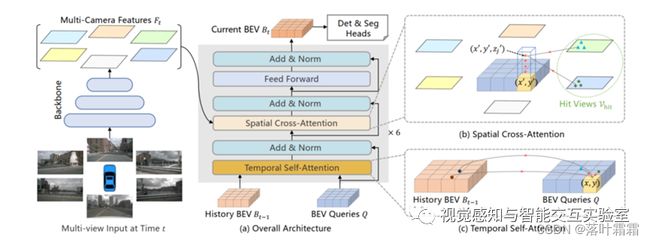
图4 BEVFormer框架图
BEVFusion算法离不开BEV LiDAR和BEV Camera算法,通常使用一个fusion模块进行点云和图像特征的融合。其中BEV Fusion是其中的代表之作。
3.2 BEVFusion的 Pipeline:
1)给定不同的感知输入,首先应用特定于模态的编码器来提取其特征;
2)将多模态特征转换为一个统一的BEV表征,其同时保留几何和语义信息;
3)存在的视图转换效率瓶颈,可以通过预计算和间歇降低来加速BEV池化过程;
4)然后,将基于卷积的BEV编码器应用到统一的BEV特征中,以缓解不同特征之间的局部偏准;
5)最后,添加一些特定任务头支持不同的3D场景理解工作。
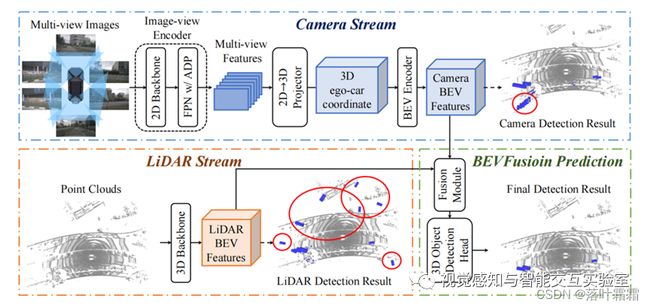
图5 BEV Fusion框架图
BEV感知算法的优劣
目前业界基于纯视觉的感知、预测算法研究通常仅针对上述流程中的单个子问题的image-view方案,如3D目标检测、语义地图识别或物体运动预测,通过前融合或后融合的方式将不同网络的感知结果进行融合。这导致了在搭建整体系统时只能以线性结构堆叠多个子模块。尽管上述方式能够实现问题分解、便于独立的学术研究,但这种串行架构具有几个重要的缺陷:
1)上游模块的模型误差会不断向下游传递,然而在子问题的独立研究中通常以真值作为输入,这使得累积误差会显著影响下游任务的性能表现。
2)不同子模块中存在重复的特征提取、维度转换等运算过程,但是串行架构无法实现这些冗余计算的共享,不利于提升系统的整体效率。
3)无法充分利用时序信息,一方面,时序信息可以作为空间信息的补充,更好地检测当前时刻被遮挡的物体,为定位物体的位置提供更多参考信息。另一方面,时序信息能够帮助判断物体的运动状态,在缺少时序信息的条件下,基于纯视觉的方法几乎无法有效判断物体的运动速度。
区别于image-view方案,BEV方案通过多摄像头或雷达将视觉信息转换至鸟瞰视角进行相关感知任务,这样的方案能够为自动驾驶感知提供更大的视野并且能够并行地完成多项感知任务。同时,BEV感知算法是要将信息融合到BEV空间中来,所以这有利于探索2D到3D的转换过程。
与此同时,BEV感知算法当前在3D检测任务上,与现有的点云方案有有差距。探索视觉BEV感知算法有利于降低成本。一套LiDAR设备的成本往往是视觉设备的10倍,所以视觉BEV是未来的真理,但同时带来的巨大数据量需要巨大的计算资源。
小结
总结起来,目前基于纯视觉的感知、预测算法研究通常只针对单个子问题进行处理,并通过融合不同网络的结果来构建整体系统。然而,这种串行架构存在一些重要的缺陷,如误差传递、冗余计算和缺乏时序信息利用等问题。
相比之下,BEV方案通过将视觉信息转换到鸟瞰视角,在自动驾驶感知中提供更广阔的视野,并能并行完成多项感知任务。同时,BEV感知算法可以将信息融合到BEV空间中,有助于探索2D到3D的转换过程。
然而,当前的BEV感知算法在3D检测任务上与点云方案相比仍存在差距。虽然视觉BEV具备降低成本的优势,但也带来了巨大的数据量和计算资源需求。因此,未来的研究需要解决这些挑战,以进一步提高BEV感知算法在自动驾驶中的应用。