使用Pytorch从零开始构建LoRA
引言
在这篇博文中,我将向大家展示如何使用Pytorch从头开始构建 LoRA。LoRA 是Low-Rank Adaptation或Low-Rank Adapters的缩写,它提供了一种高效且轻量级的方法来微调预先存在的语言模型。这包括BERT和RoBERTa等掩码语言模型,以及GPT、Llama和Mistral等因果(或聊天机器人)模型。
LoRA的主要优点之一在于其效率。通过使用更少的参数,LoRA 显着降低了计算复杂性和内存使用量。这使我们能够在消费级 GPU 上训练大型模型,并轻松地将我们的紧凑型(以兆字节计)LoRA 分发给其他人。
此外,LoRA 可以提高泛化性能。通过限制模型的复杂性,它们有助于防止过度拟合,特别是在训练数据有限的情况下。这会产生更具弹性的模型,这些模型能够出色地处理新的、看不见的数据,或者至少保留初始训练任务中的知识。
此外,LoRA可以无缝集成到现有的神经网络架构中。这种集成允许以最小的额外训练成本对预训练模型进行微调和适应,使其非常适合迁移学习应用。
我们将首先深入研究 LoRA 的功能,然后演示如何从头开始开发RoBERTa模型,然后使用GLUE和SQuAD基准对我们的实现进行基准测试,并讨论一般技巧和改进。
LoRA 的工作原理
LoRA的基本思想是保持预训练矩阵(即原始模型的参数)冻结(即处于固定状态),只在原始矩阵中添加一个小的delta,其参数比原始矩阵少。
例如,考虑矩阵W,它可以是全连接层的参数,也可以是Transformer自注意力机制的矩阵之一:

显然,如果W -orig的维度为n×m,而我们只需初始化一个具有相同维度的新 delta 矩阵来进行微调,我们将一无所获;恰恰相反,我们会将参数加倍。
诀窍是通过低维矩阵B和A的矩阵乘法构造ΔW ,从而使 ΔW的“维数”小于原始矩阵。

我们首先定义一个等级r,显着小于基本矩阵维度r≪n和r≪m。那么矩阵B是n×r,矩阵A是r×m。将它们相乘会产生一个与W具有相同维度的矩阵,但由更少的参数计数构成。
显然,我们希望训练开始时的增量为零,这样微调就像原始模型一样开始。因此,B通常被初始化为全零,而A被初始化为随机(通常是正态分布)值。
例如,这可能看起来像这样:

想象一下我们的基本维度为 1024 并且我们选择 LoRA 等级r为 4 的情况:
- W有 1024 * 1024 ≈ 100 万个参数
- A和B各有 r * 1024 = 4 * 1024 ≈ 4k 个参数,总共产生 8k 个参数
- 因此,我们只需训练 0.8% 的参数即可用 LoRA 更新我们的矩阵
顺便说一句,在 LoRA 论文中,他们用 alpha 参数来衡量 delta 矩阵:
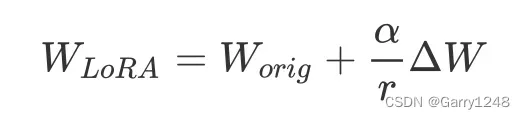
如果您只是将α设置为您实验的第一个r并微调学习率,您通常可以稍后更改r参数,而无需再次微调学习率(至少大约如此)。虽然我们在实现中可以忽略这个细节,但它是许多其他 LoRA 库的常见功能,例如 Hugging Face 的 PEFT。
实现LoRA
对于我们的实现,我们希望严格遵循原始 LoRA 论文。他们在那里测试了您实际需要更换的变压器矩阵。他们发现,在比较 GPT-3 微调任务的不同策略时,仅调整自注意力机制的查询和值向量就足够了。
请注意,现在许多人忽略了这种评估,并允许对每个矩阵进行微调,无论任务或模型如何(请参阅 QLoRA 论文)。
我们这里的实现将在 PyTorch 中完成,但应该可以轻松适应不同的框架。
对于这篇博文,我稍微简化了代码,使其更易于阅读,同时仍然显示了基本元素。完整的代码和一些经过训练的 LoRA 权重可以在这里找到: https: //github.com/Montinger/Transformer-Workbench。
重新实现自注意力模型
我们希望采用的模型是 Huggingface 的 RoBERTa 模型。最直接的方法就是重新包装原来的 self-attention 机制RobertaSelfAttention。然后新类LoraRobertaSelfAttention将初始化 LoRA 矩阵。所有 B 矩阵都将用零初始化,所有 A 矩阵将用正态分布的随机数初始化。
class LoraRobertaSelfAttention(RobertaSelfAttention):
"""
Extends RobertaSelfAttention with LoRA (Low-Rank Adaptation) matrices.
