Seata分布式事务AT、TCC、SAGA、XA模式
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata将为用户提供了AT、TCC、SAGA和XA事务模式,为用户打造一站式的分布式解决方案。
AT模式
实现原理
阿里SEATA独有模式,通过生成反向SQL实现数据回滚,需要在数据库额外附加UNDO_LOG表,UNDO_LOG表中保存的是自动生成的回滚SQL。
举个
insert into 订单 values(1001,...)
update 仓储 set num = 300 where gid =100;
自动生成UNDO_LOG回滚日志
DELETE FROM 订单 where id =1001
update 仓储 set num=210 where gid = 100
特点
性能:高
模式:AP,存在数据不一致的中间状态
难易程度:简单,靠SEATA自己解析反向SQL并闻滚
使用要求:
所有服务与数据库必须要自己拥有管理权,因为要创建UNDO LOG表
最好都是MySQL,听说也支持PSQL,不过没试验过
应用场景:
高并发互联网应用,允许数据出现短时不一致,可通过对账程序或补录来保证最终一致性。
TCC模式
实现原理
TCC是Try-尝试、Confirm-确认、Cancel-取消Try尝试阶段,对资源进行锁定。
Confirm确认阶段,对资源进行确认,完成操作Cancel取消阶段,对资源进行还原,取消操作。
在代码与数据表中扩展字段,实现对特定数据资源的锁定。
Try阶段:预留所需的资源,预增金额,冻结库存
Confirm确认阶段:把预留的资源放入真实资源字段,清空预留资源
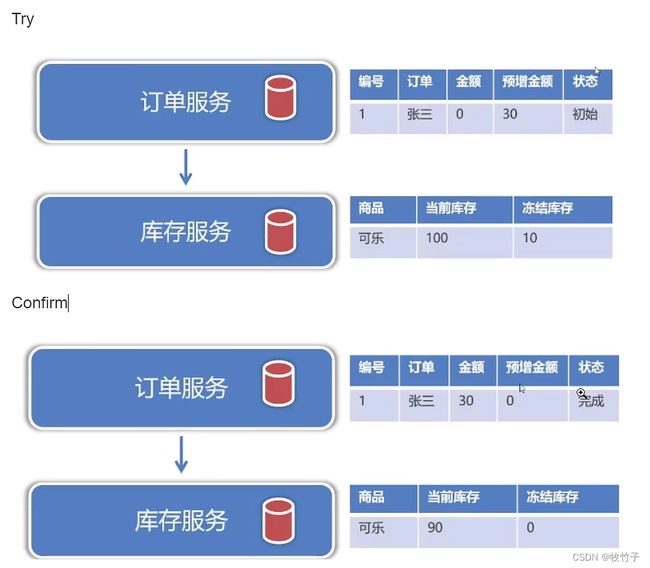
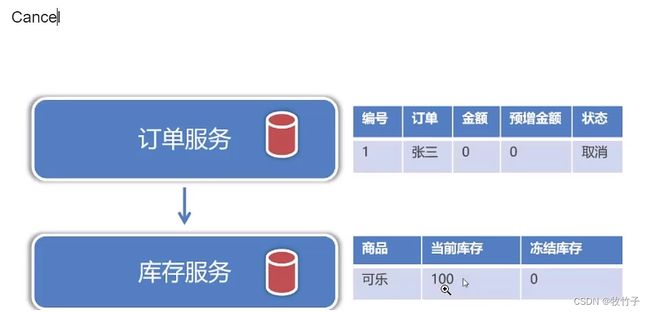
cancel阶段:对锁定的资源释放
特点
性能:好
模式:AP,存在数据不一致的中间状态
难易程度:复杂,SEATA TC只负责全局事务的提交与回滚指令,具体的回滚处理全靠程序员自己实现(每个业务流程车都需手动写代码TRY,COMMIT,CANCEL三个对应的方法)
使用要求:
所有服务与数据库必须要自己拥有管理权
支持异构数据库,可以使用不同选型实现
应用场景:
高并发互联网应用,允许数据出现短时不一致,可通过对账程序或补录来保证最终一致性。
SAGA模式
实现原理
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务具体实现者开发实现。
Saga相关概念
1987年普林斯顿大学的Hector Garcia-Molina和Kenneth Salem发表了一篇Paper Sagas,讲述的是如何处理long lived transaction(长活事务)。Saga是一个长活事务可被分解成可以交错运行的子事务集合。其中每个子事务都是一个保持数据库一致性的真实事务。 论文地址:sagas
Saga的组成
每个Saga由一系列sub-transaction Ti 组成
每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果
可以看到,和TCC相比,Saga没有“预留”动作,它的Ti就是直接提交到库。
Saga的执行顺序有两种:
T1, T2, T3, …, Tn
T1, T2, …, Tj, Cj,…, C2, C1,其中0 < j < n
Saga定义了两种恢复策略:
-
