移动端轻量级模型开发谁更胜一筹,efficientnet、mobilenetv2、mobilenetv3、ghostnet、mnasnet、shufflenetv2驾驶危险行为识别模型对比开发测试
在实际的业务场景中,经常会需要考虑到硬件部署算力的因素,往往因为一些客观成本控制的问题,在实际项目开发中选择使用模型的时候往往会倾向于选择更为轻量级的模型来完成计算,但是也并非一味地轻量化,轻量化的同时还需要保证达到所需要的精度要求,本文选取了经常使用到的六款主流的识别模型,包括:efficientnet、mobilenetv2、mobilenetv3、ghostnet、mnasnet、shufflenetv2,以驾驶危险行为识别数据场景为基准,开发不同算法模型,进而对比分析不同模型的性能情况。
首先看下效果图:
这里囊括了上述的六种不同型号的识别模型。接下来我们依次来看下上述六种算法模型的内容:
【EfficientNet】
EfficientNet模型的算法构建原理是基于网络结构搜索(Neural Architecture Search)的方法来设计高效的卷积神经网络。其主要思想是通过自动搜索不同的网络结构,找到一个在计算资源有限的情况下,具有更好性能的模型。
具体来说,EfficientNet使用了一个复合系数(compound coefficient)来统一网络的宽度、深度和分辨率的缩放。通过对这个复合系数进行均匀的缩放,可以同时调整网络的宽度、深度和分辨率,使得模型在计算资源有限的情况下能够更好地平衡性能和计算效率。
EfficientNet模型的优点主要有以下几点:
-
高性能:EfficientNet通过网络结构搜索的方法,能够自动找到在计算资源有限情况下具有更好性能的模型。因此,相对于传统的手工设计的网络结构,EfficientNet能够取得更好的性能表现。
-
轻量化:EfficientNet在网络结构搜索过程中,不仅优化了网络的性能,还考虑了计算资源的限制。通过统一的复合系数,EfficientNet可以在不同的计算资源下进行缩放,从而设计出轻量级的模型,适用于计算资源受限的场景。
-
可迁移性:EfficientNet可以在不同的任务和数据集上进行迁移学习。由于EfficientNet在搜索过程中采用了一些通用的设计原则,因此在其他任务和数据集上使用EfficientNet作为基础模型,往往能够获得较好的性能。
虽然EfficientNet具有很多优点,但也存在一些缺点:
-
训练时间较长:EfficientNet的网络结构搜索过程需要消耗大量的计算资源和时间。在实际应用中,如果计算资源有限,可能需要花费较长的时间来搜索得到一个性能较好的模型。
-
网络结构复杂:EfficientNet的网络结构相对于传统的手工设计的网络结构来说,更加复杂。这使得EfficientNet的部署和推理过程相对较慢,特别是在计算资源有限的设备上。
EfficientNet模型通过网络结构搜索的方法,能够自动设计出高性能、轻量化且具有可迁移性的模型。然而,它的训练时间较长,网络结构较复杂,需要在实际应用中综合考虑这些因素。
【MobileNetv2】
MobileNetV2模型的算法构建原理是基于深度可分离卷积(Depthwise Separable Convolution)的方法来设计轻量级的卷积神经网络。其主要思想是通过将标准卷积分解为深度卷积和逐点卷积两个步骤,减少了参数数量和计算量,从而在计算资源有限的情况下实现高效的模型。
具体来说,MobileNetV2使用了一种称为倒残差结构(Inverted Residuals)的模块来构建网络。这种模块包括一个扩张卷积(Expansion Convolution)、一个深度可分离卷积和一个投影卷积(Projection Convolution)。通过这种模块的堆叠,MobileNetV2可以实现轻量级的网络结构。
MobileNetV2模型的优点主要有以下几点:
-
轻量化:MobileNetV2通过深度可分离卷积的方法,大幅减少了参数数量和计算量。相比于传统的卷积操作,MobileNetV2能够在保持较高性能的同时,显著减少模型的大小和计算资源的使用。
-
高效性能:尽管MobileNetV2是一个轻量级的模型,但它在多个图像分类和目标检测任务上都能够取得较好的性能。这得益于深度可分离卷积的特性,使得MobileNetV2能够在计算资源有限的情况下,仍然保持较高的准确率。
-
可迁移性:MobileNetV2可以在不同的任务和数据集上进行迁移学习。由于MobileNetV2的轻量化和高性能特点,它可以作为基础模型在其他任务和数据集上进行微调,往往能够获得较好的性能。
虽然MobileNetV2具有很多优点,但也存在一些缺点:
-
特征表示能力有限:由于MobileNetV2采用了深度可分离卷积,模型的信息传递能力有一定的限制。相对于一些更深层次的模型,MobileNetV2可能在某些复杂任务上表现不如其他模型。
-
对小目标的检测效果相对较差:由于MobileNetV2的网络结构相对较浅,对于小目标的检测效果可能不如一些更深层次的模型。这是因为MobileNetV2在网络深度上的限制导致了它在捕捉细节和小尺寸目标方面的能力较弱。
MobileNetV2模型通过深度可分离卷积的方法,实现了轻量化和高效性能的模型。然而,它可能在特征表示能力和对小目标的检测效果方面存在一定的限制。在实际应用中需要综合考虑这些因素来选择合适的模型。
