python实现AES-128#实现加密字符串和加密文件
文章目录
- 综述
-
- 算法描述
- 基本运算
- 加解密流程图
- 算法实现
-
- 字节代替
- 行移位
- 列混淆
-
- 描述
- 代码实现
-
- bit_split()
- _gmul(a,b)
- gmul()
- multi()
- mixcolumns()
- 密钥扩展
- 轮秘钥加
- 预处理
-
- 1 初始化
- 2 补位
- 3 输入数据
- 加密
- 解密
- 功能测试
-
- 使用方法
- 加解密字符串
- 加解密文件
- 算法评价
- 源代码
-
- AES.py文件
- boxdata.py
综述
这篇文章是对之前的一篇文章的重写和优化AES加密算法基于python实现
脚本语言:Python
已实现的功能
- 明文和密密钥可以是任意字符:中文,字符,数字或符号。
明文长度任意,密钥的字节数不能超过16字节。默认编码为utf-8所以,密钥最多支持5个中文字符
- 待加密的数据:可以是字符串,也可以对文本文件进行加密
实验参考:
- 应用密码学(第三版)P108-P228
算法描述
AES-128
- 密钥长度:4个字(即128bit,16字节)
- 分组大小:4个字
- 轮数:10轮
基本运算
- 字节代替SubBytes
- 行移位ShiftRows
- 列混淆Mixcolumns
- 轮密钥加AddRoundKey
加解密流程图
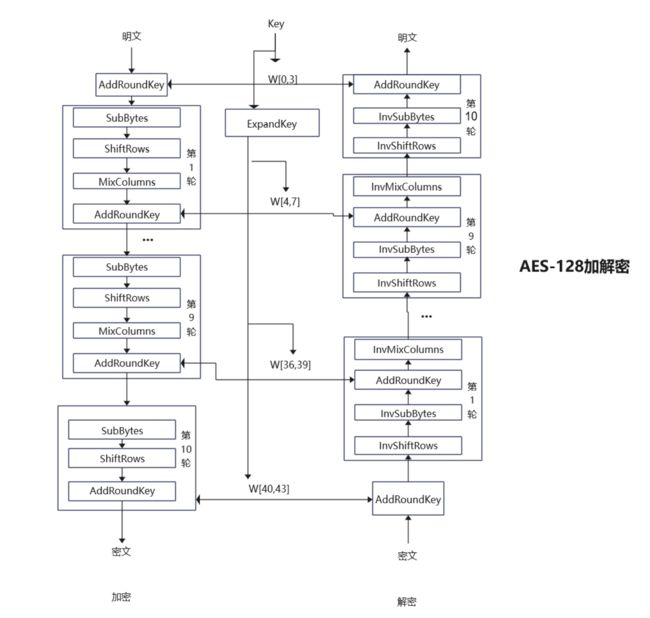
算法实现
用到了以下python库
import numpy as np
import argparse
import functools
import operator
主要从下面几个部分展开讲解:
- 字节代替SubBytes
- 行移位ShiftRows
- 列混淆Mixcolumns
- 轮密钥加AddRoundKey
- 输入预处理(这个也很重要)
字节代替
输入:是一个4x4的矩阵:在这是二维的ndarray数组
输出:输出二维数组
其中S盒是常量
代码
def subBytes(state):
state=state.reshape(16)
if FLAG:
box=S_BOX
else:
box=I_SBOX
for _ in range(16):
row=(state[_]>>4)&0b1111
col=state[_]&0b1111
state[_]=box[row][col]
return state.reshape(4,4)
代码解释
第2行:先将4x4的二维矩阵变成一维数组进行处理。
第3-6行:根据FLAG判断操作是加密还是解密,然后选取S盒
第7-10行:算法主体
第8行:取高四位作为行号(右移4位然后做逻辑运算)
第9行:取低四位作为列号
第10行:然后查S盒
行移位
移动规则:
对4x4矩阵做如下操作:
加密:
- 第一行不动
- 第二行循环左移1字节
- 第三行循环左移2字节
- 第四行循环左移3字节
解密
- 第一行不动
- 第二行循环右移1字节
- 第三行循环右移2字节
- 第四行循环右移3字节
代码:
def shiftrows(state):
'''-1 if FLAG else 1 如果加密就向左移位,如果解密就向右移位'''
return np.vstack(
(
state[0,:],#第一行不移动
np.roll(state[1,:],-1 if FLAG else 1),#第2行:循环向左(或向右)移动一个字节
np.roll(state[2,:],-2 if FLAG else 2),#第3行:循环向左(或向右)移动2个字节
np.roll(state[3,:],-3 if FLAG else 3),#第4行:循环向左(或向右)移动3个字节
)
)
解释:
np.roll(ag1,ag2)方法,ag1是待循环移动的对象,ag2是移动向量,负数向左移,正数向右移
np数组的操作:state[1,:]是取state的第一行
np.vstack():对数组进行竖直方向的拼接。
列混淆
描述
思路来源于书上
列混淆的难点在于G(2^8)域上的乘法运算
1 加法(异或运算):(01110011)+(10010101)=(01110011)⊕(10010101)=(11100110)
2 乘法:res=(x0000010)*(00000010)mod(100011011)(等价于将x0000010左移一位)
-
当x=1时:
res=(00000100)⊕(00011011)
-
当x=0时:
res=(00000100)
其中(100000000)mod(100011011)=(00011011)
(100011011)为G(2^8)上不可约多项式
思路
所以我们可以将其中一个数拆成2^n次方型相加
例如:(00001110)=(00000010)+(00000100)+(00001000)
这样相乘时就是不断将被乘数左移,根据被乘数的最高位的值运用上面的规则得到相应的值。
0e*47=(00001110)*(01000111)
=[(00000010)⊕(00000100)⊕(00001000)]*(01000111)
=(00000010)*(01000111)⊕(00000100)*(01000111)⊕(00001000)*(01000111)
