AI 引擎系列 6 - 在 Vitis 分析器中分析 AI 引擎编译结果(2022.1 更新)
AI 引擎系列 6 - 在 Vitis 分析器中分析 AI 引擎编译结果(2022.1 更新)
简介
在上一篇 AI 引擎系列博文(此处)中,我们运行了 AI 引擎编译器,将计算图 (graph) 与内核代码编译到目标 AI 引擎模型中。
在本文中,我们将在 Vitis™ 分析器中详解编译汇总文件,其中提供了有关编译的大量实用信息。
要求
下文要求您通读前几篇 AI 引擎系列博文。
AI 引擎系列 1 - 从 AI 引擎工具开始(2022.1 更新)
AI 引擎系列 2 - AI 引擎 graph 简介 (2022.1 更新)
AI 引擎系列 3 - AI 引擎内核简介
AI 引擎系列 4 - 首次运行 AI 引擎编译器和 x86simulator(2022.1 更新)
AI 引擎系列 5 - 以 AI 引擎模型为目标运行 AI 引擎编译器(2022.1 更新)
在 Vitis 分析器中查看 AI 引擎编译结果
首先打开前几篇博文中创建的工程。
在工程资源管理器窗口中,双击 Vitis 分析器汇总文件,此文件名为 project.aiecompile_summary,位于 AI 引擎仿真编译结果 (Emulation-AIE/Work) 下。
由此即可在 Vitis 分析器工具中打开此文件。

Vitis 分析器工具会打开新窗口。在其左侧面板中有多个部分,每个部分都提供了有关编译结果的一部分详细信息。
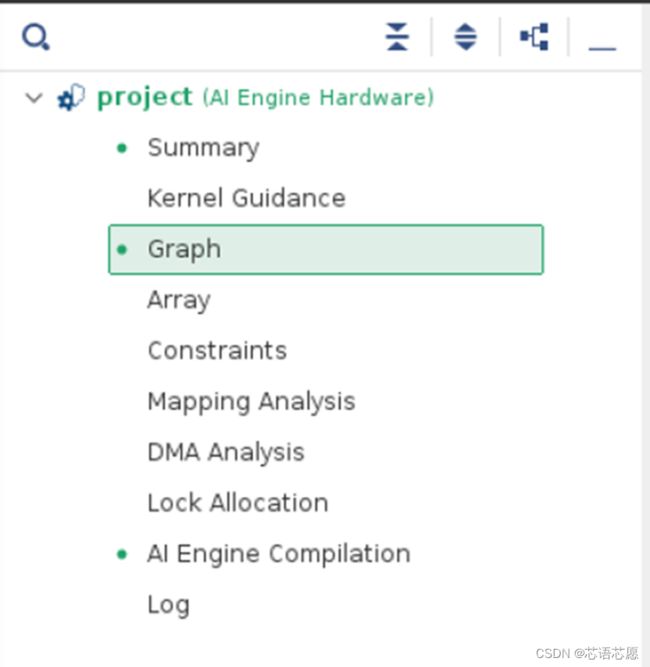
- Summary(汇总):提供有关编译的高层次信息,例如,编译时间或者所执行的命令
- Kernel Guidance(内核准则):此页面提供了有关如何对计算图与内核进行最优化的一些建议
- Graph(计算图):此页面提供了有关计算图与内核的详细信息。其中包含计算图的可视化呈现以及多个表格,这些表格可提供计算图中不同元素的信息
- Array(阵列):显示 AI 引擎阵列中计算图的实际布局
- Constraints(约束):将应用于计算图或内核(如有)的不同约束加以汇总
- Mapping Analysis(映射分析):提供计算图所使用的不同核、存储器和端口的详细映射报告
- DMA Analysis(DMA 分析):显示映射中例化的所有 DMA、关联的端口实例以及 DMA 所访问的存储器组。
- Lock Allocation(锁定分配):显示用于 DMA 的不同锁定
- AI Engine Compilation(AI 引擎编译):显示每个 AI 引擎核的编译操作的详细 log 日志。
- Log(log 日志):包含完整的编译日志,可按下列消息来筛选:“Error”(错误)、“Warning”(警告)、“Info”(参考)和“Status”(状态)
