sklearn机器学习:特征选择-Lasso
Lasso的核心作用:特征选择
Lasso类的格式
sklearn.linear_model.Lasso (alpha=1.0, fit_intercept=True, normalize=False, precompute=False, copy_X=True, max_iter=1000, tol=0.0001, warm_start=False, positive=False, random_state=None, selection=’cyclic’)
sklearn中使用类Lasso来调用lasso回归,众多参数中,比较重要的就是正则化系数α。另外需要注意的就是参数positive。当这个参数为"True"的时候,要求Lasso回归出的系数必须为正数,以此来保证α一定以增大来控制正则化的程度。
注意,sklearn中使用的损失函数是:
m i n ω 1 2 m ∣ ∣ X ω − y ∣ ∣ 2 2 + α ∣ ∣ ω ∣ ∣ 1 \large\boldsymbol{\mathop{min}\limits_\omega\frac1{2m}||X\omega-y||_2\,^2+\alpha||\omega||_1} ωmin2m1∣∣Xω−y∣∣22+α∣∣ω∣∣1
其中 1 2 m \Large\frac1{2m} 2m1(即: 1 n s a m p l e s \Large\frac1{n_{samples}} nsamples1)只是作为系数存在,用来消除损失函数求导后多出来的那个2的(求解ω时所带的1/2),然后对整体的RSS求平均而已,无论时从损失函数的意义来看还是从Lasso的性质和功能来看,这个变化没有造成任何影响,只不过让计算更加简便。
接下来,看看lasso如何做特征选择:
#Lasso做特征选择与线性回归和岭回归的比较
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge, LinearRegression, Lasso
from sklearn.model_selection import train_test_split as TTS
from sklearn.datasets import fetch_california_housing as fch
import matplotlib.pyplot as plt
housevalue = fch()
X = pd.DataFrame(housevalue.data)
y = housevalue.target
X.columns = ["住户收⼊入中位数","房屋使⽤用年年代中位数","平均房间数⽬目"
,"平均卧室数⽬目","街区⼈人⼝口","平均⼊入住率","街区的纬度","街区的经度"]
X.head()
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
#恢复索引
for i in [Xtrain,Xtest]:
i.index = range(i.shape[0])
#线性回归进行拟合
reg = LinearRegression().fit(Xtrain,Ytrain)
(reg.coef_*100).tolist()
[43.73589305968403,
1.0211268294494038,
-10.780721617317715,
62.64338275363783,
5.216125353178735e-05,
-0.33485096463336095,
-41.30959378947711,
-42.621095362084674]
#岭回归进⾏拟合
Ridge_ = Ridge(alpha=0).fit(Xtrain,Ytrain)
(Ridge_.coef_*100).tolist()
[43.735893059684045,
1.0211268294494151,
-10.780721617317626,
62.64338275363741,
5.2161253532713044e-05,
-0.3348509646333588,
-41.3095937894767,
-42.62109536208427]
#Lasso进行拟合
lasso_ = Lasso(alpha=0).fit(Xtrain,Ytrain)
(lasso_.coef_*100).tolist()
[43.735893059684024,
1.0211268294494056,
-10.78072161731769,
62.64338275363792,
5.2161253532654165e-05,
-0.33485096463335706,
-41.3095937894772,
-42.62109536208478]
可以看到,岭回归没有报出错误,但Lasso虽然依然对系数进行了计算,但是报出了整整三个红条:

这三条分别是这样的内容:
- 正则化系数为0,这样算法不可收敛!如果你想让正则化系数为0,请使用线性回归
- 没有正则项的坐标下降法可能会导致意外的结果,不鼓励这样做!
- 目标函数没有收敛,你也许想要增加迭代次数,使用一个非常小的alpha来拟合模型可能会造成精确度问题!
看到这三条内容,大家可能会比较懵——怎么出现了坐标下降?这是由于sklearn中的Lasso类不是使用最小二乘法来进行求解,而是使用坐标下降。考虑一下,Lasso既然不能够从根本解决多重共线性引起的最小二乘法无法使用的问题,那为什么要坚持最小二乘法呢?明明有其他更快更好的求解方法,比如坐标下降。下面两篇论文解释了了scikit-learn坐标下降求解器中使用的迭代方式,以及用于收敛控制的对偶间隙计算方式,感兴趣的可以阅读。
使用坐标下降法求解Lasso:
“Regularization Path For Generalized linear Models by Coordinate Descent”, Friedman, Hastie & Tibshirani, J Stat Softw, 2010 (Paper).
