国货之光,复旦发布大模型训练效率工具 CoLLiE,效率显著提升
在这个信息爆炸的时代,大型语言模型(LLM)成为理解和挖掘文本信息的重要工具。为了更好地适应各种应用场景,对 LLM 进行定制化训练变得至关重要。
在预训练 LLM 的过程中,无论是初学者还是经验丰富的炼丹人士,复旦大学研究团队提出的 CoLLiE 都能成为其趁手的工具。不管是追求高效的多 GPU 并行训练,还是想通过指令微调实现卓越性能,CoLLiE 在效率方面都能够脱颖而出。
论文题目:
CoLLiE: Collaborative Training of Large Language Models in an Efficient Way
论文链接:
https://arxiv.org/abs/2312.00407
Github 地址:
https://github.com/OpenLMLab/collie
工具包教程:
https://openlmlab-collie.readthedocs.io/zh-cn/latest/
LLM 在各种自然语言处理任务中展现出卓越的能力,而通过对其进行预训练,我们可以在特定应用场景中实现更出色的性能。如图 1 所示,训练过程可以分为两个阶段:
-
进一步预训练:用于补充特定领域知识,扩展词汇以提高分词效率;
-
指令微调:用于微调模型,使其适应下游任务并提高遵循指令的能力。

▲图1 预训练语言模型的两个训练阶段
随着语言模型规模的扩展,训练所需的资源显著增加,使得在单个 GPU 上训练整个模型变得困难。为了解决这个问题,模型并行性通过在不同 GPU 之间划分模型、在这些 GPU 之间分配训练工作负载。可以通过三种方法实现:
-
张量并行性:将模型的不同部分分配给不同的 GPU 进行训练;
-
流式并行性:将训练过程划分为多个阶段,每个阶段在不同 GPU 上执行;
-
零冗余优化器的第三阶段(ZeRO-3):使用零冗余优化器来实现模型的并行训练。
此外,在指令微调阶段存在参数高效微调(PEFT)方法,是资源效率和训练效果之间的权衡方法。通过选择性地选择或添加一些参数进行训练,有效降低了训练 LLM 所需的 GPU 内存。
本文作者提出了 CoLLiE,作为易于使用的协同 LLM 高效训练库,不仅整合了先前提到的三种并行策略和 PEFT 方法,还实现了高效的优化器。
对比当下流行的方法,CoLLiE 的训练效率更胜一筹,具备更高的训练吞吐量。此外,CoLLiE 还提供了多种功能,其模块化设计使得用户可以灵活组合并行策略、PEFT 方法和训练超参数,其设计注重可扩展性,旨在为用户提供灵活的定制功能。总之,CoLLiE 既能满足初学者的需求,也适用于经验丰富的专业人士。
CoLLiE
图 2(a) 概述了以 Trainer 类为中心的 CoLLiE 整体结构。CollieConfig、CollieModel、CollieDataset 和 Optimizer 类作为 Trainer 的输入。CoLLiE 还为 Trainer 提供了一组方便的插件,使用户能自定义训练过程。根据所配置和选择的插件,Trainer 执行训练过程,保存模型的检查点,并记录系统指标。
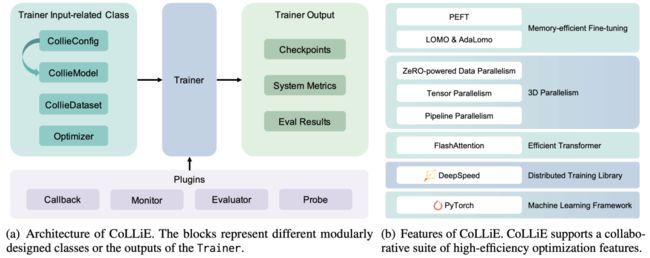
▲图2 CoLLiE 的整体架构和功能
根据图 2(b) 所示,CoLLiE 基于 PyTorch 和 DeepSpeed,各种技术协同来促进大型语言模型的有效训练。具体而言,CoLLiE 集成了 FlashAttention 以提升效率,实现了基于 ZeRO 的 DP(数据并行)、TP(模型并行)和 PP(流式并行),以支持 3D 并行性。此外,CoLLiE 还实现了内存高效的微调方法。
协同微调方法
-