LoRA enhances efficiency by only updating the query and value matrices.
This class adds LoRA matrices and applies LoRA logic in the forward method.
Parameters:
- r (int): Rank for LoRA matrices.
- config: Configuration of the Roberta Model.
"""
def __init__(self, r=8, *args, **kwargs):
super().__init__(*args, **kwargs)
d = self.all_head_size
# Initialize LoRA matrices for query and value
self.lora_query_matrix_B = nn.Parameter(torch.zeros(d, r))
self.lora_query_matrix_A = nn.Parameter(torch.randn(r, d))
self.lora_value_matrix_B = nn.Parameter(torch.zeros(d, r))
self.lora_value_matrix_A = nn.Parameter(torch.randn(r, d))
给定这些矩阵,我们现在定义新的类方法lora_query和lora_value。这些计算ΔW矩阵,即BA,并将其添加到原始矩阵,我们从原始方法中调用query和value。
class LoraRobertaSelfAttention(RobertaSelfAttention):
# ...
def lora_query(self, x):
"""
Applies LoRA to the query component. Computes a modified query output by adding
the LoRA adaptation to the standard query output. Requires the regular linear layer
to be frozen before training.
"""
lora_query_weights = torch.matmul(self.lora_query_matrix_B, self.lora_query_matrix_A)
return self.query(x) + F.linear(x, lora_query_weights)
def lora_value(self, x):
"""
Applies LoRA to the value component. Computes a modified value output by adding
the LoRA adaptation to the standard value output. Requires the regular linear layer
to be frozen before training.
"""
lora_value_weights = torch.matmul(self.lora_value_matrix_B, self.lora_value_matrix_A)
return self.value(x) + F.linear(x, lora_value_weights)
要使用这些方法,我们必须覆盖RobertaSelfAttention. 虽然这有点硬编码(请参阅稍后有关改进的讨论),但它非常简单。首先,我们从https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py复制原始的前向代码。其次,我们将每次调用替换为queryby lora_query,并将每次调用替换为valueto lora_value。该函数如下所示:
class LoraRobertaSelfAttention(RobertaSelfAttention):
# ...
def forward(self, hidden_states, *args, **kwargs):
"""Copied from
https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py
but replaced the query and value calls with calls to the
lora_query and lora_value functions.
We will just sketch of how to adjust this here.
Change every call to self.value and self.query in the actual version.
"""
# original code for query:
## mixed_query_layer = self.query(hidden_states)
# updated query for LoRA:
mixed_query_layer = self.lora_query(hidden_states)
# The key has no LoRA, thus leave these calls unchanged
key_layer = self.transpose_for_scores(self.key(hidden_states))
# original code for value:
## value_layer = self.transpose_for_scores(self.value(hidden_states))
# updated value for LoRA:
value_layer = self.transpose_for_scores(self.lora_value(hidden_states))
# ... (rest of the forward code, unchanged)
我们已经完成了 LoRA-self-attention 的实现。现在剩下的唯一任务就是更换原始 RoBERTa 模型中的注意力模块。
更换模块
好吧,太好了,我们已经用我们自己的实现取代了 self-attention;但是我们如何将这个新类放入旧的 RoBERTa 模型中呢?本质上,我们必须循环遍历 RoBERTa 模型的每个命名组件,检查它是否属于 类RobertaSelfAttention,如果是,则将其替换为LoraRobertaSelfAttention,同时确保保留原始权重矩阵。
为了实现这一点,我们将编写一个新的包装函数来执行此替换。此外,我们还希望在以后的一些实际任务中添加对 RoBERTa 模型进行微调的功能
class LoraWrapperRoberta(nn.Module):
def __init__(self, task_type, num_classes=None, dropout_rate=0.1, model_id="roberta-large",
lora_rank=8, train_biases=True, train_embedding=False, train_layer_norms=True):
"""
A wrapper for RoBERTa with Low-Rank Adaptation (LoRA) for various NLP tasks.
- task_type: Type of NLP task ('glue', 'squad_v1', 'squad_v2').
- num_classes: Number of classes for classification (varies with task).
