机器学习基础之《回归与聚类算法(7)—无监督学习K-means算法》
一、什么是无监督学习
1、没有目标值—无监督学习
一家广告平台需要根据相似的人口学特征和购买习惯将美国人口分成不同的小组,以便不同的用户采取不同的营销策略。
Airbnb需要将自己的房屋清单分组成不同的社区,以便用户能更轻松地查阅这些清单(对房屋进行分类)。
一个数据科学团队需要降低一个大型数据集的维度的数量,以便简化建模和降低文件大小(比如PCA降维)。
二、无监督学习包含算法
1、聚类
K-means(K均值聚类)
2、降维
PCA
三、K-means原理
1、K-means的聚类效果图
一开始拿到的数据是这样的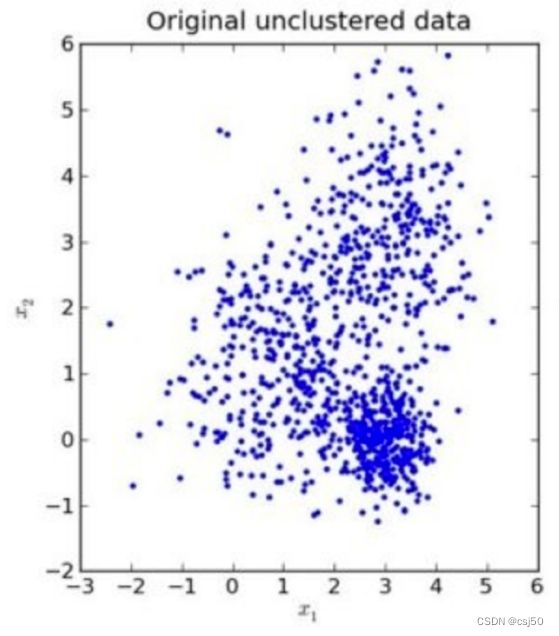
要把它分成三个堆:
2、K-means聚类步骤
(1)随机设置K个特征空间内的点作为初始的聚类中心
K值:超参数
K值如何确定?
1)根据需求,比如公司要求把客户分成三个类别,那么K值就取3
2)如果没有需求,可以做网格搜索,调节超参数,选择最合适的K值
PS:超参数是指在训练模型之前需要手动设置的参数。用户可以自己设定的参数,就叫超参数。
第一步就是随机找到3个点作为初始聚类中心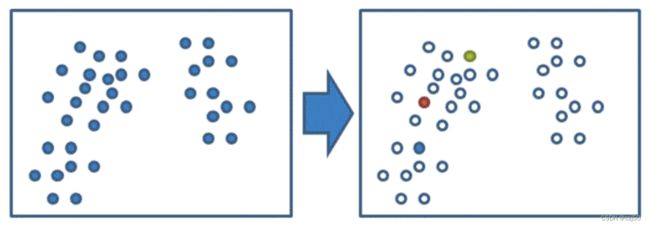
(2)对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
计算每个点到聚类中心的距离,取距离最近的那个把它颜色标记成一样的颜色
(3)接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
对每个堆重新求一个中心点,得到新的3个聚类中心
(4)如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
定标准的时候如果只是相近,没有完全重合,我们也可以终止聚类
3、KNN和K-means的区别
一个是预测的样本计算和每个样本的距离,然后根据每个样本的分类选择合适的K,来预测要预测的样本的类别。
这个是选择合适的K个样本。然后计算n-K的样本到这个K个样本的距离,近的就归哪个。
虽然都是物以群分。但是,一个是有目标值,一个没有。
4、3个堆的中心点怎么求
A(a1, b1, c1)
B(a2, b2, c2)
...
