超参数设定及训练技巧
一、网络超参数的设定
1.输入数据像素大小的设定:
为便于GPU并行计算,一般将图像大小设置为到2的次幂。
2.卷积层参数的设定:
(1)卷积核大小一般使用1*1,3*3 或 5*5。
(2)使用zero padding,可以充分利用边缘信息、使输入大小保持不变。
(3)卷积核的个数通常设置为2的次幂,如64,128,256,512,1024等。
3.池化层参数的设定:
一般采用卷积核大小2*2,步长为2.
4.全连接层参数的设定(可使用Global Average Pooling来代替):
主要是用来解决全连接的问题,是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量,然后进行softmax中进行计算。
备注:
(1)Global Average Pooling和Average Pooling(Local)的差别就在“Global”这个字眼上。Global和Local在字面上都是用来形容pooling窗口区域的。Local是取Feature Map的一个子区域求平均值,然后滑动。
(2)Global显然就是对整个Feature Map求均值了(kernel的大小设置成和Feature Map的相同)。所以,有多少个Feature Map就可以输出多少个节点。一般可将输出的结果直接喂给softmax层。
举例:
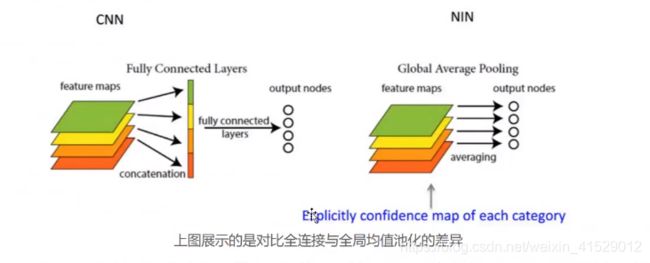
Global Average Pooling:是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量,在softmax中进行计算。
例:假如,最后一层的数据是10个6*6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,这样10个特征图就会输出10个数据点,将这些数据点组成一个1*10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了。
5.卷积的选取:
(1)卷积核尺寸方面:
①大卷积核用多个小卷积核代替;
②单一尺寸卷积核用多尺寸卷积核代替;
③固定形状卷积核趋于使用可变形卷积核;
④使用1x1卷积核(瓶颈结构)
(2)卷积层连接方面:
①使用跳跃连接,让模型更深;
②密集连接都是不错的优化方法;
③使每一层都融合上其它层的特征输出(例如:DenseNet)
6.遇到模型过拟合问题怎么解决?
举个例子:
在上学的时候,有人采取题海战术,把每个题目都背下来。但是题目稍微一变,他就不会做了。因为他非常复杂的记住了每道题的做法,而没有抽象出通用的规则。
所以过拟合有两种原因:
(1)训练集和测试集特征分布不一致;
(2)或者模型太过复杂(记住了每一道题)而样本不足;
欠拟合:欠拟合是由于学习不足;解决办法:可以考虑添加特征,从数据中挖掘出更多的特征,有时候还需要对特征进行变换,使用组合特征和高次特征。
两种解决过拟合的方法:
(1)L0、L1、L2:在向前传播、反向传播后面加个小尾巴;
(2)DropOut:训练时随机“删除”一部分神经元;
介绍的优化方法叫mini-batch,它主要解决的问题是:实际应用时的训练数据往往都太大了,一次加载到电脑里可能内存不够,其次运行速度也很慢。那自然就想到说,不如把训练数据分割成好几份,一次学习一份不就行了吗?前辈们试了试发现不仅解决了内存不足的问题,而且网络“收敛”的速度更快了。由于mini-batch这么棒,自然是神经网络中非常重要的一个技术,但是实际实现时你会发现“真的太简单了”。
mini-batch的操作:
洗牌:是mini-batch的一个操作,因为我们是将训练数据分割成若干份的,分割前将图片的顺序打乱就是所谓的“洗牌”了,这样每一次mini-batch学习的图片都不一样为网络中增加了一些随机的因素。优化了网络。
另外注意:
batch size太小会使训练速度很慢;
太大会加快训练速度,但同时会导致内存占用过高,并有可能降低准确率。
所以32至256是不错的初始值选择,尤其是64和128
问题,为什么选择2的指数倍?
因为计算机内存一般为2的指数倍,采用2进制编码。