=(10001110)⊕[(00011100)*(00011011)]⊕(00001000)*(01000111)
=(10001110)⊕(00000111)⊕(00001110)
=(10000111)
代码实现
这部分涉及到了下面五个函数
'''列混淆处理
1、bit_split(): 将十进制数分解成二进制形式表示,如7=(1+10+100)二进制,被gmul调用
2、_gmul(a,b): 特殊的G(2^8)上的乘法运算:第一个参数的值是2的n次方,被gmul调用
3、gmul(): 完整的G(2^8)上的乘法运算: 如0e*47=87
4、multi: 列混淆常数矩阵的一行*状态矩阵,返回一维矩阵,被mixcolumns调用
5、mixcolumns():列混淆常数矩阵*状态矩阵
'''
bit_split()
这个函数的主要作用就是将十进制数拆成因数为2的多项式,在做乘法前将乘数进行预处理。返回的是一个多项式的列表
例如:
21=20+22+24
=(00000001)+(000000100)+(00010000)
代码
def bit_split(num):
'''将num分成形如(0b1+0b10+0b100+...),返回一个列表,被gmul调用'''
li=[]
arg=[int(i) for i in format(num,'b')][::-1]
if arg[0]:
li.append(1)
base=1
for offset in arg[1:]:
base=base<<1
if offset:
li.append(base)
return li
代码解读:
第4行代码:将十进制数num先用format()函数格式化为二进制字符串,然后将每一个bit取出来int()处理,为一个列表。最后将列表反转。(方便后面移位运算判断)
其中x=2
可以看成多项式num=a7x7+a6x6+a5x5+a45x4+a3x3+a2x2+a1x1+a0x0
例如:
19=(10011)2
=>[1,0,0,1,1]=>反转=>[1,1,0,0,1]然后进行下一步处理
第5-6行:判断20的系数,为1:列表中要加上(00000001)2。
第7-11行:就是拆分过程,这就解释了为啥需要将列表反转了。
arg[1]为1:base=2,将base加入li中
arg[1]为0:base=2,进行下一次循环。
_gmul(a,b)
这个函数是一个特殊的域上乘法运算:参数a是2的n次方数(形如20,23,25,…)
代码
def _gmul(a,b):
'''被gmul调用(a为2的n次方)'''
while a>>1:
a=a>>1
x=(b&0b1111111)<<1
y=(b>>7)*0b11011
b=x^y
return b
a每次右移一位,当b的第八位是1时,b左移一位后需要异或(0b11011)。当b第八位为0,b只需左移一位。当a=1时,乘法结束,返回运算后的结果。
gmul()
gmul函数是真正实现G(28)域上乘法。它调用bit_split()和_gmul()函数。
代码
def gmul(a,b):
'''在G(2^8)上的乘法a*b'''
a_li=bit_split(a)
func=functools.partial(_gmul,b=b)
return functools.reduce(operator.xor,list(map(func,a_li)))
分析
第三行:调用bit_split函数将a拆成2n的多项式。
第四行:将_gmul设置成偏函数,b参数固定。
第五行:涉及两个操作。
- 先将拆分后的多项式的每一项与b进行特殊的乘法运算。
- 然后将所有的结果进行异或运算,最后返回异或后的结果。
multi()
这个函数是cons乘以4x4的state的每一列
代码
def multi(cons,state):
'''const每一行 * state 返回一行数据'''
li=[]
for _ in range(4):
li.append(functools.reduce(operator.xor,list(map(gmul,cons,state[:,_]))))
return li
mixcolumns()
这是最上层的函数,操作对象是常数矩阵和状态矩阵。都是4x4的。
代码
def mixcolumns(state):
li=[]
const_M=MIX_C if FLAG else I_MIXC #常数矩阵的选择
const_M=np.array(const_M) #转化为np数组
for _ in range(4):
li.append(multi(const_M[_,:],state))
return np.array(li)
根据加密解密操作,选择正确的常数矩阵。
然后常数矩阵的每一行乘以状态矩阵。返回每一行运算后的结果。
最后返回一个4x4的矩阵结果。
密钥扩展
初始密钥是一个4个字(16字节的序列,128比特)。输入密钥直接被复制到扩展密钥的前四个字中,得到w[1],w[2],w[3],w[4];然后每次用4个字填充扩展余下的部分,AES128总共需要44个字。在扩展密钥数组中,w[i]的值依赖于w[i-1]和w[i-4](i>=4)。
对w数组中下标不为4的倍数的元素,只是简单地异或,其逻辑关系为:
w[i]=w[i-1] ⊕ w[i-4] (i不为4的倍数)
对w数组下标为4的倍数的元素,采用如下计算方法:
(1)RotWord(),将输入的4个字节循环左移一个字节。expandkey()函数的第12行实现
(2)subword(),基于S盒对输入字中的每个字节进行S代替,subword()函数实现。
(3)将步骤2的结果再和轮常量Rcon[i//4]相异或。
(4)将步骤3的结果与w[i-4]异或。
密钥扩展这块当时搞错了,排查了很久
temp=w[i-1][:]#深拷贝
我一开始写成了temp=w[i-1],这样导致我后面修改temp的值的时候,实际是修改的w里面的数据
算法实现
我分成了两个函数进行实现
subword()
expandkey()
subword就是一个字节替换函数和加密操作的字节替代的操作一样
代码
def subword(temp: list):
li=[]
for i in temp:
col=i&0b1111
row=i>>4
li.append(S_BOX[row][col])
return li
expandkey
代码
def expandkey(key: bytes):
'''密钥扩展:初始密钥为16字节'''
key=[i for i in key]#把字节读成列表
w=[]
i=0
while i<4:
w.append([key[4*i],key[4*i+1],key[4*i+2],key[4*i+3]])
i+=1
while i<44:
temp=w[i-1][:]#深拷贝
if i%4==0:
temp.append(temp.pop(0))#循环左移一个字节
temp=subword(temp)#字节替换
temp=list(map(operator.xor,temp,RCon[i//4 -1]))#与轮常量异或
w.append(list(map(operator.xor,w[i-4],temp)))#与w[i-1]异或
i=i+1
return np.array(w).transpose()
expandkey函数最后得到的是一个4x44的矩阵。
轮秘钥加

代码
def addroundkey(state,key):
'''state和key都是4x4的np数组'''
li=[]
for _ in range(4):
li.append(list(map(operator.xor,state[:,_],key[:,_])))
return np.array(li).transpose() #需要进行转置
预处理
预处理这块针对的是明文和密钥
1 初始化
根据调用脚本,传入的参数进行加密或解密之前的初始化
位置参数:
- t:数据类型:string字符串,file文件
- message:待处理的数据
- key:密钥
可选参数
-
flag指定操作: True为加密,False为解密,默认加密。解密时,需要加上–flag参数
-
encoding:指定编码,默认为utf-8(主要是处理非ascii字符)
2 补位
明文长度不是16的倍数
需要算出明文长度,当最后一个分组缺少对少个字节就补上空白字符,且补的最后一个字节表示的是补的字节的个数
注意的是,当明文长度刚好是16的倍数时,依然要补位,补上16字节的数据。最后一个字节表示补数据的个数。
对于最后一个字节的处理:补充字节数+65=对应的ascii字符。最后解密的时候需要删掉补充的字符。
代码
def group_handle(b_m):
'''将原明文或密文进行分组,然后加解密'''
b_size=len(b_m)//16
li=[]
group=[]
for i in range(b_size):
li.append(b_m[i*16:i*16+16])
for i in li:
state=bytes2matri(i)
group.append(process(state,key))
return group
密钥长度小于16字节
密钥长度小于16字节时,补上空白字符,补充后,密钥长度为16字节
代码
def handlekey(key:str,encoding='utf-8')->bytes:
'''对key进行预处理,转化为bytes
key超过16字节,报错,不足16字节末尾补零
'''
size=len(key.encode(encoding))
if size>16:
print('密钥不符合要求,长度超过16字节')
exit()
key=key+' '*(16-size)
return key.encode(encoding)
3 输入数据
当输入的数据是字符串时
当输入的数据是字符串时,字符集默认是utf-8,如果不是,需要在运行脚本的时候加上–encoding参数指定编码
当输入的数据是文本文件时
为文本文件时,我们需要以指定字符集打开文件,读取到字符串,然后进行加密之前的预处理。分组补位。
加密后的数据保存在cipher.txt文件中。
解密的数据保存在plain.txt中
加密
加密解密一个分组的实现都写在了一个函数中
def process(state,key):
'''单个分组加解密处理'''
if FLAG:
state=addroundkey(state,key[:,0:4])
for i in range(1,10):#前9轮