【MobileNetv3】
MobileNetV3模型的算法构建原理是在MobileNetV2的基础上进一步改进,主要采用了两种关键技术:候选网络结构搜索和网络结构设计。
候选网络结构搜索阶段使用了网络结构搜索算法,通过对大量的候选网络结构进行评估和选择,找到更优的网络结构。这个搜索过程主要考虑了三个方面的指标:准确率、模型大小和计算量。通过权衡这些指标,可以得到更加高效的网络结构。
在网络结构设计阶段,MobileNetV3引入了两个关键的组件:移动块(MobileNetV3 block)和倒置残差结构(Inverted Residuals)。移动块是MobileNetV3的基本构建单元,它由一系列的卷积操作和激活函数组成,能够有效地捕捉图像的特征。倒置残差结构则通过扩张卷积(Expansion Convolution)和逐点卷积(Pointwise Convolution)的组合,实现了更深的网络结构和更好的特征表示能力。
MobileNetV3模型的优点主要有以下几点:
-
高性能:MobileNetV3在网络结构搜索和设计过程中,充分考虑了准确率、模型大小和计算量等指标。通过权衡这些指标,MobileNetV3能够在保持较高性能的同时,显著减小模型的大小和计算资源的使用。
-
高效率:MobileNetV3采用了移动块和倒置残差结构等关键组件,能够有效地提取图像特征。相对于传统的卷积神经网络,MobileNetV3在相同计算资源下能够取得更好的性能,具有更高的计算效率。
-
多样性:MobileNetV3提供了多个不同的模型系列,包括MobileNetV3 Large和MobileNetV3 Small等。这些不同的系列可以根据具体应用场景和计算资源的限制进行选择,具有较好的灵活性和可扩展性。
然而,MobileNetV3也存在一些缺点:
-
训练时间较长:由于MobileNetV3的网络结构搜索过程需要消耗大量的计算资源和时间,因此在实际应用中,可能需要花费较长的时间来搜索得到一个性能较好的模型。
-
部署和推理速度较慢:MobileNetV3的网络结构相对较复杂,导致在部署和推理过程中需要更多的计算资源。特别是在计算资源有限的设备上,可能会影响模型的部署和实时推理效果。
MobileNetV3模型通过候选网络结构搜索和网络结构设计的方法,实现了高性能和高效率的模型。然而,它的训练时间较长,部署和推理速度较慢,需要在实际应用中综合考虑这些因素。
【GhostNet】
GhostNet模型的算法构建原理是通过引入Ghost Module(幽灵模块)来设计高效的卷积神经网络。Ghost Module的提出主要是为了解决轻量化模型在准确率和计算效率之间的平衡问题。
Ghost Module的核心思想是通过使用一个主幽灵卷积核和若干个辅幽灵卷积核来减少参数数量和计算量。主幽灵卷积核用于提取主要的特征信息,而辅幽灵卷积核则用于学习细节和辅助信息。通过这种方式,GhostNet能够在保持较高准确率的同时,显著减少了模型的大小和计算资源的使用。
GhostNet模型的优点主要有以下几点:
-
轻量化:GhostNet通过引入Ghost Module,大幅减少了参数数量和计算量。相比于传统的卷积操作,GhostNet能够在保持较高性能的同时,显著减小模型的大小和计算资源的使用。
-
高效性能:尽管GhostNet是一个轻量级的模型,但它在多个图像分类和目标检测任务上都能够取得较好的性能。Ghost Module的设计使得GhostNet能够在计算资源有限的情况下,仍然保持较高的准确率。
-
可迁移性:GhostNet可以在不同的任务和数据集上进行迁移学习。由于GhostNet的轻量化和高性能特点,它可以作为基础模型在其他任务和数据集上进行微调,往往能够获得较好的性能。
虽然GhostNet具有很多优点,但也存在一些缺点:
-
特征表示能力有限:由于GhostNet采用了Ghost Module的结构,模型的信息传递能力有一定的限制。相对于一些更深层次的模型,GhostNet可能在某些复杂任务上表现不如其他模型。
-
对小目标的检测效果相对较差:由于GhostNet的网络结构相对较浅,对于小目标的检测效果可能不如一些更深层次的模型。这是因为GhostNet在网络深度上的限制导致了它在捕捉细节和小尺寸目标方面的能力较弱。
GhostNet模型通过引入Ghost Module来实现轻量化和高效性能的模型。然而,它可能在特征表示能力和对小目标的检测效果方面存在一定的限制。在实际应用中需要综合考虑这些因素来选择合适的模型。
【MnasNet】
在设计一个模型搜索算法时,有三个最重要的点:
1、优化目标:决定了搜索出来的网络框架的性能和效率;
2、搜索空间:决定了网络是由哪些基本模块组成的;
3、优化策略:决定了强化学习的收敛速度。
MnasNet模型的算法构建原理是通过使用弱连接搜索算法和自动化网络设计方法来构建高效的卷积神经网络模型。MNasNet的搜索空间很大程度上参考了MobileNet v2,通过强化学习的方式得到了超越其它模型搜索算法和其参照的MobileNet v2算法,从中可以看出人工设计和强化学习互相配合应该是一个更好的发展方向。MNasNet中提出的层次化搜索空间可以生成每个网络块都不通的网络结构,这对提升网络的表现也是有很大帮助的,但这点也得益于参考MobileNet v2设计搜索空间后大幅降低的搜索难度。

