DataWhale夏令营第一期----脑PET图像分析和疾病预测挑战赛
本文原出处 https://aistudio.baidu.com/bd-cpu-01/user/2602285/6564384/lab 基于PaddleClas套件的脑PET图像分析和疾病预测挑战赛-baseline - 飞桨AI Studio (baidu.com)
AI夏令营 - CV实践教程 - 飞书云文档 (feishu.cn)
整理为个人学习所用。
近年来,深度学习在医学图像处理和疾病预测方面取得了显著的进展。脑PET(Positron Emission Tomography)图像是一种用于研究脑部功能和代谢活动的重要影像技术。本次挑战赛共给出了三种思路:
1、基于logistic回归的脑PET图像分析和疾病预测
1.1、准备数据集
为研究基于脑PET图像的疾病预测,本次大赛提供了海量脑PET数据集作为脑PET图像检测数据库的训练样本,参赛者需根据提供的样本构建模型,对轻度认知障碍进行分析和预测。脑PET图像检测数据库,记录了老年人受试志愿者的脑PET影像资料,其中包括确诊为轻度认知障碍(MCI)患者的脑部影像数据和健康人(NC)的脑部影像数据。 被试者按医学诊断分为两类:
- NC:健康
- MCI:轻度认知障碍
本次大赛所用脑PET图像检测数据库,图像格式为nii。

本次竞赛的评价标准采用F1_score,分数越高,效果越好。
数据集下载链接:https://ai-contest-static.xfyun.cn/2023/data/%E8%84%91PET%E5%9B%BE%E5%83%8F%E5%88%86%E6%9E%90%E5%92%8C%E7%96%BE%E7%97%85%E9%A2%84%E6%B5%8B%E6%8C%91%E6%88%98%E8%B5%9B%E5%85%AC%E5%BC%80%E6%95%B0%E6%8D%AE.zip
# 只需要运行一次
!pip install nibabel
# 解压数据集,只需要运行一次
!unzip /home/aistudio/data/data229672/脑PET图像分析和疾病预测挑战赛数据集.zip -d ./
# 重命名
!mv ─╘PET═╝╧ё╖╓╬Ў║═╝▓▓б╘д▓т╠Ї╒╜╚№╣л┐к╩¤╛▌ 脑PET图像分析和疾病预测挑战赛数据集1.2、数据预处理
读取训练集和测试集的文件路径,并对它们进行随机打乱,以保证数据的随机性。
# 读取训练集文件路径
train_path = glob.glob('./脑PET图像分析和疾病预测挑战赛数据集/Train/*/*')
test_path = glob.glob('./脑PET图像分析和疾病预测挑战赛数据集/Test/*')
# 打乱训练集和测试集的顺序
np.random.shuffle(train_path)
np.random.shuffle(test_path)1.3、特征提取
对于深度学习任务,特征提取是非常重要的一步。在本例中,我们定义了一个函数`extract_feature`,用于从脑PET图像中提取特征。
`extract_feature`函数从文件路径加载PET图像数据,并从中随机选择10个通道。然后,它计算了一系列统计特征,如非零像素数量、零像素数量、平均值、标准差等。最后,函数根据文件路径判断样本类别,并将提取到的特征和类别作为返回值。
def extract_feature(path):
# 加载PET图像数据
img = nib.load(path)
# 获取第一个通道的数据
img = img.dataobj[:, :, :, 0]
# 随机筛选其中的10个通道提取特征
random_img = img[:, :, np.random.choice(range(img.shape[2]), 10)]
# 对图片计算统计值
feat = [
(random_img != 0).sum(), # 非零像素的数量
(random_img == 0).sum(), # 零像素的数量
random_img.mean(), # 平均值
random_img.std(), # 标准差
len(np.where(random_img.mean(0))[0]), # 在列方向上平均值不为零的数量
len(np.where(random_img.mean(1))[0]), # 在行方向上平均值不为零的数量
random_img.mean(0).max(), # 列方向上的最大平均值
random_img.mean(1).max() # 行方向上的最大平均值
]
# 根据路径判断样本类别('NC'表示正常,'MCI'表示异常)
if 'NC' in path:
return feat + ['NC']
else:
return feat + ['MCI']1.4、模型训练
在这一步骤中,我们将利用extract_feature函数提取训练集和测试集的特征,并使用逻辑回归模型对训练集进行训练。
在这里,我们通过循环将特征提取过程重复进行30次,这是为了增加训练样本的多样性。然后,我们使用逻辑回归模型LogisticRegression来训练数据。在训练完成后,模型已经学习到了从特征到类别的映射关系。
# 对训练集进行30次特征提取,每次提取后的特征以及类别('NC'表示正常,'MCI'表示异常)被添加到train_feat列表中。
train_feat = []