3D 并行性:在分布式训练框架中同时利用数据并行性(Data Parallelism)、模型并行性(Model Parallelism)和流式并行性(Pipeline Parallelism)的一种训练方法。但 HuggingFace 中的模型由于结构限制只能选择 ZeRO-3 进行模型并行。为支持 3D 并行性,CoLLiE 采用 Megatron-LM 来重构模型,并根据 DeepSpee 对流式模型(pipeline model)结构的要求进行重组,这种方法的优势在于显著降低了用户学习曲线。
-
参数高效微调:CoLLiE 通过将 PEFT 库整合到其 CollieModel 中,填补了 PEFT 库在分布式训练方面的不足,使其能够更好地适应大规模分布式训练的需求。
-
高效优化器:CoLLiE 集成了多种新型优化器(Adan、Lion、Sophia、LOMO 和 AdaLomo 等),其目标是在训练过程中节省内存、改善优化结果或加速模型收敛。同时,CoLLiE 优化器的实现与其他组件解耦合,以便更灵活地进行组合和定制。
模型
此外,CoLLiE 在模型实现中做了一些改进,其中包括将自注意力替换为 FlashAttention,这是一种新的自注意力机制,然而,由于其对硬件和 CUDA 版本具有一定要求,因此 CoLLiE 在 CollieConfig 中添加了 'use_flash' 选项,用户可以通过该选项一键禁用 FlashAttention。
而且 CoLLiE 实现了各种开源语言模型(包括 LLaMA、InternLM、ChatGLM 和 MOSS),并计划在未来支持更多的语言模型。
配置
CoLLiE 提供了一个名为 CollieConfig 的统一配置类,用于管理多种配置(包括模型配置、并行策略、DeepSpeed 配置、PEFT 配置和训练超参数等)。CollieConfig 的内容可以方便地组合不同预训练语言模型、微调方法和超参数。
用户可以通过 CollieConfig 轻松设置模型结构和参数,而 CollieModel 和 Trainer 将根据 CollieConfig 的内容自动微调模型参数的分区和修改训练过程。这使得用户在使用 CoLLiE 时无需处理分布式训练的复杂性,而能够轻松配置 3D 并行性。
数据集
CoLLiE 提供了三个 Dataset 类,分别为训练任务、生成任务的评估和分类任务的评估提供了方便的数据处理功能:
-
CollieDatasetForTraining:
-
用于训练任务,可以接受两种形式的输入。一种是带有字段"text",另一种是带有字段"input"和"output"。
-
如果输入包含"text"字段,那么模型将进行预训练任务,并将计算 token 损失。
-
如果输入包含"input"和"output"字段,那么模型将进行指令微调任务,其中 token 损失将在"output"字段中计算。
-
-
CollieDatasetForGeneration:
-
用于生成任务的评估,"text"作为必需字段,"target"作为可选字段。
-
模型基于"text"生成输出,而"target"用于计算 Evaluator 中的指标。
-
-
CollieDatasetForClassification:
-
用于分类任务的评估,有"input"、"output"和"target"字段。
-
"input"字段表示问题,"output"字段包含所有可能的选项,而"target"字段表示应该选择哪个选项。
-
可以从 JSON 文件或字典列表读取数据,并在处理数据后将结果存储在磁盘上,以便下次直接读取。这使得数据处理变得方便且高效,提升了不同类型任务的灵活性。
控制器