Z(a26, b26, c26)
比如有A到Z个样本,分别有a、b、c特征值
中心点的坐标,中心点(a平均, b平均, c平均)
四、K-means API
1、sklearn.cluster.KMeans(n_clusters=8, init='k-means++')
k-means聚类
n_clusters:开始的聚类中心数量(K值有几个)
init:初始化方法,默认为'k-means++'(对k-means的优化方法)
labels_:默认标记的类型,可以和真实值比较(不是值比较)。用完之后用点属性查看
五、案例:k-means对Instacart Market用户聚类
1、背景
Instacart公司想要了解他们注册用户对物品的偏好
2、流程分析
假设K=3
(1)降维之后的数据
(2)预估器流程
(3)看结果
(4)模型评估
3、修改day01_instacart_pca
# 1、获取数据
# 2、合并表
# 3、找到user_id和aisles之间的关系
# 4、PCA降维
import pandas as pd
# 1、获取数据
order_products = pd.read_csv("./order_products__prior.csv")
products = pd.read_csv("./products.csv")
orders = pd.read_csv("./orders.csv")
aisles = pd.read_csv("./aisles.csv")
# 2、合并表
# 合并aisles.csv和products.csv表
tab1 = pd.merge(aisles, products, on=["aisle_id", "aisle_id"])
tab2 = pd.merge(tab1, order_products, on=["product_id", "product_id"])
tab3 = pd.merge(tab2, orders, on=["order_id", "order_id"])
#head()是获取dataframe的前5行数据
tab3.head()
# 3、找到user_id和aisles之间的关系
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
table.head()
# 4、PCA降维
from sklearn.decomposition import PCA
# 1)实例化一个转换器类
transfer = PCA(n_components=0.95)
# 2)调用fit_transform
table_new = transfer.fit_transform(table)
table_new.shape
# 降维留下了44个特征,同时保留了95%的信息
table_new
# 预估器流程
from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=3)
# 训练,传入特征值,本来就没有目标值所以不传目标值
estimator.fit(table_new)
# 查看用户被分到了哪一组
y_predict = estimator.predict(table_new)
# 查看前300个
y_predict[:300]
新增代码的运行结果: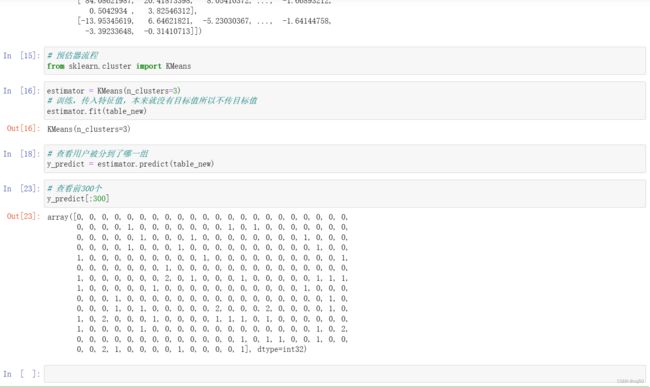
estimator.labels_[:300]就等于y_predict[:300]
六、K-means性能评估指标
1、轮廓系数
注:对于每个点i为已聚类数据中的样本,b_i 为i到其它族群的所有样本的距离最小值,a_i 为i到本身簇的距离平均值。最终计算出所有的样本点的轮廓系数平均值。
2、轮廓系数值分析
聚类效果好:高内聚,低耦合
3、说明
b_i是某一个样本到其他族群所有样本的距离的最小值
a_i是某一个样本到它本族群中所有距离的,求一个平均
b_i是外部距离,a_i是内部距离
4、如何根据轮廓系数去判断聚类的好坏呢
从极端的角度去思考:
(1)当b_i >> a_i
外部距离很大,内部距离很小
SC ≈ b_i / b_i = 1
(2)当b_i << a_i
外部距离很小,内部距离很大
SC ≈ -a_i / a_i = -1
(3)轮廓系数的取值范围[-1, 1]
(4)如果b_i>>a_i:趋近于1效果越好,b_i< 5、轮廓系数API 6、修改day01_instacart_pca 新增代码的运行结果: 20万数据从 14:34 跑到 14:45,才出来。。。 七、K-means总结 1、特点分析:采用迭代式算法,直观易懂并且非常实用 2、缺点:容易收敛到局部最优解 3、K-means的应用场景
sklearn.metrics.silhouette_score(X, labels)
计算所有样本的平均轮廓系数
X:特征值
labels:被聚类标记的目标值# 1、获取数据
# 2、合并表
# 3、找到user_id和aisles之间的关系
# 4、PCA降维
import pandas as pd
# 1、获取数据
order_products = pd.read_csv("./order_products__prior.csv")
products = pd.read_csv("./products.csv")
orders = pd.read_csv("./orders.csv")
aisles = pd.read_csv("./aisles.csv")
# 2、合并表
# 合并aisles.csv和products.csv表
tab1 = pd.merge(aisles, products, on=["aisle_id", "aisle_id"])
tab2 = pd.merge(tab1, order_products, on=["product_id", "product_id"])
tab3 = pd.merge(tab2, orders, on=["order_id", "order_id"])
#head()是获取dataframe的前5行数据
tab3.head()
# 3、找到user_id和aisles之间的关系
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
table.head()
# 4、PCA降维
from sklearn.decomposition import PCA
# 1)实例化一个转换器类
transfer = PCA(n_components=0.95)
# 2)调用fit_transform
table_new = transfer.fit_transform(table)
table_new.shape
# 降维留下了44个特征,同时保留了95%的信息
table_new
# 预估器流程
from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=3)
# 训练,传入特征值,本来就没有目标值所以不传目标值
estimator.fit(table_new)
# 查看用户被分到了哪一组
y_predict = estimator.predict(table_new)
# 查看前300个
y_predict[:300]
estimator.labels_[:300]
# 模型评估—轮廓系数
from sklearn.metrics import silhouette_score
silhouette_score(table_new, y_predict)

初始随机的时候,3个点挤在一起了,导致结果陷入到局部最优
可以用(多次聚类)来解决
没有目标值的情况,第一次做聚类
有新的用户数据了,根据之前聚好的类,进行分类了
聚类一般做在分类之前