for _ in range(30):
for path in train_path:
train_feat.append(extract_feature(path))
# 对测试集进行30次特征提取
test_feat = []
for _ in range(30):
for path in test_path:
test_feat.append(extract_feature(path))
# 使用训练集的特征作为输入,训练集的类别作为输出,对逻辑回归模型进行训练。
from sklearn.linear_model import LogisticRegression
m = LogisticRegression(max_iter=1000)
m.fit(
np.array(train_feat)[:, :-1].astype(np.float32), # 特征
np.array(train_feat)[:, -1] # 类别
)在`scikit-learn`(sklearn)中,除了逻辑回归(Logistic Regression)之外,还有许多其他的机器学习模型可以用于分类任务中,以下是一些常用于分类任务的机器学习模型:
1. 支持向量机(Support Vector Machines,SVM):用于二分类和多分类问题,通过构建一个超平面来区分不同类别的样本。
2. 决策树(Decision Trees):适用于二分类和多分类问题,通过对特征空间进行划分来分类样本。
3. 随机森林(Random Forests):基于多个决策树的集成算法,用于二分类和多分类问题,提高了模型的泛化能力。
4. K最近邻算法(K-Nearest Neighbors,KNN):根据最近邻样本的类别来分类新样本,适用于二分类和多分类问题。
5. 朴素贝叶斯(Naive Bayes):基于贝叶斯定理的分类方法,适用于文本分类等问题。
6. 多层感知器(Multi-layer Perceptrons,MLP):一种人工神经网络,用于解决复杂的分类问题。
7. 卷积神经网络(Convolutional Neural Networks,CNN):专用于处理图像和视觉数据的神经网络,在图像分类任务中表现出色。
这些模型在分类任务中有不同的应用场景和性能表现,取决于数据集的特征、样本数量和问题的复杂性。在实际应用中,通常需要根据数据集的特点和具体任务来选择合适的分类模型,并进行模型调参和性能评估,以达到最佳的分类效果。
1.5、预测与结果提交
在这一步骤中,我们使用训练好的逻辑回归模型对测试集进行预测,并将预测结果进行投票,选出最多的类别作为该样本的最终预测类别。最后,我们将预测结果存储在CSV文件中并提交结果。
具体来说,我们使用了Counter来统计每个样本的30次预测结果中最多的类别,并将结果存储在test_pred_label列表中。然后,我们将样本ID和对应的预测类别存储在一个DataFrame中,并将其按照ID排序后保存为CSV文件,这样我们就得到了最终的结果提交文件。
# 对测试集进行预测并进行转置操作,使得每个样本有30次预测结果。
test_pred = m.predict(np.array(test_feat)[:, :-1].astype(np.float32))
test_pred = test_pred.reshape(30, -1).T
# 对每个样本的30次预测结果进行投票,选出最多的类别作为该样本的最终预测类别,存储在test_pred_label列表中。
test_pred_label = [Counter(x).most_common(1)[0][0] for x in test_pred]
# 生成提交结果的DataFrame,其中包括样本ID和预测类别。
submit = pd.DataFrame(
{
'uuid': [int(x.split('/')[-1][:-4]) for x in test_path], # 提取测试集文件名中的ID
'label': test_pred_label # 预测的类别
}
)
# 按照ID对结果排序并保存为CSV文件
submit = submit.sort_values(by='uuid')
submit.to_csv('submit.csv', index=None)1.6、总结
本篇baseline介绍了如何使用Python编程语言和机器学习库处理脑PET图像数据,并构建逻辑回归模型来进行脑PET图像的疾病预测。特征提取是一个关键步骤,通过合适的特征提取方法,可以更好地表征图像数据。逻辑回归模型在本例中是一个简单而有效的分类器,但在实际应用中,可能需要更复杂的深度学习模型来提高预测性能。
2、基于PaddleClas套件的脑PET图像分析和疾病预测挑战赛
2.1、模型简介
PP-HGNet(High Performance GPU Net) 是百度飞桨视觉团队自研的更适用于 GPU 平台的高性能骨干网络,该网络在 VOVNet 的基础上使用了可学习的下采样层(LDS Layer),融合了 ResNet_vd、PPHGNet 等模型的优点,该模型在 GPU 平台上与其他 SOTA 模型在相同的速度下有着更高的精度。在同等速度下,该模型高于 ResNet34-D 模型 3.8 个百分点,高于 ResNet50-D 模型 2.4 个百分点,在使用百度自研 SSLD 蒸馏策略后,超越 ResNet50-D 模型 4.7 个百分点。与此同时,在相同精度下,其推理速度也远超主流 VisionTransformer 的推理速度。