https://www.jstatsoft.org/article/view/v033i01/v33i01.pdf
“An Interior-Point Method for Large-Scale L1-Regularized Least Squares,” S. J. Kim, K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, in IEEE Journal of Selected Topics in Signal Processing, 2007 (Paper)
https://web.stanford.edu/~boyd/papers/pdf/l1_ls.pdf
有了坐标下降,就有迭代和收敛的问题,因此sklearn不推荐我们使用0这样的正则化系数。如果我们的确希望取到0,可以使用一个比较很小的数,比如0.01,或者10*e-3这样的值:
#岭回归进行拟合
Ridge_ = Ridge(alpha=0.01).fit(Xtrain,Ytrain)
(Ridge_.coef_*100).tolist()
[43.73575720621605,
1.0211292318121836,
-10.780460336251702,
62.64202320775686,
5.217068073243689e-05,
-0.3348506517067627,
-41.3095714322911,
-42.62105388932374]
#Lasso进行拟合
lasso_ = Lasso(alpha=0.01).fit(Xtrain,Ytrain)
(lasso_.coef_*100).tolist()
[40.10568371834486,
1.0936292607860143,
-3.7423763610244487,
26.524037834897207,
0.0003525368511503945,
-0.3207129394887799,
-40.06483047344844,
-40.81754399163315]
这样就不会报错了。
#加⼤正则项系数,观察模型的系数发⽣了什么变化
Ridge_ = Ridge(alpha=10**4).fit(Xtrain,Ytrain)
(Ridge_.coef_*100).tolist()
[34.620815176076945,
1.5196170869238694,
0.3968610529210133,
0.9151812510354866,
0.002173923801224843,
-0.34768660148101016,
-14.736963474215257,
-13.43557610252691]
lasso_ = Lasso(alpha=10**4).fit(Xtrain,Ytrain)
(lasso_.coef_*100).tolist()
[0.0, 0.0, 0.0, -0.0, -0.0, -0.0, -0.0, -0.0]
#看来10**4对于Lasso取值过大
lasso_ = Lasso(alpha=1).fit(Xtrain,Ytrain)
(lasso_.coef_*100).tolist()
[14.581141247629423,
0.6209347344423876,
0.0,
-0.0,
-0.00028065986329009983,
-0.0,
-0.0,
-0.0]
#将系数进⾏绘图
plt.plot(range(1,9),(reg.coef_*100).tolist(),color="red",label="LR")
plt.plot(range(1,9),(Ridge_.coef_*100).tolist(),color="orange",label="Ridge")
plt.plot(range(1,9),(lasso_.coef_*100).tolist(),color="k",label="Lasso")
plt.plot(range(1,9),[0]*8,color="grey",linestyle="--")
plt.xlabel('w') #横坐标是每⼀个特征所对应的系数
plt.legend()
plt.show()
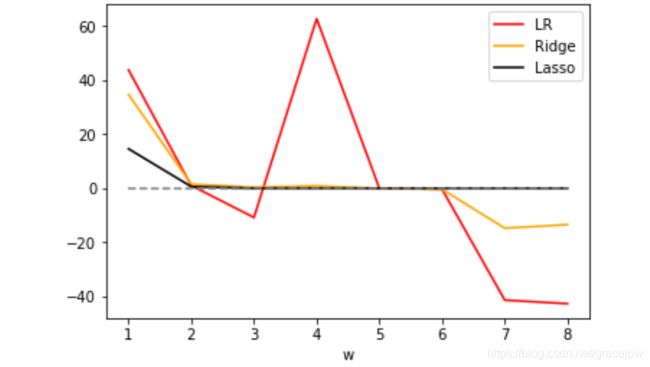
可见,比起岭回归,Lasso所带的L1正则项对于系数的惩罚要重得多,并且它会将系数压缩至0,因此可以被用来做特征选择。也因此,往往让Lasso的正则化系数在很小的空间中变动,以此来寻找最佳的正则化系数。
到这里,岭回归和Lasso的核心作用讲解完毕。
Lasso作为线性回归家族中在改良上走得最远的算法,还有许多领域待探讨。比如,现实中,不仅可以适用交叉验证来选择最佳正则化系数,也可以使用BIC( 贝叶斯信息准则)或者AIC(Akaike information criterion,艾凯克信息准则)来做模型选择。同时,可以不使用坐标下降法,而使用最小角度回归来对lasso进行计算。
注:
AIC和BIC主要用于模型的选择,AIC、BIC越小越好。
对不同模型进行比较时,AIC、BIC降低越多,说明该模型的拟合效果越好
AIC=2(模型参数的个数)-2ln(模型的极大似然函数)
BIC = ln(n)(模型中参数的个数) - 2ln(模型的极大似然函数值)
或表示为:
AIC=-2 ln(L) + 2 k 准则akaike information criterion
BIC=-2 ln(L) + ln(n)*k 准则bayesian information criterion
HQ=-2 ln(L) + ln(ln(n))*k 准则hannan-quinn criterion
其中L是在该模型下的最大似然,n是数据数量,k是模型的变量个数。