Redis集群搭建
4. Redis集群
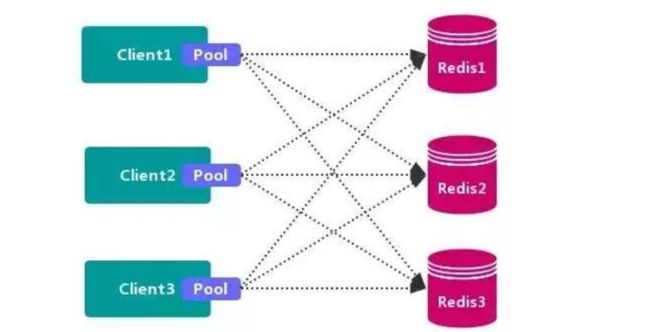
4.1 redis集群形式
4.1.1 数据分区方案
优点:
不使用 第三方中间件, 分区逻辑 可控, 配置 简单, 节点之间无关联, 容易 线性扩展, 灵活性强。
缺点:
**客户端 无法 动态增删 服务节点, 客户端需要自行维护 分发逻辑, 客户端之间 无连接共享,会造成 连接浪费。 **
4.1.2 代理分区
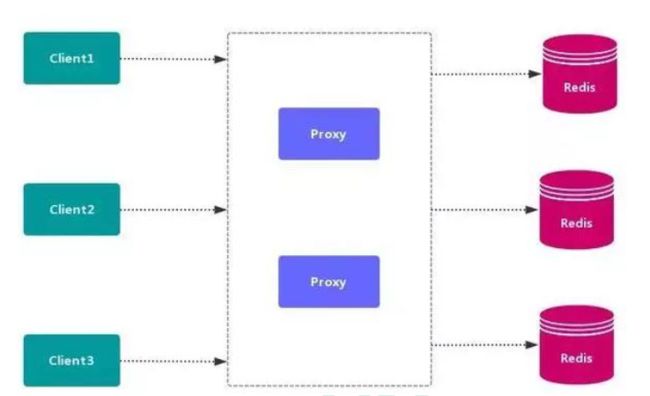
代理分区常用方案有 Twemproxy 和 Codis,类似于mysql的sharding proxy。
4.1.3 redis-cluster

Redis Cluster 是 Redis 原生的数据分片实现,可以自动在多个节点上分布数据,不需要依赖任何外部的工具。
优点:
高性能- Redis Cluster 的性能与单节点部署是同级别的。
高可用- Redis Cluster 支持标准的
master-replica配置来保障高可用和高可靠。 - Redis Cluster 也实现了一个类似 Raft 的共识方式,来保障整个集群的可用性。
- Redis Cluster 支持标准的
易扩展- 向 Redis Cluster 中添加新节点,或者移除节点,都是透明的,不需要停机。水平、垂直方向都非常容易扩展。
原生- 部署 Redis Cluster 不需要其他的代理或者工具,而且 Redis Cluster 和单机 Redis 几乎完全兼容。
缺点(限制):
-
需要客户端支持- 客户端需要修改,以便支持 Redis Cluster。虽然 Redis Cluster 已经发布有几年时间了,但仍然有些客户端是不支持的,所以需要到 Redis 官网去查询一下。
-
只支持一个数据库- 不像单机Redis,Redis Cluster 只支持一个数据库(database 0),
select命令就不能用了,但实际也很少有人使用多数据库,所以这个限制并没什么影响。
- 不像单机Redis,Redis Cluster 只支持一个数据库(database 0),
-
Multi-Key 操作受限
-
Redis Cluster 要求,只有这些 key 都在同一个 slot 时才能执行。
-
例如,有2个key,key1 和 key2。
key1 是映射到 5500 这个 slot 上,存储在 Node A。
key2 是映射到 5501 这个 slot 上,存储在 Node B。
那么就不能对 key1 和 key2 做事务操作。
-
-
4.1.3.1 Multi-Key 限制的处理
对于多key场景,需要做好数据空间的设计,Redis Cluster 提供了一个 hash tag 的机制,可以让我们把一组key 映射到同一个 slot。