state=subBytes(state)
state=shiftrows(state)
state=mixcolumns(state)
state=addroundkey(state,key[:,i*4:i*4+4])
#第10轮
state=subBytes(state)
state=shiftrows(state)
state=addroundkey(state,key[:,40:])
else:
state=addroundkey(state,key[:,40:])
for i in range(10,1,-1):
state=shiftrows(state)
state=subBytes(state)
state=addroundkey(state,key[:,4*i-4:4*i])
state=mixcolumns(state)
#第10轮
state=shiftrows(state)
state=subBytes(state)
state=addroundkey(state,key[:,0:4])
return matri2bytes(state).hex()
解密输入代码
def encrypt(message,encoding='utf-8'):
'''明文加密'''
size=len(message.encode(encoding))
rem=size%16
if rem==0:
message=message+' '*15+chr(65+16)
else:#chr(65+16-rem),将补充数表示为ascii字符,占一个字节
message=message+' '*(16-1-rem)+chr(65+16-rem)
#现在的message字节数为16的整数倍
b_m=message.encode(encoding)
cipher=group_handle(b_m)
return functools.reduce(operator.add,cipher)
解密
解密输入数据代码
def decrypt(message,encoding='utf-8'):
'''密文解密'''
b_m=bytes.fromhex(message)
m=group_handle(b_m)
m=bytes.fromhex(functools.reduce(operator.add,m))
num=m[-1]-65 #之前加上了65,现在减掉65后得到补充的0的个数
return m[:len(m)-num].decode(encoding)
功能测试
使用方法
AES> python AES.py -h
usage: AES [-h] [--flag] [--encoding ENCODING] {string,file} message key
positional arguments:
{string,file} 输入数据的类型:文件或字符串}
message 待加密或解密的字符串或文件
key 密钥:length<=16 bytes
optional arguments:
-h, --help show this help message and exit
--flag 要进行的操作: 默认加密,带上--flag为解密
--encoding ENCODING 文本字符集指定,默认UTF-8
加解密字符串
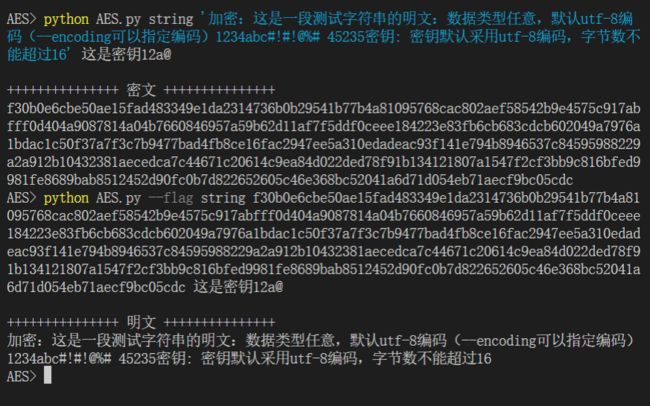
加解密文件

算法评价
对于AES-128算法,当攻击者获得一轮密钥是,如果想猜测下一轮密钥是,不仅需要获得本轮密钥,还需要假定前一轮的四个轮密钥字,每个轮密钥字都是32位,这样便需要2128次猜测,其时间复杂度已经与穷尽密钥强力攻击相当。同样的道理,如果想通过一轮获得密钥向前推算,也需要对后一轮密钥的猜测,其时间复杂度是2128。所以一轮密钥的获取对于破解出初始密钥没有任何帮助,其破解强度一样等同于穷举密钥强力攻击。以此,Square攻击,能量攻击方法对AES算法的威胁,产生了有效的消减作用,使其不能通过对一轮子密钥的猜测成功二顺利推测出前后轮密钥,甚至是初始密钥。
AES算法优点:
- 运算速度快。
- 对内存的需求非常低,适合于受限环境。
- 分组长度和密钥长度设计灵活。
- AES标准支持可变分组长度,分组长度可设定为32比特的任意倍数,最小值为128比特,最大值为256比特。
- AES的密钥长度比DES大,它也可设定为32比特的任意倍数,最小值为128比特,最大值为256比特,所以用穷举法是不可能破解的。
- 很好的抵抗差分密码分析及线性密码分析的能力。
AES算法缺点:
目前尚未存在对AES 算法完整版的成功攻击,但已经提出对其简化算法的攻击。
源代码
两个文件
静态数据boxdata.py在AES.py中导入
脚本文件AES.py
AES.py文件
from boxdata import * #s盒等数据
import numpy as np #方便操作字节数组
import argparse
import functools
import operator
#功能函数
def subBytes(state):
'''
字节替换函数,参数是np数组
根据FLAG字段决定是加密还是解密
'''
state=state.reshape(16)
if FLAG:
box=S_BOX
