window性能提升100倍!怎么做到的?
1. 背景
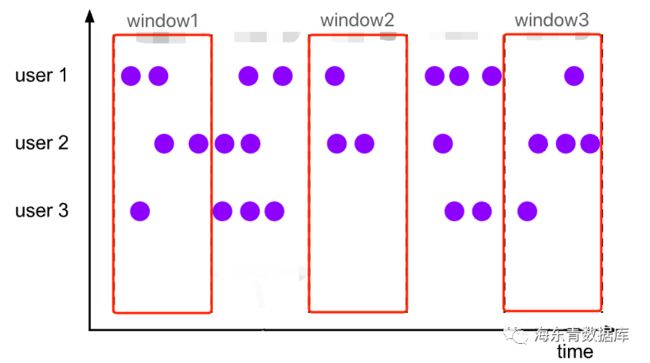
在时序数据库的业务使用场景中,经常有统计每天的平均值、最大值等需求,我们参照Flink设计在FalconTSDB里引入了Window概念来满足业务需求。Window可以将数据流按照规定的时间段来进行分组,例如上述需求中按天进行分组,然后可以分别对每个分组内的数据进行聚合计算。
但在线上业务使用FalconTSDB2.1过程中,小伙伴经常反馈含有Window的SQL执行速度慢, 因此我们在FalconTSDB2.2版本中对此进行了优化,本文就是分享我们是如何优化的。
若读者了解Window基础知识,可以跳过章节2基础知识,直接进入章节3来了解Window性能是怎样优化的。
(如果您还不了解海东青,可以阅读:关于FalconTSDB海东青时序数据库
)
2. 基础知识
本节介绍窗口函数基础知识
group by window(slide[, size[, offset]])在FalconTSDB中,Window定放置在Group BY从句中,当然Window还可以和其他GroupItem混用,但每个Group BY从句中至多只有一个Window的定义。Window中三个参数含义如下:
-
slide:窗口起点步长
-
size:窗口的大小,默认值为slide值
-
offset:窗口起点的偏移,默认值为0
Window中根据slide和size参数不同,可以形成三种窗口
-
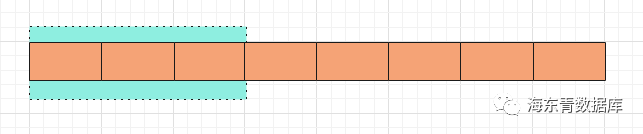
滚动窗口
滚动窗口表现如下图所示:

因此滚动窗口其定义为:slide=size,进一步可以简写为window(slide)。
-
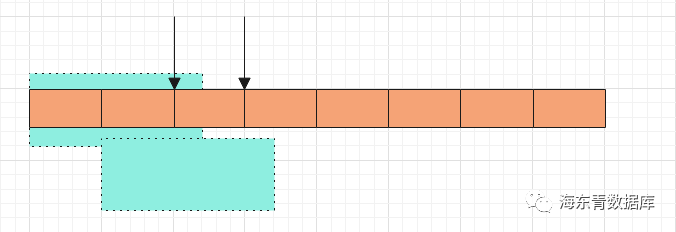
滑动窗口
滑动窗口表现如下图所示:

因此滑动窗口其定义为:slide 跳跃窗口 跳跃窗口表现如下图所示: 因此跳跃窗口其定义为:slide>size。 在FalconTSDB2.1中,存储层是根据Series(Series概念可以查看FalconTSDB手册)来读取数据,可以保证每个Series读取出的数据是有序的(按照time来排序)。 在FalconTSDB2.1中,针对含有Window算子的计划,此计划输入数据需要按照time排序,并且在存储层读取数据根据Series串行读取完所有原始数据。我们根据下面数据为例来说明FalconTSDB2.1中执行流程: (写入的数据格式可以查看FalconTSDB手册) 上述数据中存在两个Series,分别是car,brand=benchi和car,brand=bmw。在存储层存在TimeSort迭代器,此迭代器主要目的是驱动两个Series读取一次数据,然后开始按照time列使用多路归并排序来合并Series迭代器读取的数据。在合并过程中,某个Series迭代器读取的数据消费完时则驱动此迭代器进行进行下次读取数据,读取完毕后重复合并过程,直到读完满足条件的所有数据为止。这样从而保证了含有Window算子计划的输入数据是依据time有序的。 在FalconTSDB2.1使用过程中,业务经常反馈含有Window的SQL查询效率过慢。因此FalconTSDB2.2优化了Window执行流程。我们分析Window算子特点以及FalconTSDB2.1中Window执行流程,总结出三点: Window算子对输入数据有约束:Window算子只需要输入数据对Window之间数据需要按照time排序。而在FalconTSDB2.1中TimeSort是专门针对全局排序并有着其适应场景。 充分利用多核来提升性能。由于FalconTSDB存储层是根据Series来读取数据,因此我们可以依据Series来并发读取数据。 考虑能使用存储层提供的预聚算。由于FalconTSDB2.1中Window实现需要数据按照time全局排序,从而读取了所有原始数据。