- dropout_rate: Dropout rate in the model.
- model_id: Pre-trained RoBERTa model ID.
- lora_rank: Rank for LoRA adaptation.
- train_biases, train_embedding, train_layer_norms:
Flags whether to keep certain parameters trainable
after initializing LoRA.
Example:
model = LoraWrapperRoberta(task_type='glue')
"""
super().__init__()
# 1. Initialize the base model with parameters
self.model_id = model_id
self.tokenizer = RobertaTokenizer.from_pretrained(model_id)
self.model = RobertaModel.from_pretrained(model_id)
self.model_config = self.model.config
# 2. Add the layer for the benchmark tasks
d_model = self.model_config.hidden_size
self.finetune_head_norm = nn.LayerNorm(d_model)
self.finetune_head_dropout = nn.Dropout(dropout_rate)
self.finetune_head_classifier = nn.Linear(d_model, num_classes)
# 3. Set up the LoRA model for training
self.replace_multihead_attention()
self.freeze_parameters_except_lora_and_bias()
正如您所看到的,我们在初始化中调用了两个辅助方法:
- self.replace_multihead_attention:这用我们之前写的替换了所有神经网络部分的注意力LoraRobertaSelfAttention
- self.freeze_parameters_except_lora_and_bias:这将冻结训练的所有主要参数,以便梯度和优化器步骤仅应用于 LoRA 参数以及我们希望保持可训练的其他偏差和层范数参数。
class LoraWrapperRoberta(nn.Module):
# ...
def replace_multihead_attention_recursion(self, model):
"""
Replaces RobertaSelfAttention with LoraRobertaSelfAttention in the model.
This method applies the replacement recursively to all sub-components.
Parameters
----------
model : nn.Module
The PyTorch module or model to be modified.
"""
for name, module in model.named_children():
if isinstance(module, RobertaSelfAttention):
# Replace RobertaSelfAttention with LoraRobertaSelfAttention
new_layer = LoraRobertaSelfAttention(r=self.lora_rank, config=self.model_config)
new_layer.load_state_dict(module.state_dict(), strict=False)
setattr(model, name, new_layer)
else:
# Recursive call for child modules
self.replace_multihead_attention_recursion(module)
我们必须递归地循环遍历所有模型部分,就像在 PyTorch 中网络部分可以(实际上是 RoBERTa)打包到单独的 PyTorch 模块中一样。
现在我们必须冻结所有不想再训练的参数:
class LoraWrapperRoberta(nn.Module):
# ...
def freeze_parameters_except_lora_and_bias(self):
"""
Freezes all model parameters except for specific layers and types based on the configuration.
Parameters in LoRA layers, the finetune head, bias parameters, embeddings, and layer norms
can be set as trainable based on class settings.
"""
for name, param in self.model.named_parameters():
is_trainable = (
"lora_" in name or
"finetune_head_" in name or
(self.train_biases and "bias" in name) or
(self.train_embeddings and "embeddings" in name) or
(self.train_layer_norms and "LayerNorm" in name)
)
param.requires_grad = is_trainable
此外,我们必须实现前向方法来考虑我们将要微调的任务,以及两种保存和加载 LoRA 权重的方法,以便我们可以加载先前训练模型的适配器。