backward recovery,向后恢复,补偿所有已完成的事务,如果任一子事务失败。即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
-
forward recovery,向前恢复,重试失败的事务,假设每个子事务最终都会成功。适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, …, Tj(失败), Tj(重试),…, Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci。
显然,向前恢复没有必要提供补偿事务,如果你的业务中,子事务(最终)总会成功,或补偿事务难以定义或不可能,向前恢复更符合你的需求。
理论上补偿事务永不失败,然而,在分布式世界中,服务器可能会宕机,网络可能会失败,甚至数据中心也可能会停电。在这种情况下我们能做些什么? 最后的手段是提供回退措施,比如人工干预。
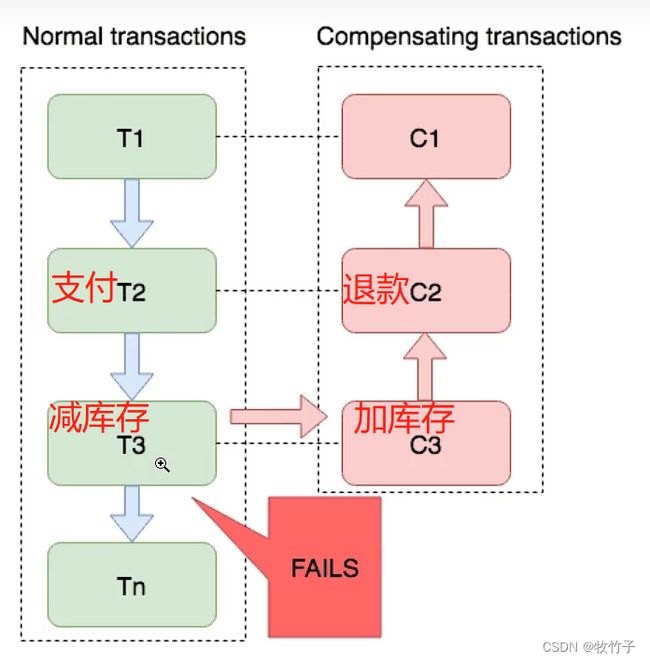
这里比如支付宝只提供了转账接口和退款接口,而你具体负责商城订单业务,正向流程下单-支付成功-扣减库存-订单状态变更为待发货。
如果扣减库存失败,比如库存为0扣减失败了,这时候你需要自行调用支付宝的退款接口,模拟事务回滚的业务流程,支付宝是不会帮你实现事务回滚的。
特点
性能:不一定,取决于三方服务,不推荐此种分布式事务
模式:AP,存在数据不一致的中间状态
难易程度:1.复杂,提交与回滚流程全靠程序员编排,代码逻辑难以理解,后期更是难以维护和升级。2.可能会出现循环依赖的死循环。3.两种恢复策略需要保证原子性
使用要求:
在当前架构引入状态机机制,类似于工作流
引入原子性,确保forward和backward时重复执行
无法保证隔离性
应用场景:
基本不推荐此种分布式事务。需要与第三方交互时才会考虑,例如:调用支付宝支付接口->出库失败->调用支付宝退款接口
和TCC对比
Saga相比TCC的缺点是缺少预留动作,导致补偿动作的实现比较麻烦:Ti就是commit,比如一个业务是发送邮件,在TCC模式下,先保存草稿(Try)再发送(Confirm),撤销的话直接删除草稿(Cancel)就行了。而Saga则就直接发送邮件了(Ti),如果要撤销则得再发送一份邮件说明撤销(Ci),实现起来有一些麻烦。
XA模式
实现原理
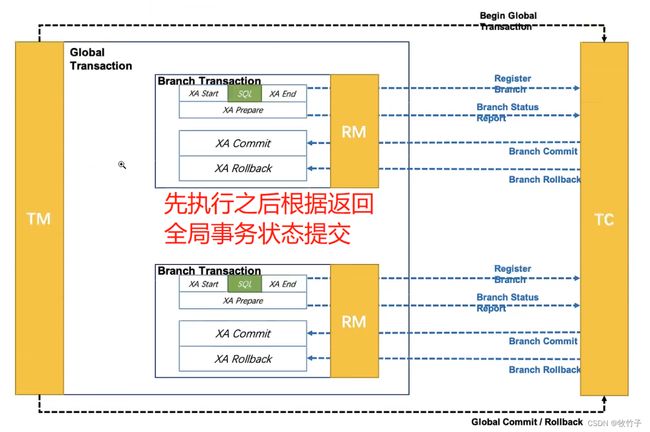
基于数据库的XA协议来实现2PC又称为XA方案,数据库必须实现并支持XA协议
特点
性能:低
模式:CP,强一致性
难易程度:简单,基于数据库自带特性实现,无需改表
使用要求:
使用支持XA方案的关系型数据库(主流都支持)
应用场景:
金融行业,并发量不大,但数据很重要的项目
总结:
可以看出,所有分布式方式都是两阶段模式,成功提交,失败回滚。而根据实现难度,TCC和SAGA都需要手动实现业务回滚代码,复杂度要高一些。其他都可以有数据库或者第三方事务管理器实现回滚业务流程,而你只需要专注业务流程本身。
AT模式需要所有参与方都有数据库权限,这点如果项目参与方都是一起的不涉及第三方或许可以实现。但如果你调用的是第三方服务,显然不可能支持,第三方更不可能给你提供数据库访问权限,比如支付服务,任何第三方支付都不可能提供数据库权限给你。
因此要综合考虑自己的使用情况,再决定使用哪种模式。
但是现实中,分布式事务还是要根据情况去使用,绝大多数项目能不是使用分布式事务就不会使用。只要确保最终事务一致性即可。