因此FalconTSDB2.1中Window执行流程不能利用存储层提供的预聚算。新的Window优化的设计中可以考虑能使用存储层提供的预聚算(关于预聚算的实现,我们会在后续文章中分享它)。 基于上述三点,我们为Window场景专门设计一个特殊的迭代器WindowItr。WindowItr考虑FalconTSDB2.1中的存储特性(即根据Series来读取数据,可以保证根据Series读取出的数据是按照time有序的)、Series的并发特性等,来保证WindowItr输出数据满足Window之间按照time有序的要求。 针对WindowItr输出数据有序要求,我们需要对Series生成的Chunk(表示读取的数据,理解为Chunk是由多行多列数据构成,它是执行过程中数据传递的基本单元)有要求,即存储层生成的每个Chunk要么属于某个Window,要么不属于所有Window,即不存在Chunk中的部分数据属于某个Window(为了保证存储层预聚算特性)。 为了生成上述要求中的Chunk,因此需要关注Chunk中的数据的两个问题: Chunk中的数据对应Window起点是什么 Chunk中的数据时间范围是多少 只要这两点定义好,则也就达到了存储层生成的每个Chunk要么属于某个Window要么不属于所有Window的要求。 针对Chunk中的数据对应Window起点这个问题,在存储层中很容易做到这点。根据Window的定义,存储层读取的任何一条数据都可以计算出它对应的Window起点。因此每个Chunk对应的Window起点就是由Chunk中第一条数据来确定,我们记作Window起点为window_start。 现在来看Chunk数据对应时间范围问题,在前面中我们对Chunk中的数据有着约束:Chunk要么属于某个Window,要么不属于所有Window(不存在Chunk中部分数据属于某个Window)。下面我们将仔细分析Window的定义来解决Chunk数据对应的时间范围问题。分析结果如下三幅图,在图中橙色表示Window的slide,而淡蓝色表示Window的size。 上图Window定义表示size<=slide,在此情况里表示所属其中一个Window的数据必然不属于另外一个WIndow, 因此Chunk的数据范围可以是[window_start,window_start+size)。 下面两幅图对应了所属其中一个Window的数据能属于另外一个WIndow的情形。 上图Window定义表示slide 上图Window定义表示slide 综上我们可以定义Chunk的范围为Interval。我们对Interval的定义如下: 设Chunk中第一条记录时间为x,则对应的Window起点为window_start,Interval其值为 因此在每个Chunk中需要标记出对应的Interval起始值,即Interval_Start。 上面解决了存储层生成的每个Chunk要么属于某个Window要么不属于所有Window要求,下面来看WindowItr的具体流程。 当只涉及时间分组时,例如如下SQL 其Window优化整体流程图(WindowItr的流程)如下: 如上图所示,在FalconTSDB2.2中WindowItr取代了FalconTSDB2.1中的TimeSort迭代器。其中所属WindowItr的SeriesItr可以并发读取数据。 在FalconTSDB2.2中实现中,当上层迭代器驱动WindowItr迭代器(见上图绿色部分)时,若第一次驱动WindowItr迭代器,则会启动多个协程(见上图粉红色部分),这些协程目的是根据SeriesItr并发读取数据。WindowItr迭代器会等待所属的所有SeriesItr都有Chunk(数据)。当读取数据的协程在读取完毕会判断是否所有SeriesItr都读取完数据,若读取完毕,则该协程会唤醒处理WindowItr迭代器所在的协程或生成数据读取完毕标记。