else:
box=I_SBOX
for _ in range(16):
row=(state[_]>>4)&0b1111
col=state[_]&0b1111
state[_]=box[row][col]
return state.reshape(4,4)
def shiftrows(state):
'''-1 if FLAG else 1 如果加密就向左移位,如果解密就向右移位'''
return np.vstack(
(
state[0,:],#第一行不移动
np.roll(state[1,:],-1 if FLAG else 1),#第2行:循环向左(或向右)移动一个字节
np.roll(state[2,:],-2 if FLAG else 2),#第3行:循环向左(或向右)移动2个字节
np.roll(state[3,:],-3 if FLAG else 3),#第4行:循环向左(或向右)移动3个字节
)
)
'''列混淆处理
1、bit_split(): 将十进制数分解成二进制形式表示,如7=(1+10+100)二进制,被gmul调用
2、_gmul(a,b): 特殊的G(2^8)上的乘法运算:第一个参数的值是2的n次方,被gmul调用
3、gmul(): 完整的G(2^8)上的乘法运算: 如0e*47=87
4、multi: 列混淆常数矩阵的一行*状态矩阵,返回一维矩阵,被mixcolumns调用
5、mixcolumns():列混淆常数矩阵*状态矩阵
'''
def bit_split(num):
'''将num分成形如(0b1+0b10+0b100+...),返回一个列表,被gmul调用'''
li=[]
arg=[int(i) for i in format(num,'b')][::-1]
if arg[0]:
li.append(1)
base=1
for offset in arg[1:]:
base=base<<1
if offset:
li.append(base)
return li
def _gmul(a,b):
'''被gmul调用(a为2的n次方)'''
while a>>1:
a=a>>1
x=(b&0b1111111)<<1
y=(b>>7)*0b11011
b=x^y
return b
def gmul(a,b):
'''在G(2^8)上的乘法a*b'''
a_li=bit_split(a)
func=functools.partial(_gmul,b=b)
return functools.reduce(operator.xor,list(map(func,a_li)))
def multi(cons,state):
'''const每一行 * state 返回一行数据'''
li=[]
for _ in range(4):
li.append(functools.reduce(operator.xor,list(map(gmul,cons,state[:,_]))))
return li
def mixcolumns(state):
'''
域上乘法,调用gmul()
'''
li=[]
const_M=MIX_C if FLAG else I_MIXC #常数矩阵的选择
const_M=np.array(const_M) #转化为np数组
for _ in range(4):
li.append(multi(const_M[_,:],state))
return np.array(li)
def addroundkey(state,key):
'''state和key都是4x4的np数组'''
li=[]
for _ in range(4):
li.append(list(map(operator.xor,state[:,_],key[:,_])))
return np.array(li).transpose() #需要进行转置
#输入处理以及密钥扩展
def subword(temp: list):
li=[]
for i in temp:
col=i&0b1111
row=i>>4
li.append(S_BOX[row][col])
return li
def expandkey(key: bytes):
'''密钥扩展:初始密钥为16字节'''
key=[i for i in key]#把字节读成列表
w=[]
i=0
while i<4:
w.append([key[4*i],key[4*i+1],key[4*i+2],key[4*i+3]])
i+=1
while i<44:
temp=w[i-1][:]#深拷贝
if i%4==0:
temp.append(temp.pop(0))#循环左移一个字节
temp=subword(temp)#字节替换
temp=list(map(operator.xor,temp,RCon[i//4 -1]))#与轮常量异或
w.append(list(map(operator.xor,w[i-4],temp)))#与w[i-1]异或
i=i+1
return np.array(w).transpose()
#--------------------------------------------------------------
def matri2bytes(matrix)->bytes:
'''将4x4状态矩阵转换为字节序列'''
li=list(matrix.transpose().reshape(16))
li=list(map(lambda x: format(x,'02x'),li))
li=''.join(li)
return bytes.fromhex(li)
def process(state,key):
'''单个分组加解密处理'''
if FLAG:
state=addroundkey(state,key[:,0:4])
for i in range(1,10):#前9轮
state=subBytes(state)
state=shiftrows(state)
state=mixcolumns(state)
state=addroundkey(state,key[:,i*4:i*4+4])
#第10轮
state=subBytes(state)
state=shiftrows(state)
state=addroundkey(state,key[:,40:])
else:
state=addroundkey(state,key[:,40:])
for i in range(10,1,-1):
state=shiftrows(state)
state=subBytes(state)
state=addroundkey(state,key[:,4*i-4:4*i])
state=mixcolumns(state)
#第10轮
state=shiftrows(state)
state=subBytes(state)
state=addroundkey(state,key[:,0:4])
return matri2bytes(state).hex()
def handlekey(key:str,encoding='utf-8')->bytes:
'''对key进行预处理,转化为bytes
key超过16字节,报错,不足16字节末尾补零
'''
size=len(key.encode(encoding))
if size>16:
print('密钥不符合要求,长度超过16字节')
exit()
key=key+' '*(16-size)
return key.encode(encoding)
def setargs():
parser=argparse.ArgumentParser(prog='AES',prefix_chars='-',epilog=None,add_help=True)
parser.add_argument('Type',type=str,choices=['string','file'],help='输入数据的类型:文件或字符串}')
parser.add_argument('message',type=str,help="待加密或解密的字符串或文件")
parser.add_argument('key',type=str,help='密钥:length<=16 bytes')
parser.add_argument('--flag',action='store_false',help="要进行的操作: 默认加密,带上--flag为解密")
parser.add_argument('--encoding',type=str,default='utf-8',help='文本字符集指定,默认gbk')
return parser.parse_args()
def bytes2matri(by):
'''将字节序列转化为4x4矩阵'''
t=[x for x in by]
return np.array(t).reshape(4,4).transpose()
def group_handle(b_m):
'''将原明文或密文进行分组,然后加解密'''
b_size=len(b_m)//16
li=[]
group=[]
for i in range(b_size):
li.append(b_m[i*16:i*16+16])
for i in li:
state=bytes2matri(i)
group.append(process(state,key))
return group
def encrypt(message,key,encoding='utf-8'):
'''明文加密'''
size=len(message.encode(encoding))
rem=size%16
if rem==0:
message=message+' '*15+chr(65+16)
else:#chr(65+16-rem),将补充数表示为ascii字符,占一个字节
message=message+' '*(16-1-rem)+chr(65+16-rem)
#现在的message字节数为16的整数倍
b_m=message.encode(encoding)
cipher=group_handle(b_m)
return functools.reduce(operator.add,cipher)
def decrypt(message,key,encoding='utf-8'):
'''密文解密'''
b_m=bytes.fromhex(message)
m=group_handle(b_m)
m=bytes.fromhex(functools.reduce(operator.add,m))