Cliffhanger:有一种方法可以使代码变得更好并且更容易推广到其他网络架构(因为我们的代码非常硬编码到 RoBERTa 模型)。你能想到这可能是什么吗?您有时间思考这个问题,直到我们在下面的“可能的改进”部分中讨论它。但在那之前:让我们在一些基准测试上测试我们的实现是否真正有效。
使用 GLUE 和 SQuAD 对结果进行基准测试
我们的实现将使用 GLUE(通用语言理解评估)和 SQuAD(斯坦福问答数据集)基准进行评估。
GLUE 基准是一套包含八个不同 NLP 任务的套件,用于衡量语言模型的综合理解能力。它包括情感分析、文本蕴涵和句子相似性等挑战,为模型的语言适应性和熟练程度提供了可靠的衡量标准。
另一方面,SQuAD 专注于评估问答模型。它涉及从维基百科段落中提取答案,其中模型识别相关的文本范围。SQuAD v2 是一个更高级的版本,引入了无法回答的问题,增加了复杂性并反映了现实生活中的情况,模型必须在文本缺乏答案时进行识别。
请注意,对于以下基准测试,我没有调整任何超参数,没有执行多个符文(特别是较小的 GLUE 数据集容易产生随机噪声),没有做任何提前停止,也没有从微调开始之前的 GLUE 任务(通常这样做是为了减少小数据集噪声的可变性并防止过度拟合)。
一些细节:
- 从新初始化的 LoRA 注入开始,将等级 8 注入到 RoBERTa 基础模型中
- 每个任务的训练正好完成 6 个 epoch,没有任何提前停止。
- 在前 2 个 epoch 中,学习率线性上升到最大值,然后在剩余 4 个 epoch 中线性衰减到零。
- 所有任务的最大学习率为 5e-4。
- 所有任务的批量大小为 16
RoBERTa-base 模型有 1.246 亿个参数。有了 LoRA 参数、偏差和层规范,我们只有 42 万个未冻结的参数需要训练。这意味着我们实际上只使用原始参数的 0.34% 进行训练。
LoRA 针对这些特定任务引入的参数数量非常少,实际磁盘大小仅为 1.7 MB。您可以在 Git 存储库的Output文件夹中找到经过训练的 LoRA。
训练后,我们重新加载 LoRA 参数,重新应用它们,并在每个任务的验证集上测试性能。以下是结果:

通过一些超参数微调,这些结果可能会得到很大的改善。尽管如此,它清楚地证明了我们的 LoRA 实现正在发挥作用,并且我们注入的低秩矩阵正在学习。
可能的改进
反思我们的实现,人们可能会想:“是否有一种比重新编码自注意力类和执行复杂替换更有效、更通用(即可转移到其他网络架构)的方法?”
事实上,我们可以简单地在 pytorchnn.Linear函数周围实现一个包装器,并通过检查它们的名称来更具体地确定我们想要用它替换哪些层。同样,您可以围绕大多数基本 pytorch 层编写包装器,并能够快速使 LoRA 适应新的网络架构。快速概述一下如何做到这一点:
class LoraLinear(nn.Linear):
"""
Extends a PyTorch linear layer with Low-Rank Adaptation (LoRA).
LoRA adds two matrices to the layer, allowing for efficient training of large models.
"""
def __init__(self, in_features, out_features, r=8, *args, **kwargs):
super().__init__(in_features, out_features, *args, **kwargs)
# Initialize LoRA matrices
self.lora_matrix_B = nn.Parameter(torch.zeros(out_features, r))
self.lora_matrix_A = nn.Parameter(torch.randn(r, in_features))
# Freeze the original weight matrix
self.weight.requires_grad = False
def forward(self, x: Tensor) -> Tensor:
# Compute LoRA weight adjustment
lora_weights = torch.matmul(self.lora_matrix_B, self.lora_matrix_A)
# Apply the original and LoRA-adjusted linear transformations
return super().forward(x) + F.linear(x, lora_weights)
这实际上(接近)huggingface PEFT(参数高效微调)库实现 LoRA 的方式。对于任何您不想学习的实际应用程序,我强烈建议您使用它,而不是自己编写代码。
此外,将 LoRA 注入所有线性层(即所有自注意力矩阵和全连接前向网络的两个线性层)也成为一种相当普遍的做法。除了 LoRA 参数之外,保持偏差和层规范可训练通常是个好主意。由于它们已经很小,因此您不需要为它们进行低级注射。
量化原始矩阵权重以节省 GPU VRAM 也是可取的,这有助于在给定 GPU 上训练更大的模型。这可以使用位和字节库有效地完成,该库现在与 Hugging Face 完全集成(请参阅参考资料)。
总结一下,以下是关于LoRA的五诫:
- 利用 LoRA 进行高效的模型微调,重点是保持参数大小最小。
- 使用PEFT库进行LoRA实现,避免复杂的编码。
- 将LoRA适配扩展到所有线性层,增强整体模型能力。
- 保持偏差和层规范可训练,因为它们对于模型适应性至关重要并且不需要低阶适应。
- 应用量化 LoRA(QLoRA)来保留 GPU VRAM 并训练您的模型,从而能够训练更大的模型。
请记住,使用 QLoRA 进行训练可能比 LoRA 慢一点,因为它涉及在每次乘法期间对矩阵进行反量化。例如,在对 Llama-7B 等大型设备进行微调时,QLoRA 所需的 VRAM 减少约 75%,但与标准 LoRA 相比,速度慢约 40%。如需更多见解,请查看我在参考文献中链接的博文。
PEFT 实施分步指南
让我们看看如何真正遵守我们的命令并通过 PEFT 实现更好的版本。