在弱连接搜索算法中,MnasNet使用了一种基于弱连接的搜索策略,通过在网络的每个位置引入弱连接,然后通过选择性地增加和删除连接来搜索网络结构。这种方法可以显著减少搜索空间并提高搜索效率。
在自动化网络设计方法中,MnasNet使用了一种自动化的网络设计方法来优化网络结构。该方法通过定义一组可行的操作和权重空间,并使用强化学习算法来搜索最优的网络结构。这种方法可以自动地学习网络结构,并在保持高性能的同时减少模型的大小和计算资源的使用。
MnasNet模型的优点主要有以下几点:
-
高性能:MnasNet通过使用弱连接搜索算法和自动化网络设计方法,能够搜索和设计出高性能的卷积神经网络。这些网络在多个图像分类和目标检测任务上展示了较好的性能。
-
轻量化:MnasNet在网络设计过程中考虑了模型的大小和计算资源的使用。通过自动化网络设计方法,MnasNet能够减少模型的大小和计算量,从而在保持高性能的同时实现轻量化。
-
可扩展性:MnasNet的自动化网络设计方法具有较强的可扩展性。它可以根据不同的任务和数据集进行自动化的网络设计,并能够适应不同的计算资源限制和应用场景需求。
然而,MnasNet也存在一些缺点:
-
训练时间较长:由于MnasNet使用了自动化网络设计方法,需要在大规模的搜索空间中进行搜索和训练,因此训练时间较长。
-
部署和推理速度较慢:由于MnasNet的网络结构相对较复杂,导致在部署和推理过程中需要更多的计算资源。特别是在计算资源有限的设备上,可能会影响模型的部署和实时推理效果。
MnasNet模型通过弱连接搜索算法和自动化网络设计方法构建了高性能和轻量化的模型。然而,它的训练时间较长,部署和推理速度较慢,需要在实际应用中综合考虑这些因素。
【ShuffleNetV2】
ShuffleNetV2模型的算法构建原理是通过引入逐通道组卷积和通道重排操作来设计高效的卷积神经网络。它的核心思想是通过在网络中引入通道重排操作,从而减少模型的计算量和参数数量。
ShuffleNetV2模型的构建原理主要包括以下几个步骤:
-
分组卷积:将输入特征图按通道分成多个组,并对每个组进行卷积操作。这样可以减小计算复杂度和参数数量。
-
逐通道组卷积:在每个分组内,使用逐通道的卷积操作进行特征图的变换。这样可以增加特征之间的交互,提高特征表示能力。
-
通道重排:将分组卷积后的特征图进行通道重排操作,将特征图重新排列为原始通道的形式。这样可以保持特征图的多样性,并提高特征图的表达能力。
ShuffleNetV2模型的优点主要有以下几点:
-
轻量化:ShuffleNetV2通过引入逐通道组卷积和通道重排操作,减少了模型的计算量和参数数量。相比于传统的卷积操作,ShuffleNetV2能够在保持较高性能的同时,显著减小模型的大小和计算资源的使用。
-
高效性能:尽管ShuffleNetV2是一个轻量级的模型,但它在多个图像分类和目标检测任务上都能够取得较好的性能。逐通道组卷积和通道重排操作的引入使得ShuffleNetV2能够在计算资源有限的情况下,仍然保持较高的准确率。
-
可扩展性:ShuffleNetV2的设计具有较强的可扩展性。通过调整分组数和通道数的大小,可以根据不同的计算资源限制和应用场景需求,设计出适合的模型。
然而,ShuffleNetV2也存在一些缺点:
-
特征表示能力相对有限:由于ShuffleNetV2采用了逐通道组卷积和通道重排操作,模型的信息传递能力有一定的限制。相对于一些更深层次的模型,ShuffleNetV2可能在某些复杂任务上表现不如其他模型。
-
对小目标的检测效果相对较差:由于ShuffleNetV2的网络结构相对较浅,对于小目标的检测效果可能不如一些更深层次的模型。这是因为网络深度的限制导致了它在捕捉细节和小尺寸目标方面的能力较弱。
ShuffleNetV2模型通过引入逐通道组卷积和通道重排操作来实现轻量化和高效性能的模型。然而,它可能在特征表示能力和对小目标的检测效果方面存在一定的限制。在实际应用中需要综合考虑这些因素来选择合适的模型。
接下来看下本文使用到的数据情况:

共收集构建了包含十种不同的驾驶行为,如下所示:

对应的算法模型开源社区都有很多相应的实现,可以根据自己的实际需要选择使用对应的项目即可,这里因为大家的偏好不同选择的项目也会有所不同,就不再赘述了,仅以GhostNet模型为例看下实现代码:
# encoding:utf-8
from __future__ import division
"""
__Author__:沂水寒城
功能: GhostNet
"""
import torch
import torch.nn as nn
import math
import numpy as np
from torch.hub import load_state_dict_from_url
from utils.utils import load_weights_from_state_dict
def _make_divisible(v, divisor, min_value=None):
"""
参考
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class SELayer(nn.Module):
"""
SE Layer
"""
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.clamp(y, 0, 1)
return x * y
def depthwise_conv(inp, oup, kernel_size=3, stride=1, relu=False):
"""
DW
"""
return nn.Sequential(
nn.Conv2d(
inp, oup, kernel_size, stride, kernel_size // 2, groups=inp, bias=False
),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
class GhostModule(nn.Module):
"""
Ghost
"""
def __init__(
self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True
):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels * (ratio - 1)
self.primary_conv = nn.Sequential(
nn.Conv2d(
inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False
),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(
init_channels,
new_channels,
dw_size,
1,
dw_size // 2,
groups=init_channels,
bias=False,
),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1, x2], dim=1)
return out[:, : self.oup, :, :]
class GhostBottleneck(nn.Module):
"""
GhostBottleneck
"""
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False)
if stride == 2
else nn.Sequential(),
SELayer(hidden_dim) if use_se else nn.Sequential(),
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, 3, stride, relu=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
class GhostNet(nn.Module):
"""
GhostNet
"""
def __init__(self, cfgs, num_classes=1000, width_mult=1.0):
super(GhostNet, self).__init__()
self.cfgs = cfgs
output_channel = _make_divisible(16 * width_mult, 4)
layers = [
nn.Sequential(
nn.Conv2d(3, output_channel, 3, 2, 1, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
)
]
input_channel = output_channel
block = GhostBottleneck
for k, exp_size, c, use_se, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 4)
hidden_channel = _make_divisible(exp_size * width_mult, 4)
layers.append(
block(input_channel, hidden_channel, output_channel, k, s, use_se)
)
input_channel = output_channel
self.features = nn.Sequential(*layers)
output_channel = _make_divisible(exp_size * width_mult, 4)
self.squeeze = nn.Sequential(
nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=False),
nn.BatchNorm2d(output_channel),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1)),
)
input_channel = output_channel
output_channel = 1280
self.classifier = nn.Sequential(
nn.Linear(input_channel, output_channel, bias=False),
nn.BatchNorm1d(output_channel),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x, need_fea=False):
if need_fea:
features, features_fc = self.forward_features(x, need_fea)
x = self.classifier(features_fc)
return features, features_fc, x
else:
x = self.forward_features(x)
x = self.classifier(x)
return x
def forward_features(self, x, need_fea=False):
if need_fea:
input_size = x.size(2)
scale = [4, 8, 16, 32]
features = [None, None, None, None]
for idx, layer in enumerate(self.features):
x = layer(x)
if input_size // x.size(2) in scale:
features[scale.index(input_size // x.size(2))] = x
x = self.squeeze(x)
return features, x.view(x.size(0), -1)
else:
x = self.features(x)
x = self.squeeze(x)
return x.view(x.size(0), -1)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def cam_layer(self):
return self.features[-1]
本文使用到的六种不同型号的模型在训练层面保持完全相同的训练参数配置,接下来来整体看下对比效果。
首先我们来看不同模型训练过程中loss对比:

可以直观看到:不同型号的模型对比训练损失差异不大。
接下来来看测试集上的loss对比:

这里测试集损失差异整体也不大,只有MNasNet略高。
接下来我们来看训练精度对比:
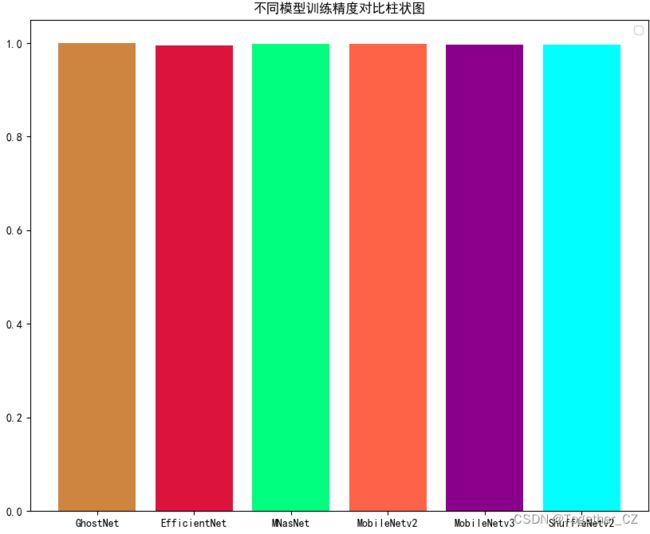
整体比较稳定持平。
接下来我们来看测试集精度对比:

可以看到:在精度指标上训练集和测试集的表现差别基本一致。
为了整体来对比分析,这里绘制了六种模型在整个训练集和测试集上的精度对比和损失对比,如下所示:
【综合精度对比】

【综合损失对比】

整体综合来看:效果最优的模型就是GhoshNet了。不过其他模型的表现也不错。
最后我们整体来对比计算下所有模型在不同类别上的准确率和平均准确率,如下所示:

从结果上来看与上述的分析结论维持一致。
感兴趣的话都可以自行尝试动手实践一下,可能能有不一样的结果。