num=m[-1]-65 #之前加上了65,现在减掉65后得到补充的0的个数
return m[:len(m)-num].decode(encoding)
if __name__=='__main__':
args=setargs()
FLAG=args.flag
encode=args.encoding
key=expandkey(handlekey(args.key,encode))
#判断加解密:
if FLAG:
if args.Type=='file':
with open(args.message,'r',encoding=encode) as f:
message=f.read()
cipher=encrypt(message,key,encode)
with open('cipher.txt','w',encoding=encode) as fi:
fi.write(cipher)
print('生成密文文件,cipher.txt')
else:
message=args.message
cipher=encrypt(message,key,encode)
print()
print("+"*15,'密文',"+"*15)
print(cipher)
else:
if args.Type=='file':
with open(args.message,'r',encoding=encode) as f:
message=f.read()
plain=decrypt(message,key,encode)
with open('plain.txt','w',encoding=encode) as fi:
fi.write(plain)
print('生成明文文件,plain.txt')
else:
message=args.message
plain=decrypt(message,key,encode)
print()
print("+"*15,'明文',"+"*15)
print(plain)
boxdata.py
#列混淆常数矩阵
MIX_C = [[0x2, 0x3, 0x1, 0x1], [0x1, 0x2, 0x3, 0x1], [0x1, 0x1, 0x2, 0x3], [0x3, 0x1, 0x1, 0x2]]
#逆列混淆矩阵
I_MIXC = [[0xe, 0xb, 0xd, 0x9], [0x9, 0xe, 0xb, 0xd], [0xd, 0x9, 0xe, 0xb], [0xb, 0xd, 0x9, 0xe]]
RCon = [[0x01,0x00,0x00,0x00],
[0x02,0x00,0x00,0x00],
[0x04,0x00,0x00,0x00],
[0x08,0x00,0x00,0x00],
[0x10,0x00,0x00,0x00],
[0x20,0x00,0x00,0x00],
[0x40,0x00,0x00,0x00],
[0x80,0x00,0x00,0x00],
[0x1B,0x00,0x00,0x00],
[0x36,0x00,0x00,0x00]
]
#S盒子
S_BOX = [[0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5, 0x30, 0x01, 0x67, 0x2B, 0xFE, 0xD7, 0xAB, 0x76],
[0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0, 0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0xA4, 0x72, 0xC0],
[0xB7, 0xFD, 0x93, 0x26, 0x36, 0x3F, 0xF7, 0xCC, 0x34, 0xA5, 0xE5, 0xF1, 0x71, 0xD8, 0x31, 0x15],
[0x04, 0xC7, 0x23, 0xC3, 0x18, 0x96, 0x05, 0x9A, 0x07, 0x12, 0x80, 0xE2, 0xEB, 0x27, 0xB2, 0x75],
[0x09, 0x83, 0x2C, 0x1A, 0x1B, 0x6E, 0x5A, 0xA0, 0x52, 0x3B, 0xD6, 0xB3, 0x29, 0xE3, 0x2F, 0x84],
[0x53, 0xD1, 0x00, 0xED, 0x20, 0xFC, 0xB1, 0x5B, 0x6A, 0xCB, 0xBE, 0x39, 0x4A, 0x4C, 0x58, 0xCF],
[0xD0, 0xEF, 0xAA, 0xFB, 0x43, 0x4D, 0x33, 0x85, 0x45, 0xF9, 0x02, 0x7F, 0x50, 0x3C, 0x9F, 0xA8],
[0x51, 0xA3, 0x40, 0x8F, 0x92, 0x9D, 0x38, 0xF5, 0xBC, 0xB6, 0xDA, 0x21, 0x10, 0xFF, 0xF3, 0xD2],
[0xCD, 0x0C, 0x13, 0xEC, 0x5F, 0x97, 0x44, 0x17, 0xC4, 0xA7, 0x7E, 0x3D, 0x64, 0x5D, 0x19, 0x73],