PP-HGNet 作者针对 GPU 设备,对目前 GPU 友好的网络做了分析和归纳,尽可能多的使用 3x3 标准卷积(计算密度最高)。在此将 VOVNet 作为基准模型,将主要的有利于 GPU 推理的改进点进行融合。从而得到一个有利于 GPU 推理的骨干网络,同样速度下,精度大幅超越其他 CNN 或者 VisionTransformer 模型。
PP-HGNet 骨干网络的整体结构如下:
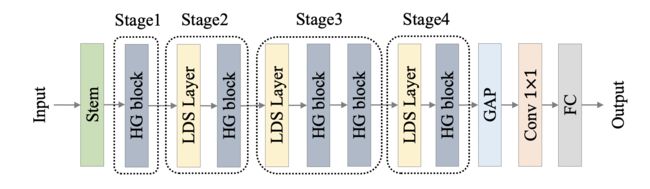
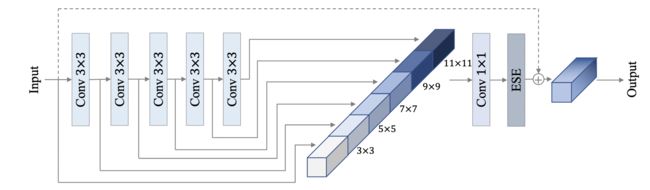
其中,PP-HGNet是由多个HG-Block组成,HG-Block的细节如下:
2.2、训练配置
在 ppcls/configs/ImageNet/PPHGNet/PPHGNet_small.yaml 中提供了 PPHGNet_small 训练配置,按照下面的配置要求进行修改。
# 1.全局配置
Global:
checkpoints: null # 检查点保存路径,null表示不保存检查点
pretrained_model: https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/legendary_models/PPHGNet_small_ssld_pretrained.pdparams # 预训练模型的路径
output_dir: ./output/ # 输出目录的路径
device: gpu # 使用的设备,此处为GPU
save_interval: 10 # 模型保存的间隔步数
eval_during_train: True # 训练过程中是否进行评估
eval_interval: 1 # 评估的间隔步数
epochs: 600 # 训练的总轮数
print_batch_step: 10 # 打印训练过程中的批次步数
use_visualdl: True # 是否使用VisualDL进行可视化
image_shape: [3, 224, 224] # 图像的形状,通道数为3,高度和宽度为224
save_inference_dir: ./inference # 导出预测模型的保存路径
to_static: False # 是否在静态模式下训练模型
use_dali: False # 是否使用DALI进行数据加载
# 2.混合精度训练
AMP:
scale_loss: 128.0 # 损失放缩的比例因子
use_dynamic_loss_scaling: True # 是否使用动态损失放缩
level: O1 # 混合精度级别,此处为O1级别,即混合精度浮点数
# 3.模型架构
Arch:
name: PPHGNet_small # 模型的名称
class_num: 2 # 分类的类别数
# 4.训练/评估过程中的损失函数配置
Loss:
Train: # 训练时的损失函数配置
- CELoss: # 交叉熵损失函数
weight: 1.0 # 损失函数的权重
epsilon: 0.1 # 避免计算中的除零错误的小常数
Eval: # 评估时的损失函数配置
- CELoss: # 交叉熵损失函数
weight: 1.0 # 损失函数的权重
# 5.优化器配置
Optimizer:
name: Momentum # 优化器的名称
momentum: 0.9 # 动量因子
lr: # 学习率配置
name: Cosine # 学习率衰减方式为余弦衰减
learning_rate: 0.001 # 初始学习率
warmup_epoch: 5 # 学习率预热的轮数
regularizer: # 正则化配置
name: 'L2' # 正则化方式为L2正则化
coeff: 0.00004 # 正则化系数
# 6.训练和评估的数据加载器配置
DataLoader:
# 6.1 训练数据加载器配置
Train:
dataset: # 数据集配置
name: ImageNetDataset # 数据集的名称
image_root: ./dataset/ # 图像文件的根目录路径
cls_label_path: ./dataset/train_list.txt # 分类标签文件的路径
transform_ops: # 数据预处理操作列表
- DecodeImage: # 图像解码操作
to_rgb: True # 转换为RGB格式
channel_first: False # 通道在最后一维
- RandCropImage: # 随机裁剪操作
size: 224 # 裁剪后的大小
interpolation: bicubic # 插值方法为双三次插值
backend: pil # 使用PIL库进行图像处理
- RandFlipImage: # 随机翻转操作
flip_code: 1 # 水平翻转
- TimmAutoAugment: # 图像自动增强操作
config_str: rand-m7-mstd0.5-inc1 # 增强配置字符串
