大数据四大阵营之OLTP阵营(上)

**
一 | 大数据的四大阵营是什么?
**

· OLTP(在线事务、交易处理):RDBMS、NoSQL、NewSQL
· OLAP(在线分析处理):MapReduce、Hadoop、Spark等
·MPP(大规模并行处理):Greenplum、Teradata Aster等
· 流数据管理:CEP/Esper、Storm、Spark、Stream、Flume等
二 | OLTP阵营
OLTP阵营可以分为:
·传统的关系型数据库
·NoSQL
·NewSQL
三类不同的解决方案。
在本篇文章中,我们主要针对NoSQL与NewSQL进行讨论。
(一)NoSQL数据库
NoSQL类系统普遍存在下面一些共同特征:
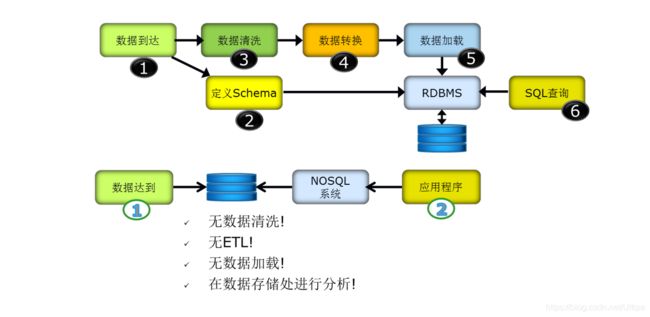
· 不需要预定义数据模式(No-Upfront-Schema)或表结构:数据中的每条记录都可能有不同的属性和格式。当插入数据时,并不需要预先定义它们的模式。NoSQL区别于传统的关系型数据库,如下图所示。
· 无共享(Shared Nothing)架构:NoSQL通常把数据划分后存储在各个本地服务器上。因为从本地磁盘读取数据的性能往往好于通过网络传输(如NAS/SAN)来读取数据的性能,从而提高了系统的性能,当然,代价是多份数据拷贝及数据一致性保证。
注:这里面有个潜在的认知误区,现代的网络速率已经达到100Gbps,很多大企业的骨干网已经是25Gbps的量级,这种传输速率理论上已经超越了普通机械硬盘的吞吐率。但是,我们需要注意一点的是,这是在数据连续传输时的理论速率上限。如果是频繁的小数据的传输,则会像汽车不断的低速启动、急刹一样,即便你有300KPH的最高时速,你的真正的平均时速连30也很难达到。同样的,很多场景下,在分布式系统中小数据的频繁传输,导致集群内的多节点的通信,并没有我们想象中高效!特别是数据库类型的应用。这就是为什么很多网络硬件厂家会推出RDMA zero-copy等技术,以及基于(本地化)硬盘的存储架构依然可能会大幅秒杀那些鼓吹存算分离的云架构。任何一种架构,都要看它是否是为了某种场景而优化形成的,具体情况,具体分析。
· 分区:NoSQL需要对数据集进行分区,将记录分散在多个节点上面。并在分区的同时进行复制。这样既提高了并行性能,又能保证没有单点失效的问题。
· 弹性可扩展:可以在系统运行的时候,动态添加或者删除节点。不需要停机维护,数据可以自动迁移。
· 异步复制:和RAID存储系统不同的是,NoSQL中的复制,往往是基于日志的异步复制。这样,数据就可以尽快地写入一个节点,而不会被网络传输引起迟延。缺点是并不总是能保证一致性,这样的方式在出现故障的时候,可能会丢失少量的数据。
· 符合BASE模型:BASE提供的是最终一致性和软事务(相对于事务严格的ACID模型,下文中的NewSQL在NoSQL基础上实现了对ACID模型的支持)。
以下再对颇具代表性的MongoDB(文档型)、Cassandra(宽表型)、Redis(键值型)和Ultipa Graph(图数据库)解决方案进行介绍。
(1)文档型NoSQL—MongoDB
作为文档型NoSQL数据库的代表,MongoDB采用了一种与RDBMS反其道而行之的设计理念,不需要预先定义数据结构,使用了与JSON(JavaScript Object Notation)兼容的BSON(Binary JSON)的轻量级数据传输与存储结构(相对于笨重、复杂的XML而言,XML一直以其解析复杂而被广大Web开发人员所诟病),也不需要对存储的数据结构像关系型数据库一样进行正则化(Normalization,目的是减少重复数据)。例如构建一个数字图书馆,如果用传统的RDBMS则至少需要对书名、作者等相关信息使用多个正则化的表结构来存储,在进行数据检索与分析的时候则需要频繁的(且昂贵的)表JOIN操作,而MongoDB中则只需要通过对JSON(在MongoDB中称作BSON,Binary JSON)描述的简单文档型数据结构进行一次读操作即可完成。对于提高性能以及在商用硬件上扩展而言MongoDB的优势不言而喻,同时MongoDB也兼顾关系型数据库操作习惯,例如它保留了left-outer JOIN操作……
在体系架构设计上MongoDB支持四种数据存储引擎(见下图),WiredTiger(默认引擎)、MMAP(内存-硬盘映射引擎)、In-Memory(内存引擎)以及Encrypted(加密存储引擎),并在其上提供了基于BSON的文档型数据结构模型及检索模型。