例如:user1000.following 这个 key 保存用户 user1000 关注的用户;user1000.followers 保存用户 user1000 的粉丝。
这两个 key 有一个共同的部分 user1000,可以指定对这个共同的部分做 slot 映射计算,这样他们就可以在同一个槽中了。
使用方式:
{user1000}.following 和 {user1000}.followers
就是把共同的部分使用 { } 包起来,计算 slot 值时,如果发现了花括号,就会只对其中的部分进行计算。
Multi-Key 这一点是 Redis Cluster 对于我们日常使用中最大的限制,一定要注意,如果多key不在同一个 slot 中就会报错,例如:
(error) CROSSSLOT Keys in request don't hash to the same slot
需要使用 hash tag 设计好 key 的空间。
4.2 高可用方式
4.2.1 Sentinel( 哨兵机制) 支持高可用
前面介绍了主从机制, 但是从运维角度来看, 主节点出现了问题我们还需要通过人工干预的方式把从节点设为主节点, 还要通知应用程序更新主节点地址, 这种方式非常繁琐笨重, 而且主节点的读写能力都十分有限, 有没有较好的办法解决这两个问题, 哨兵机制就是针对第一个问题的有效解决方案, 第二个问题则有赖于集群! 哨兵的作用就是监控 Redis 系统的运行状况, 其功能主要是包括以下三个:
监控(Monitoring): 哨兵(sentinel) 会不断地检查你的 Master 和 Slave 是否运作正常。提醒(Notification): 当被监控的某个 Redis 出现问题时, 哨兵(sentinel) 可以通过 API向管理员或者其他应用程序发送通知。自动故障迁移(Automatic failover): 当主数据库出现故障时自动将从数据库转换为主数据库。
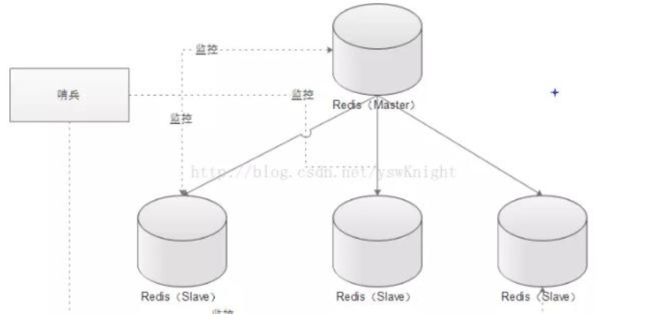
4.2.1.1 哨兵原理
Redis 哨兵的三个定时任务, Redis 哨兵判定一个 Redis 节点故障不可达主要就是通过三个定时监控任务来完成的:
-
每隔 10 秒每个哨兵节点会向主节点和从节点发送"info replication" 命令来获取最新的拓扑结构

-
每隔 2 秒每个哨兵节点会向 Redis 节点的_sentinel_:hello 频道发送自己对主节点是否故障的判断以及自身的节点信息, 并且其他的哨兵节点也会订阅这个频道来了解其他哨兵节点的信息以及对主节点的判断
-
每隔 1 秒每个哨兵会向主节点、 从节点、 其他的哨兵节点发送一个 “ping” 命令来做心跳检测
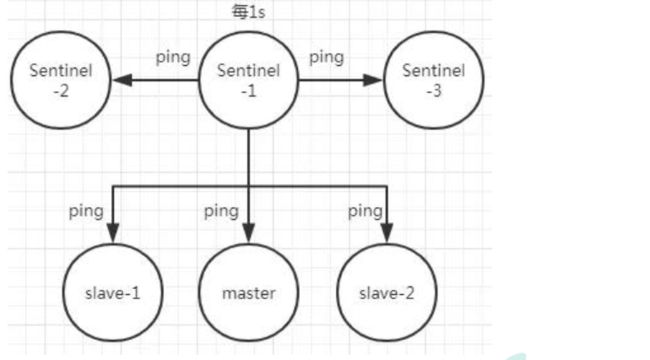