作者还介绍了 CoLLiE 中围绕 Trainer 类的三个模块化设计的类:
-
Trainer:
-
Trainer 类用于管理分布式训练,包括分布环境的初始化、训练循环以及模型权重保存和检查点。
-
CoLLiE 提供了 Trainer 来简化用户的训练过程,封装了相对固定的训练循环,并为用户提供了多个接口,以定制训练过程。
-
Trainer 还支持插件,其中,Monitor 用于跟踪并记录在训练过程中的各种指标,而 Callback 在训练过程中的不同回调点进行自定义操作。
-
-
Evaluator:
-
Evaluator 类与 Metric 类一起用于评估模型性能。
-
CoLLiE 通过子类化 Evaluator 基类,实现了三种类型的Evaluator,用于生成任务、分类任务和困惑度评估。
-
Evaluator 的结果可用于更新 Metric 类,该类在处理评估数据集的每个批次后更新计算评估所需的变量。
-
-
Server:
-
Server 类提供基于 Web 的、交互式的、流生成序列的功能,使用户能方便地将训练好的模型部署到 Web 上进行使用,并在训练过程中手动探查模型性能。
-
DataProvider 类为 Server 提供异步推理数据作为子进程,用户可以通过 Web 界面输入提示,服务器根据提示生成输出,并返回到 Web 界面供用户查看。
-
它们使得 CoLLiE 更加模块化和灵活,用户可以根据自己的需求选择并定制相应的功能。
实验评估
内存需求
前人的工作估计了模型训练所需的总 GPU 内存为模型参数数量的 18 倍,这仅考虑了参数、梯度和优化器状态使用的内存,但没考虑其他组件。图 3 的展示了不同优化器对训练内存需求的影响,以及在选择优化器时需要考虑内存效率的重要性。
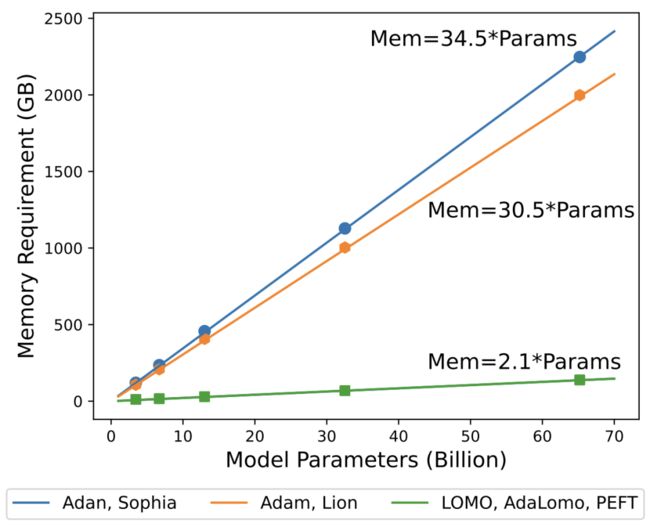
▲图3 在不同配置下训练模型时的内存需求
吞吐量分析
这项实验分析了预训练和微调阶段的吞吐量。吞吐量的度量标准是每个 GPU 每秒处理的标记数量,即 TGS(Tokens per GPU Second)。
如图 4 所示,CoLLiE 在不同硬件上通过集成 FlashAttention 和优化并行策略,在预训练和微调中实现了明显更高的吞吐量。
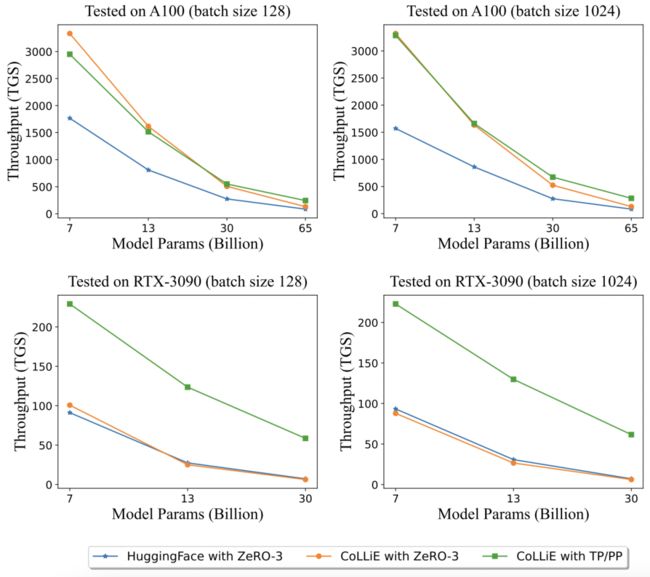
▲图4 在 A100 和 RTX-3090 上测试的吞吐量
指令微调任务的表现
表 1 中的实验结果显示了不同训练方法在 GPT-4-Alpaca 上的性能比较。原始 LLaMA-65B 在事实知识、推理能力、代码能力等方面表现出相当大的能力,但在遵循指令方面存在困难。通过进行指令微调,模型的性能平均显著提高。
由此可见,通过使用不同的训练方法,特别是结合指令微调,可以显著提升 GPT-4-Alpaca 在遵循指令方面的性能。
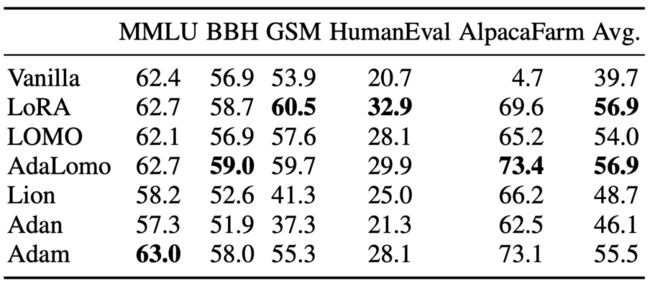
▲表1 在 GPT4-Alpaca 上比较不同训练方法
总结
最后,作为一个国产的大模型工具包,复旦大学研究团队提出的 CoLLiE,通过各项比较展示了其在协同大规模语言模型训练领域的卓越性能。CoLLiE 不仅集成了高效的模型结构和 FlashAttention 技术、支持 3D 并行性,而且提供了可定制的 Trainer,助力用户在训练过程中更灵活地使用各种训练方法。
CoLLiE 与流行工具的性能比较,展现了显著提高的训练吞吐量,以及其在 LLM 任务中的卓越性能。此外,CoLLiE 对 GPU 内存需求与模型参数大小的关系进行了深入剖析,为用户管理训练资源提供了实用的参考指南。相信 CoLLiE 以其卓越的性能和可定制性,可以为国产大模型工具树立新的标杆。