[0x60, 0x81, 0x4F, 0xDC, 0x22, 0x2A, 0x90, 0x88, 0x46, 0xEE, 0xB8, 0x14, 0xDE, 0x5E, 0x0B, 0xDB],
[0xE0, 0x32, 0x3A, 0x0A, 0x49, 0x06, 0x24, 0x5C, 0xC2, 0xD3, 0xAC, 0x62, 0x91, 0x95, 0xE4, 0x79],
[0xE7, 0xC8, 0x37, 0x6D, 0x8D, 0xD5, 0x4E, 0xA9, 0x6C, 0x56, 0xF4, 0xEA, 0x65, 0x7A, 0xAE, 0x08],
[0xBA, 0x78, 0x25, 0x2E, 0x1C, 0xA6, 0xB4, 0xC6, 0xE8, 0xDD, 0x74, 0x1F, 0x4B, 0xBD, 0x8B, 0x8A],
[0x70, 0x3E, 0xB5, 0x66, 0x48, 0x03, 0xF6, 0x0E, 0x61, 0x35, 0x57, 0xB9, 0x86, 0xC1, 0x1D, 0x9E],
[0xE1, 0xF8, 0x98, 0x11, 0x69, 0xD9, 0x8E, 0x94, 0x9B, 0x1E, 0x87, 0xE9, 0xCE, 0x55, 0x28, 0xDF],
[0x8C, 0xA1, 0x89, 0x0D, 0xBF, 0xE6, 0x42, 0x68, 0x41, 0x99, 0x2D, 0x0F, 0xB0, 0x54, 0xBB, 0x16]]
#逆S盒
I_SBOX = [[0x52, 0x09, 0x6A, 0xD5, 0x30, 0x36, 0xA5, 0x38, 0xBF, 0x40, 0xA3, 0x9E, 0x81, 0xF3, 0xD7, 0xFB],
[0x7C, 0xE3, 0x39, 0x82, 0x9B, 0x2F, 0xFF, 0x87, 0x34, 0x8E, 0x43, 0x44, 0xC4, 0xDE, 0xE9, 0xCB],
[0x54, 0x7B, 0x94, 0x32, 0xA6, 0xC2, 0x23, 0x3D, 0xEE, 0x4C, 0x95, 0x0B, 0x42, 0xFA, 0xC3, 0x4E],
[0x08, 0x2E, 0xA1, 0x66, 0x28, 0xD9, 0x24, 0xB2, 0x76, 0x5B, 0xA2, 0x49, 0x6D, 0x8B, 0xD1, 0x25],
[0x72, 0xF8, 0xF6, 0x64, 0x86, 0x68, 0x98, 0x16, 0xD4, 0xA4, 0x5C, 0xCC, 0x5D, 0x65, 0xB6, 0x92],
[0x6C, 0x70, 0x48, 0x50, 0xFD, 0xED, 0xB9, 0xDA, 0x5E, 0x15, 0x46, 0x57, 0xA7, 0x8D, 0x9D, 0x84],
[0x90, 0xD8, 0xAB, 0x00, 0x8C, 0xBC, 0xD3, 0x0A, 0xF7, 0xE4, 0x58, 0x05, 0xB8, 0xB3, 0x45, 0x06],
[0xD0, 0x2C, 0x1E, 0x8F, 0xCA, 0x3F, 0x0F, 0x02, 0xC1, 0xAF, 0xBD, 0x03, 0x01, 0x13, 0x8A, 0x6B],
[0x3A, 0x91, 0x11, 0x41, 0x4F, 0x67, 0xDC, 0xEA, 0x97, 0xF2, 0xCF, 0xCE, 0xF0, 0xB4, 0xE6, 0x73],
[0x96, 0xAC, 0x74, 0x22, 0xE7, 0xAD, 0x35, 0x85, 0xE2, 0xF9, 0x37, 0xE8, 0x1C, 0x75, 0xDF, 0x6E],
[0x47, 0xF1, 0x1A, 0x71, 0x1D, 0x29, 0xC5, 0x89, 0x6F, 0xB7, 0x62, 0x0E, 0xAA, 0x18, 0xBE, 0x1B],
[0xFC, 0x56, 0x3E, 0x4B, 0xC6, 0xD2, 0x79, 0x20, 0x9A, 0xDB, 0xC0, 0xFE, 0x78, 0xCD, 0x5A, 0xF4],
[0x1F, 0xDD, 0xA8, 0x33, 0x88, 0x07, 0xC7, 0x31, 0xB1, 0x12, 0x10, 0x59, 0x27, 0x80, 0xEC, 0x5F],
[0x60, 0x51, 0x7F, 0xA9, 0x19, 0xB5, 0x4A, 0x0D, 0x2D, 0xE5, 0x7A, 0x9F, 0x93, 0xC9, 0x9C, 0xEF],
[0xA0, 0xE0, 0x3B, 0x4D, 0xAE, 0x2A, 0xF5, 0xB0, 0xC8, 0xEB, 0xBB, 0x3C, 0x83, 0x53, 0x99, 0x61],
[0x17, 0x2B, 0x04, 0x7E, 0xBA, 0x77, 0xD6, 0x26, 0xE1, 0x69, 0x14, 0x63, 0x55, 0x21, 0x0C, 0x7D]]