interpolation: bicubic # 插值方法为双三次插值
img_size: 224 # 图像的大小
- NormalizeImage: # 图像归一化操作
scale: 1.0/255.0 # 缩放比例
mean: [0.485, 0.456, 0.406] # RGB图像的均值
std: [0.229, 0.224, 0.225] # RGB图像的标准差
order: '' # 通道顺序为空,表示使用RGB顺序
- RandomErasing: # 随机擦除操作
EPSILON: 0.25 # 擦除的像素值
sl: 0.02 # 擦除区域的最小比例
sh: 1.0/3.0 # 擦除区域的最大比例
r1: 0.3 # 擦除区域的纵横比范围
attempt: 10 # 尝试擦除的次数
use_log_aspect: True # 使用对数纵横比
mode: pixel # 擦除模式为像素级别
batch_transform_ops: # 批次预处理操作列表
- OpSampler: # 操作采样器
MixupOperator: # Mixup操作
alpha: 0.2 # Mixup的超参数alpha
prob: 0.5 # Mixup的概率
CutmixOperator: # CutMix操作
alpha: 1.0 # CutMix的超参数alpha
prob: 0.5 # CutMix的概率
sampler: # 数据采样器配置
name: DistributedBatchSampler # 采样器的名称
batch_size: 128 # 批次大小
drop_last: False # 是否丢弃最后一个不完整的批次
shuffle: True # 是否在每个epoch之前对数据进行洗牌
loader: # DataLoader配置
num_workers: 16 # 数据加载器使用的线程数
use_shared_memory: True # 是否使用共享内存进行数据加载
# 6.2 评估数据加载器配置
Eval:
dataset: # 数据集配置
name: ImageNetDataset # 数据集的名称
image_root: ./dataset # 图像文件的根目录路径
cls_label_path: ./dataset/val_list.txt # 分类标签文件的路径
transform_ops: # 数据预处理操作列表
- DecodeImage: # 图像解码操作
to_rgb: True # 转换为RGB格式
channel_first: False # 通道在最后一维
- ResizeImage: # 图像缩放操作
resize_short: 236 # 缩放后的短边大小
interpolation: bicubic # 插值方法为双三次插值
backend: pil # 使用PIL库进行图像处理
- CropImage: # 图像裁剪操作
size: 224 # 裁剪后的大小
- NormalizeImage: # 图像归一化操作
scale: 1.0/255.0 # 缩放比例
mean: [0.485, 0.456, 0.406] # RGB图像的均值
std: [0.229, 0.224, 0.225] # RGB图像的标准差
order: '' # 通道顺序为空,表示使用RGB顺序
sampler: # 数据采样器配置
name: DistributedBatchSampler # 采样器的名称
batch_size: 128 # 批次大小
drop_last: False # 是否丢弃最后一个不完整的批次
shuffle: False # 是否在每个epoch之前对数据进行洗牌
loader: # DataLoader配置
num_workers: 16 # 数据加载器使用的线程数
use_shared_memory: True # 是否使用共享内存进行数据加载
# 7.推理配置
Infer:
infer_imgs: docs/images/inference_deployment/whl_demo.jpg # 推理使用的图像路径
batch_size: 10 # 推理时的批次大小
transforms: # 推理数据预处理操作列表
- DecodeImage: # 图像解码操作
to_rgb: True # 转换为RGB格式
channel_first: False # 通道在最后一维
- ResizeImage: # 图像缩放操作
resize_short: 236 # 缩放后的短边大小
interpolation: bicubic # 插值方法为双三次插值
backend: pil # 使用PIL库进行图像处理
- CropImage: # 图像裁剪操作
size: 224 # 裁剪后的大小
- NormalizeImage: # 图像归一化操作
scale: 1.0/255.0 # 缩放比例
mean: [0.485, 0.456, 0.406] # RGB图像的均值
std: [0.229, 0.224, 0.225] # RGB图像的标准差
order: '' # 通道顺序为空,表示使用RGB顺序
- ToCHWImage: # 图像通道顺序转换操作,从HWC转换为CHW
# 8.推理后处理配置
PostProcess:
name: Topk # 后处理的名称
topk: 5 # 返回概率最高的前k个类别
class_id_map_file: ./dataset/labels.txt # 类别ID映射文件的路径
# 9.评估指标配置
Metric:
Train: # 训练时的评估指标配置
- TopkAcc: # Top-k准确率指标
topk: [1, 5] # 计算Top-1和Top-5准确率
Eval: # 评估时的评估指标配置
- TopkAcc: # Top-k准确率指标
topk: [1, 5] # 计算Top-1和Top-5准确率%cd /home/aistudio/PaddleClas
# 通过如下脚本启动训练,断点恢复训练:-o Global.checkpoints="output/PPHGNet_small/latest"
!export CUDA_VISIBLE_DEVICES=0
!python3 -m paddle.distributed.launch \
--gpus="0" \
tools/train.py \
-c ppcls/configs/ImageNet/PPHGNet/PPHGNet_small.yaml \2.3、模型评估
训练好模型之后,可以通过以下命令实现对模型指标的评估。
# 其中 `-o Global.pretrained_model="output/PPHGNet_small/best_model"` 指定了当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。
%cd /home/aistudio/PaddleClas
!python3 tools/eval.py \
-c ppcls/configs/ImageNet/PPHGNet/PPHGNet_small.yaml \
-o Global.pretrained_model=output/PPHGNet_small/best_model2.4、模型推理部署
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。相比于直接基于预训练模型进行预测,Paddle Inference可使用MKLDNN、CUDNN、TensorRT 进行预测加速,从而实现更优的推理性能。更多关于Paddle Inference推理引擎的介绍,可以参考Paddle Inference官网教程。
当使用 Paddle Inference 推理时,加载的模型类型为 inference 模型。本案例提供了两种获得 inference 模型的方法,如果希望得到和文档相同的结果,请选择直接下载 inference 模型的方式。
2.4.1、基于训练得到的权重导出 inference 模型
此处,我们提供了将权重和模型转换的脚本,执行该脚本可以得到对应的 inference 模型:
!python3 tools/export_model.py \
-c ppcls/configs/ImageNet/PPHGNet/PPHGNet_small.yaml \
-o Global.pretrained_model=output/PPHGNet_small/best_model \
-o Global.save_inference_dir=deploy/models/PPHGNet_small_infer 执行完该脚本后会在 deploy/models/ 下生成 PPHGNet_small_infer 文件夹,models 文件夹下应有如下文件结构:
├── PPHGNet_small_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel2.5、基于 Python 预测引擎推理
2.5.1、基于文件夹的批量预测
如果希望预测文件夹内的图像,可以直接修改配置文件中的 Global.infer_imgs 字段,也可以通过下面的 -o 参数修改对应的配置。
终端中会输出该文件夹内所有图像的分类结果,如下所示。
修改/home/aistudio/PaddleClas/deploy/python/predict_cls.py 中的 def main(config): 部分
def main(config):
cls_predictor = ClsPredictor(config)
image_list = get_image_list(config["Global"]["infer_imgs"])
batch_imgs = []
batch_names = []
cnt = 0
# 打开submit.csv文件并写入表头
csvfile = open('/home/aistudio/result.csv', 'w', newline='')
writer = csv.writer(csvfile)
writer.writerow(['filename', 'label'])
for idx, img_path in enumerate(image_list):
img = cv2.imread(img_path)
if img is None:
logger.warning(
"Image file failed to read and has been skipped. The path: {}".