首先,让我们以量化的方式加载我们的模型。得益于 BitsandBytes 与 Huggingface Transformers 库(于 2023 年 5 月推出)的集成,这变得轻而易举。
我们必须指定一个配置文件,然后通过此量化直接从 Huggingface 加载模型。一般来说,最好使用转换器中的AutoModel对象。将量化模型作为更大的新定义nn.module对象的子模块加载是很困难的。您通常应该使用 Huggingface 中的原始模型,从而直接导入AutoModelForSequenceClassificationGLUE 任务和AutoModelForQuestionAnsweringSQuAD 基准测试。在配置中,我们还可以指定不量化哪些参数:这里我们必须注册分类或 qa 输出头,因为我们想要完整地训练它们,即没有 LoRA,因为这些是新初始化的用于微调和从来都不是预训练基础模型的一部分。
import bitsandbytes as bnb
from transformers import AutoModel, AutoModelForSequenceClassification, BitsAndBytesConfig
# Configuration to load a quantized model
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # Enable 4-bit loading
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
llm_int8_skip_modules=['classifier', 'qa_outputs'], # Skip these for quantization
)
# Load the model from Huggingface with quantization
model = AutoModelForSequenceClassification.from_pretrained('roberta-base',
torch_dtype="auto", quantization_config=bnb_config)
您可以通过检查模型的模块和参数数据类型来验证 4 位加载:
# Verify 4-bit loading
print("Verifying 4-bit elements (Linear4bit) in the attention layer:")
print(model.roberta.encoder.layer[4].attention)
print("Checking for uint8 data type:")
print(model.roberta.encoder.layer[4].attention.self.query.weight.dtype)
现在使用 PEFT 注入 LoRA 参数。请注意,PEFT 库更加灵活,在处理自定义模型或其他复杂结构时也是如此,因此只要您只执行 LoRA 而不是 QLoRA(量化通常是棘手的部分)。
PEFT 库的目标是通过名称来替换模块;因此我们必须看一下模型model.named_parameters()。以下是非量化 roberta-base 模型的查找方式。
Module Parameters
---------------------------------------------------------- ------------
roberta.embeddings.word_embeddings.weight 38_603_520
roberta.embeddings.position_embeddings.weight 394_752
roberta.embeddings.token_type_embeddings.weight 768
roberta.embeddings.LayerNorm.weight 768
roberta.embeddings.LayerNorm.bias 768
roberta.encoder.layer.0.attention.self.query.weight 589_824
roberta.encoder.layer.0.attention.self.query.bias 768
roberta.encoder.layer.0.attention.self.key.weight 589_824
roberta.encoder.layer.0.attention.self.key.bias 768
roberta.encoder.layer.0.attention.self.value.weight 589_824
roberta.encoder.layer.0.attention.self.value.bias 768
roberta.encoder.layer.0.attention.output.dense.weight 589_824
roberta.encoder.layer.0.attention.output.dense.bias 768
roberta.encoder.layer.0.attention.output.LayerNorm.weight 768
roberta.encoder.layer.0.attention.output.LayerNorm.bias 768
roberta.encoder.layer.0.intermediate.dense.weight 2_359_296
roberta.encoder.layer.0.intermediate.dense.bias 3_072
roberta.encoder.layer.0.output.dense.weight 2_359_296
roberta.encoder.layer.0.output.dense.bias 768
roberta.encoder.layer.0.output.LayerNorm.weight 768
roberta.encoder.layer.0.output.LayerNorm.bias 768
roberta.encoder.layer.1.attention.self.query.weight 589_824
...