开始使用 AI 引擎后,您就会发现计算图视图和阵列视图最有趣,所以让我们来详细了解下这两个视图。
计算图可视化
打开“Graph”页面。
计算图视图
在计算图页面顶部可以看到 AI 引擎计算图的图形表示法,其中将各种不同元素组合在一起(您可以在后续博文中了解如何更改这些分组)。
在以下截屏中,各元素按拼块分组。
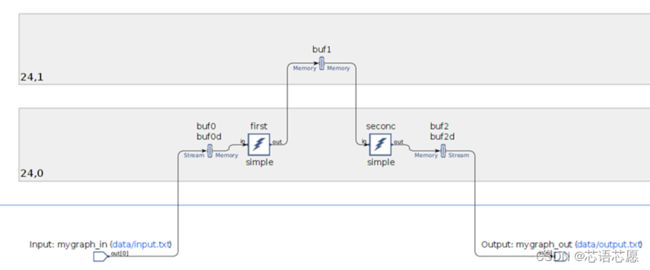
可以看到其中使用了 2 个拼块:
- tile [24,0](位于第 1 行第 25 列上的拼块)
- tile [24,1](位于第 2 行第 25 列上的拼块)
第一和第二个内核位于相同拼块 (tile [24,0]) 上,这意味着这 2 个内核将在相同核上按顺序运行,并共享该核的处理时间。第一个内核读取存储器缓冲器,第二个内核则写入存储器缓冲器,这些内核与其读写的存储器缓冲器都位于相同拼块上。
用于在 2 个内核之间进行通信的缓冲器位于相邻的 tile [24,1] 拼块上,因此这些内核可以直接访问该缓冲器,而无需任何 DMA,也没有额外时延(相比于读取位于相同拼块上的存储器)。
我曾在 Versal 自适应 SoC AI 引擎入门一文中提到过有关存储器访问相邻拼块的信息。
位于计算图与第一个内核的输入端口之间的存储器缓冲器以及位于第二个内核与计算图的输出端口之间的存储器缓冲器均为双缓冲器,每个此类存储器都有 2 个名称(例如,buf0 和 buf0d),这是此类缓冲器的识别依据。这样即可支持内核在其中一个缓冲器上工作,而另一个缓冲器则供 DMA 填充(或清空)。
第一个内核与第二个内核之间的存储器缓冲器是单缓冲器存储器 (buf1)。由于这两个内核按顺序运行,不会同时访问存储器,因此无需双缓冲器。
您可单击顶部设置来更改元素的分组方式。例如,您可按子计算图来进行分组:
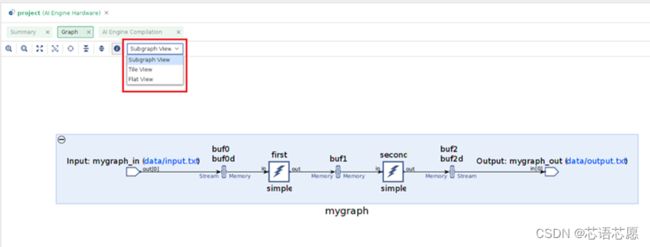
更改视图对于充分了解应用相关信息及其映射到 AI 引擎阵列的方式很有帮助。
详情表
页面底部有 2 张表,其中显示了计算图中不同元素的详细信息(内核、PL、缓冲器、端口、信号线和拼块)
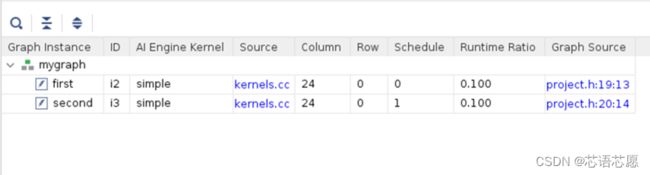
请留意表格与计算图视图的链接方式,这很有用。选择表格中的任一元素即可在计算图视图中将其高亮显示。
阵列视图
打开“Array”(阵列)页面。
在该页面顶部可以看到器件的完整阵列视图(针对 VCK190 上的器件有 400 个 AI 引擎拼块),其中布局有不同的计算图元素。
在该页面底部有与计算图页面上相同的表格,并且这些表格也链接到阵列视图。

该页面对于了解内核或存储器的不同位置导致的时延很有用。
下一步
在下一篇博文中,我们将讲解如何在仿真期间生成追踪来分析 AI 引擎的状态。