format(img_path))
else:
img = img[:, :, ::-1]
batch_imgs.append(img)
img_name = os.path.basename(img_path)
batch_names.append(img_name)
cnt += 1
if cnt % config["Global"]["batch_size"] == 0 or (idx + 1
) == len(image_list):
if len(batch_imgs) == 0:
continue
batch_results = cls_predictor.predict(batch_imgs)
# 循环处理每个图片的结果
for number, result_dict in enumerate(batch_results):
filename = batch_names[number]
label_name = result_dict["label_names"][0]
# 写入CSV文件
writer.writerow([filename.split('.')[0], label_name])
batch_imgs = []
batch_names = []
if cls_predictor.benchmark:
cls_predictor.auto_logger.report()
csvfile.close()
return
# 使用下面的命令使用 GPU 进行预测,如果希望使用 CPU 预测,可以在命令后面添加 -o Global.use_gpu=False
%cd /home/aistudio/PaddleClas/deploy
# 将推理结果存储在result.csv中
!python3 python/predict_cls.py \
-c configs/inference_cls.yaml \
-o Global.inference_model_dir=models/PPHGNet_small_infer \
-o Global.infer_imgs=/home/aistudio/PaddleClas/dataset/Test2.6、对每个类别的预测结果进行投票
%cd /home/aistudio/
# 统计submit.csv中每张nii图片,推理成 MCI 和 NC 的次数,并将结果保存在 result1.csv 中
import csv
def count_labels(input_file):
counts = {} # 创建一个空字典用于存储每个filename前缀对应的NC和MCI的出现次数
with open(input_file, 'r') as csvfile:
reader = csv.reader(csvfile)
next(reader) # 跳过表头
for row in reader:
filename, label = row # 从CSV文件中读取每一行的文件名和标签
prefix = filename.split('_')[0] # 获取文件名的前缀部分
if prefix not in counts:
counts[prefix] = {'NC': 0, 'MCI': 0} # 如果前缀不在字典中,创建一个新的记录
counts[prefix][label] += 1 # 统计该前缀下对应标签的出现次数
return counts
def write_to_csv(output_file, counts):
with open(output_file, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['filename', 'result', 'NC', 'MCI']) # 写入表头
# 对counts字典按照filename进行排序
sorted_counts = sorted(counts.items(), key=lambda item: item[0])
for filename, label_counts in sorted_counts:
nc_count = label_counts.get('NC', 0) # 获取该前缀下NC标签的出现次数,如果不存在则默认为0
mci_count = label_counts.get('MCI', 0) # 获取该前缀下MCI标签的出现次数,如果不存在则默认为0
# 决定result标签,取NC和MCI中出现次数最多的标签
result_label = 'NC' if nc_count >= mci_count else 'MCI'
writer.writerow([filename, result_label, nc_count, mci_count]) # 写入前缀、NC和MCI标签的出现次数以及结果标签
if __name__ == "__main__":
input_file = "result.csv"
output_file = "result1.csv"
label_counts = count_labels(input_file) # 统计标签出现次数
write_to_csv(output_file, label_counts) # 将结果写入CSV文件
# 只写入当前行的前两列到result1.csv,将submit.csv作为结果进行提交
import csv
def write_result1(input_file, output_file):
with open(input_file, 'r') as csvfile:
reader = csv.reader(csvfile)
next(reader) # 跳过表头
with open(output_file, 'w', newline='') as result1file:
writer = csv.writer(result1file)
# 写入表头
writer.writerow(['uuid', 'label'])
for row in reader:
writer.writerow(row[:2])
if __name__ == "__main__":
input_file = "result1.csv"
output_file = "submit.csv"
write_result1(input_file, output_file)3、CNN
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,广泛用于图像识别、计算机视觉和模式识别任务中。CNN 在处理具有网格结构数据(如图像)时表现出色,它能够自动学习和提取图像中的特征,并在分类、定位和分割等任务中取得优秀的性能。
方法优缺点(运行时间20分钟,如果有GPU可以更快):
-
CNN带来的精度更好,但需要训练更长的时间
-
CNN模型调优需要GPU
3.1、自定义数据集
import os, sys, glob, argparse
import pandas as pd
import numpy as np
from tqdm import tqdm
import cv2
from PIL import Image
from sklearn.model_selection import train_test_split, StratifiedKFold, KFold
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
import nibabel as nib
from nibabel.viewers import OrthoSlicer3D
train_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Train/*/*')
test_path = glob.glob('./脑PET图像分析和疾病预测挑战赛公开数据/Test/*')
np.random.shuffle(train_path)
np.random.shuffle(test_path)
DATA_CACHE = {}