roberta.encoder.layer.11.output.LayerNorm.bias 768
classifier.dense.weight 589_824
classifier.dense.bias 768
classifier.out_proj.weight 1_536
classifier.out_proj.bias 2
---------------------------------------------------------- ------------
TOTAL 124_647_170
然后,我们可以指定为这些字符串选择的 LoRA 目标。检查它的全名中是否包含指定的子字符串。因此编写queryandvalue相当于我们上面从头开始的实现。对于密集层,我们必须更加小心,因为分类器也有密集输出。如果我们希望微调其他密集层,我们必须通过intermediate.dense和更加具体output.dense。
所有未注入 LoRA 参数的参数都会自动冻结,即不会接收任何梯度更新。如果我们想要以原始形式训练任何层,我们可以通过将列表传递给modules_to_saveLora-Config 的参数来指定它们。在我们的例子中,我们想要添加LayerNormGLUE 和 SQuAD 的此处和微调头。请注意,并非列表中的每个元素都必须匹配某些内容。我们可以简单地将classifier和添加qa_outputs到此列表中,然后拥有一个可以正确用于这两个任务的配置文件。
对于偏差参数,您可以使用方便的配置参数bias。您可以指定all来重新训练所有模块的所有偏差,lora_only来仅训练注入的模块,或者指定none来在训练期间保持所有偏差不变。
以下示例注入等级为 2 的 LoRA。我们使用上面的 8 指定 alpha 参数,因为这是我们首先尝试的等级,并且应该允许我们保留从头开始示例中的原始学习率。
import peft
# Config for the LoRA Injection via PEFT
peft_config = peft.LoraConfig(
r=2, # rank dimension of the LoRA injected matrices
lora_alpha=8, # parameter for scaling, use 8 here to make it comparable with our own implementation
target_modules=['query', 'key', 'value', 'intermediate.dense', 'output.dense'], # be precise about dense because classifier has dense too
modules_to_save=["LayerNorm", "classifier", "qa_outputs"], # Retrain the layer norm; classifier is the fine-tune head; qa_outputs is for SQuAD
lora_dropout=0.1, # dropout probability for layers
bias="all", # none, all, or lora_only
)
model = peft.get_peft_model(model, peft_config)
请记住,为 LoRA 注入指定更多模块可能会增加 VRAM 要求。如果您遇到 VRAM 限制,请考虑减少目标模块的数量或 LoRA 等级。
对于训练,尤其是 QLoRA 训练,请选择与量化矩阵兼容的优化器。用bitsandbytes变体替换你的标准torch优化器,如下所示:
import torch
import bitsandbytes as bnb
# replace this
optimizer = torch.optim.AdamW(args here)
# with this
optimizer = bnb.optim.AdamW8bit(same args here)
然后,你可以像以前一样训练该模型,而不必在训练期间明确担心 QLoRA。
训练完成后,保存和重新加载模型的过程非常简单。用于model.save_pretrained保存模型,指定所需的文件名。PEFT 库将自动在此位置创建一个目录,用于存储模型权重和配置文件。该文件包含基本模型和 LoRA 配置参数等基本详细信息。
要重新加载模型,请使用peft.AutoPeftModel.from_pretrained,将目录路径作为参数传递。要记住的关键一点是,LoRA 配置当前不保留已初始化的类的数量AutoModelForSequenceClassification。使用时from_pretrained,需要手动输入该类号作为附加参数。如果不这样做将会导致错误。
重新加载的模型将包含应用了 LoRA 适配器的原始基础模型。如果您决定将 LoRA 适配器永久集成到基本模型矩阵中,只需执行model.merge_and_unload().
如需更多实践理解和详细说明,请查看 GitHub 存储库。在那里,您将找到两个标题为Train-QLoRA-with-PEFT.ipynb和Load-LoRA-Weights-PEFT.ipynb 的笔记本,提供使用 PEFT 训练和加载模型的分步示例。
结论
在这篇博文里,我们从简单但硬编码的 LoRA 实现,到对LoRA的实际实现和基准测试有了更深入的了解。
我们探索了一种替代的、更高效的实施策略,并深入研究了现有库(例如用于 LoRA 集成的 PEFT)的优雅之处。
我们的冒险之旅以使用 LoRA 的实用指南结束,这些指南封装在“五诫”中,确保在实际应用中高效且有效地使用该技术,并提供有关如何在实践中实施这些技术的分步指南。
参考
- LoRA 论文原文:https://arxiv.org/pdf/2106.09685.pdf
- QLoRA 论文:https://arxiv.org/abs/2305.14314
- QLoRA 微调 Sentdex 指南:https://www.youtube.com/watch ?v=J_3hDqSvpmg
- 关于 Llama 上 LoRA 微调的博文:https://www.anyscale.com/blog/fine-tuning-llms-lora-or-full-parameter-an-in-depth-analysis-with-llama-2
- bitsandbytes 的huggingface集成:https://huggingface.co/blog/4bit-transformers-bitsandbytes
- LoRA 培训见解:https://lightning.ai/pages/community/lora-insights/
- 微调 Llama 模型时 LoRA 与 QLoRA 的预期 VRAM 节省:https://cloud.google.com/vertex-ai/docs/model-garden/lora-qlora