图:MongoDB架构示意图
笔者还记得在Ultipa的最初阶段,我们曾经尝试用MongoDB作为持久化层与Ultipa的实时、高并发计算引擎对接,但是发现,MongoDB大约数以百倍到千倍的慢于计算引擎的数据吞吐能力,也会拖累整个系统的性能,因此才会有我们坚持自研高性能存储引擎的动因。这个经验告诉我们,任何高性能系统,都是相对的,找到自己合适的就是对的。
(2)宽表型NoSQL—Cassandra
Cassandra是目前最流行的宽表数据库(Wide Column),最早由Facebook开发并开源。相信Facebook是受到了谷歌的高性能存储系统BigTable(基于GFS等技术,服务于MapReduce等任务)的启发而来的。它的最大特点是:
①无特殊节点(如主、备服务器),因此无单点故障;
②服务器集群可跨多个物理数据中心,无需主服务器的异步同步功能支持(见下图)。
Cassandra系统中有几个关键概念:
· 数据分区(Data Partitioning)与一致性哈希(Consistent Hashing):鉴于Cassandra的核心设计理念是一个逻辑数据库中的数据由所有集群中的节点分散保存,也就是所谓分区。数据的分布式会带来两个潜在的问题:
①如何判断指定的数据存储在哪个节点之上?
②在增加或删除节点时如何尽量减少数据的跨节点移动?解决方案就是通过持续的一致性哈希运算(即实现对Cassandra分区索引)。
· 数据复制(Data Replication):所有无共享(Shared-Nothing)架构避免单点故障都是通过对数据进行多份复制(类似于拷贝)来实现的。
·一致性级别(Consistency Level):在Cassandra系统中可以定制一致性级别,也就是说需要多少节点返回读写操作的确认,见下图。如果一致性级别为3,需要节点1-3全部回复确认后,协调节点4才会回复给客户端。
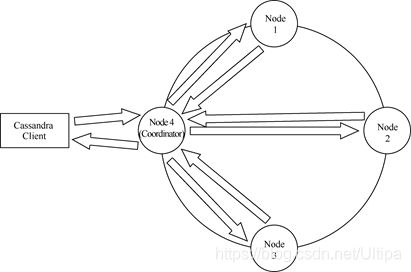 图:Cassandra集群读写同步示意图
图:Cassandra集群读写同步示意图
业界对于Cassandra的使用相当广泛,大部分用它来做数据分析服务,甚至是实时数据分析及流数据处理,还有些公司试图用Cassandra全面取代MySQL。例如Twitter,不过貌似这一尝试并未获得成功,而始作俑者Facebook本来最早用Cassandra来做邮箱搜索(Inbox Search),后来因为最终一致性的问题而换成了HBase,不过这丝毫不影响业界对它趋之若鹜。Cassandra一直宣称是NoSQL数据库中线性可扩展(Linear Scalability)做得最好的,目前已知全球最大的商用Cassandra部署恐怕是苹果公司,有超过十万个节点和数以十PB计的数据对其地图、iTunes、iCloud及iAd服务进行管理与分析。
(3)键值型NoSQL—Redis
Redis是由早期的键值(Key-Value Pair)数据库发展而来的,因此,即便今天它已经支持了更为丰富的数据结构类型(如列表、集合、哈希、比特数组、字符串、HyperLogLogs等),它依然被大家看作一款基于内存(高速)的键值(Key-Value)型NoSQL数据库。Redis区别于RDBMS的关键在于不需要数据库索引(Indexing),而通过主键检索(Key)来实现数据结构与算法,而且主键可以是任何binary-safe(二进制安全)数据类型(如子串、数字、图片、音乐甚至一段视频),因此Redis适用于快速查询、检索类操作(特别是以读操作为主的应用)。和所有NoSQL数据库一样,Redis也具有高度水平可扩展性(Scale-Out)。下图展示的是在2个数据中心中构建一个Redis集群,每个数据中心可以就近满足客户应用(App Server)的SLA访问时间需求(如相应时间≤200ms),这样的设计对于以读操作为主的应用类型特别适合。

图: Redis跨数据中心架构示意图
以车票与机票查询为例,通过地点、时间这些键值可以快速查询到车次、航班以及每趟车或航班的剩余座位,键值数据库可以实现比RDBMS高出数倍甚至上千倍的检索效率。以12306为例,它们采用了一款叫作Gemfire XD的商用键值型NoSQL取代了之前的IBM DB2 关系型数据库,在PC服务器集群上实现了比小型机上查询效率高出数以百倍的提升。

Redis的主要应用场景有三类:
·缓存(Caching):由于Redis支持过期数据(可以让过期数据被新数据替换掉,对于不需要永久在内存保存的数据,这样可以节省大量内存空间),且性能好,可以和Memcached结合用作缓存。
· 简单消息队列(Simple MessageQueue):Redis支持简单的Pub/Sub模型,以及基于列表的队列模型,所以可以用作构建轻量级的消息队列。
·高性能数据访问:通常一个Redis实体(Instance)可以满足每秒50万次的访问,由于Redis是单线程实现,在一台主机上可以启动多个Redis实体以增加高性能并发访问的服务能力。
·文/ 老孙(孙宇熙:云计算、大数据、高性能存储与计算系统架构专家 )
·未完待续·