WindowItr开始收集对应最小Interval_Start的所有SeriesItr的Chunk,并把这些SeriesItr和这些SeriesItr所属Chunk缓冲起来。当WindowItr收集完毕后,唤醒读取数据的协程处理缓冲区中的SeriesItr读取数据的任务。然后缓冲区的中Chunk逐次返回给上层迭代器。当缓冲区中没有Chunk时,重复到WindowItr迭代器会等待所属的所有SeriesItr都有Chunk过程处理,直到所有数据读取完毕。 正是由于为每个Chunk标记了Interval_Start,WindowItr每次返回给上层迭代器是Interval_Start最小的Chunk。从而保证了WindowItr返回给上层迭代器的Chunk是局部有序的(即每个Window间是有序,每个Window内不保证有序)。 同理当涉及分组下的Window时,例如SQL为 也有上述类似的逻辑,其工作图如下: 数据集为 此例子中group by brand通过流式方式来生成audi和bmw两个分组(上图中标记的group)。而每个分组就是WindowItr来输出数据为Window算子使用。 在FalconTSDB2.2中,我们充分利用FalconTSDB存储特性,避免了数据关于time全局排序,以及充分利用多核并行、存储层提供的预聚算,来优化了Window算子。与FalconTSDB2.1相比,性能得到巨大提升,尽情等待FalconTSDB2.2版本的发布。 本期 FalconTSDB实现解析到这就结束了,好学的你肯定学会了一些新东西,又产生了一些新困惑,以及朋友们若对本文中相关技术和问题处理方式有好的想法和建议,还请评论区留言探讨,也可以直接进群一起探讨交流,谢谢大家。 关注海东青数据库公众号: 添加海东青客服微信加群:
3. 执行流程
3.1 FalconTSDB2.1 Window的实现
insert car,brand=benchi value1=10 1
insert car,brand=benchi value1=12 2
insert car,brand=benchi value1=12 3
insert car,brand=benchi value1=12 4
insert car,brand=bmw value1=10 1
insert car,brand=bmw value1=12 2
insert car,brand=bmw value1=12 3
insert car,brand=bmw value1=12 43.2 FalconTSDB2.2 Window的实现

slide>=size, Interval=[window_start,window_start+slide)
slide3.2.1 只涉及时间分组情形
select max(value1) from car group by window(2ns)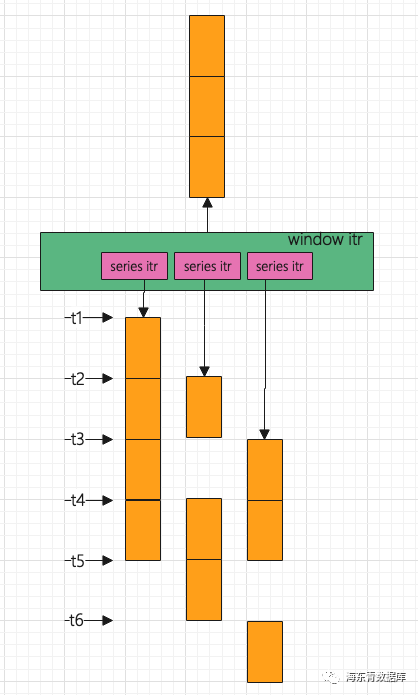
3.2.2 包含Window多个分组情形
select max(speed) from car group by brand, window(1h)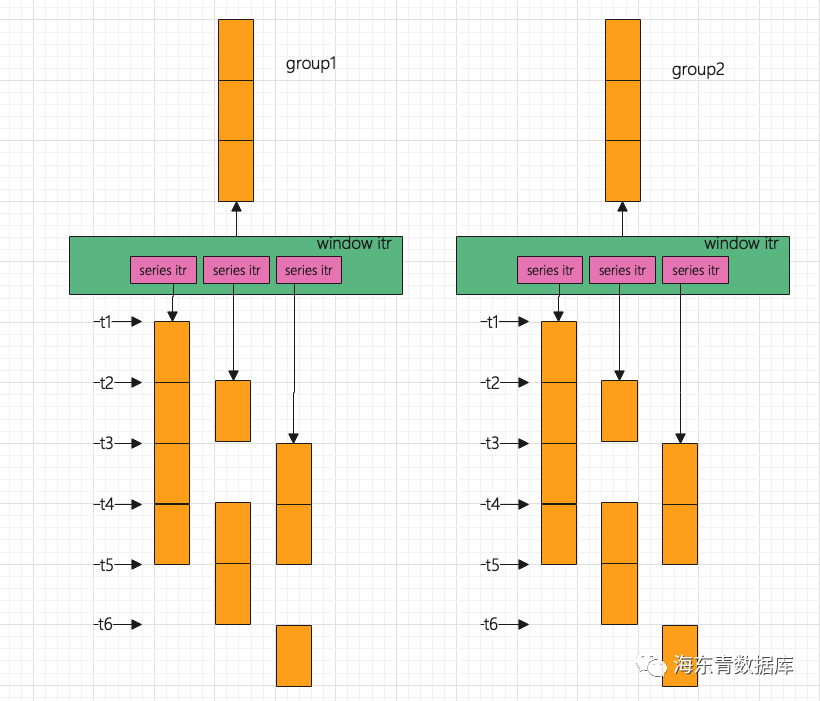
insert car,brand=audi,type=q3 value1=10 1
insert car,brand=audi,type=q5 value1=12 2
insert car,brand=audi,type=q3 value1=12 3
insert car,brand=audi,type=q5 value1=12 4
insert car,brand=bmw,type=x3 value1=10 1
insert car,brand=bmw,type=x5 value1=12 2
insert car,brand=bmw,type=x3 value1=12 3
insert car,brand=bmw,type=x5 value1=12 44. 总结