class XunFeiDataset(Dataset):
def __init__(self, img_path, transform=None):
self.img_path = img_path
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
if self.img_path[index] in DATA_CACHE:
img = DATA_CACHE[self.img_path[index]]
else:
img = nib.load(self.img_path[index])
img = img.dataobj[:,:,:, 0]
DATA_CACHE[self.img_path[index]] = img
# 随机选择一些通道
idx = np.random.choice(range(img.shape[-1]), 50)
img = img[:, :, idx]
img = img.astype(np.float32)
if self.transform is not None:
img = self.transform(image = img)['image']
img = img.transpose([2,0,1])
return img,torch.from_numpy(np.array(int('NC' in self.img_path[index])))
def __len__(self):
return len(self.img_path)
import albumentations as A
train_loader = torch.utils.data.DataLoader(
XunFeiDataset(train_path[:-10],
A.Compose([
A.RandomRotate90(),
A.RandomCrop(120, 120),
A.HorizontalFlip(p=0.5),
A.RandomContrast(p=0.5),
A.RandomBrightnessContrast(p=0.5),
])
), batch_size=2, shuffle=True, num_workers=1, pin_memory=False
)
val_loader = torch.utils.data.DataLoader(
XunFeiDataset(train_path[-10:],
A.Compose([
A.RandomCrop(120, 120),
])
), batch_size=2, shuffle=False, num_workers=1, pin_memory=False
)
test_loader = torch.utils.data.DataLoader(
XunFeiDataset(test_path,
A.Compose([
A.RandomCrop(128, 128),
A.HorizontalFlip(p=0.5),
A.RandomContrast(p=0.5),
])
), batch_size=2, shuffle=False, num_workers=1, pin_memory=False
)
3.2、自定义CNN模型
class XunFeiNet(nn.Module):
def __init__(self):
super(XunFeiNet, self).__init__()
model = models.resnet18(True)
model.conv1 = torch.nn.Conv2d(50, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(512, 2)
self.resnet = model
def forward(self, img):
out = self.resnet(img)
return out
model = XunFeiNet()
model = model.to('cuda')
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.AdamW(model.parameters(), 0.001)3.3、模型训练与验证
def train(train_loader, model, criterion, optimizer):
model.train()
train_loss = 0.0
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 20 == 0:
print(loss.item())
train_loss += loss.item()
return train_loss/len(train_loader)
def validate(val_loader, model, criterion):
model.eval()
val_acc = 0.0
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
val_acc += (output.argmax(1) == target).sum().item()
return val_acc / len(val_loader.dataset)
for _ in range(3):
train_loss = train(train_loader, model, criterion, optimizer)
val_acc = validate(val_loader, model, criterion)
train_acc = validate(train_loader, model, criterion)
print(train_loss, train_acc, val_acc)3.4、模型预测与提交
def predict(test_loader, model, criterion):
model.eval()
val_acc = 0.0
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
input = input.cuda()
target = target.cuda()
output = model(input)
test_pred.append(output.data.cpu().numpy())
return np.vstack(test_pred)
pred = None
for _ in range(10):
if pred is None:
pred = predict(test_loader, model, criterion)
else:
pred += predict(test_loader, model, criterion)
submit = pd.DataFrame(
{
'uuid': [int(x.split('/')[-1][:-4]) for x in test_path],
'label': pred.argmax(1)
})
submit['label'] = submit['label'].map({1:'NC', 0: 'MCI'})
submit = submit.sort_values(by='uuid')
submit.to_csv('submit2.csv', index=None)
附录 - 实践环境配置
AI环境配置:
-
视频讲解:AI夏令营:手把手带你配置AI环境_哔哩哔哩_bilibili
-
图文材料:https://gitee.com/anine09/learn-python-the-smart-way-v2/blob/main/slides/chapter_0-Installation.ipynb
其他材料
-
python环境的搭建请参考:
-
Mac设备:Mac上安装Anaconda最全教程
-
Windows设备:Anaconda超详细安装教程(Windows环境下)_菜鸟1号!!的博客-CSDN博客_windows安装anaconda
-
-
Jupyter 编辑器的使用请参考:
-
Jupyter Notebook最全使用教程,看这篇就够了!
-