如果在定时 Job3 检测不到节点的心跳, 会判断为**“主观下线”。 如果该节点还是主节点那么还会通知到其他的哨兵对该主节点进行心跳检测, 这时主观下线的票数超过了数时, 那么这个主节点确实就可能是故障不可达了, 这时就由原来的主观下线变为了“客观下线”**。
故障转移和 Leader 选举
如果主节点被判定为客观下线之后, 就要选取一个哨兵节点来完成后面的故障转移工作, 选举出一个 leader, 这里面采用的选举算法为 Raft。 选举出来的哨兵 leader 就要来完成故障转移工作, 也就是在从节点中选出一个节点来当新的主节点, 这部分的具体流程可参考引用
4.2.2 Redis-Cluster
https://redis.io/topics/cluster-tutorial/
Redis 的官方多机部署方案, Redis Cluster。 一组 Redis Cluster 是由多个 Redis 实例组成, 官方推荐我们使用 6 实例, 其中 3 个为主节点, 3 个为从结点。 一旦有主节点发生故障的时候,Redis Cluster 可以选举出对应的从结点成为新的主节点, 继续对外服务, 从而保证服务的高可用性。那么对于客户端来说, 知道知道对应的 key 是要路由到哪一个节点呢? Redis Cluster把所有的数据划分为 16384 个不同的槽位, 可以根据机器的性能把不同的槽位分配给不同的 Redis 实例, 对于 Redis 实例来说, 他们只会存储部分的 Redis 数据, 当然, 槽的数据是可以迁移的, 不同的实例之间, 可以通过一定的协议, 进行数据迁移。
4.2.2.1 槽

Redis 集群的功能限制; Redis 集群相对 单机 在功能上存在一些限制, 需要 开发人员 提前了解, 在使用时做好规避。 [JAVA CRC16 校验算法](JAVA CRC16校验算法_Levent的博客-CSDN博客_javacrc16校验)
-
key 批量操作 支持有限。
- 类似 mset、 mget 操作, 目前只支持对具有相同 slot 值的 key 执行 批量操作。对于 映射为不同 slot 值的 key 由于执行 mget、 mget 等操作可能存在于多个节点上, 因此不被支持。
-
key 事务操作 支持有限。
- 只支持 多 key 在 同一 节点上 的 事务操作, 当多个 key 分布在 不同 的节点上时 无法 使用事务功能。
-
key 作为 数据分区 的最小粒度
-
不能将一个 大的键值 对象如 hash、 list 等映射到 不同的节点。
-
不支持 多数据库空间
- 单机 下的 Redis 可以支持 16 个数据库(db0 ~ db15) , 集群模式 下只能使用 一个 数据库空间, 即 db0。
-
复制结构 只支持一层
- 从节点 只能复制 主节点, 不支持 嵌套树状复制 结构。
-
命令大多会重定向, 耗时多
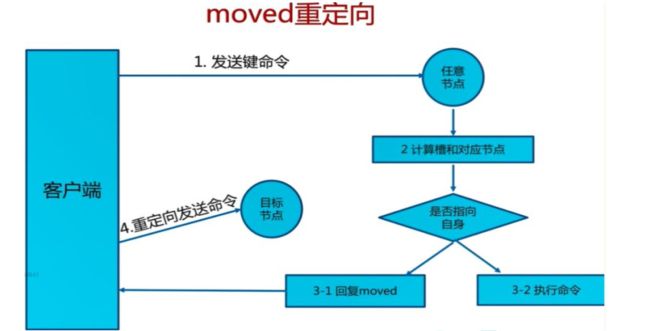
4.2.2.2 一致性 hash
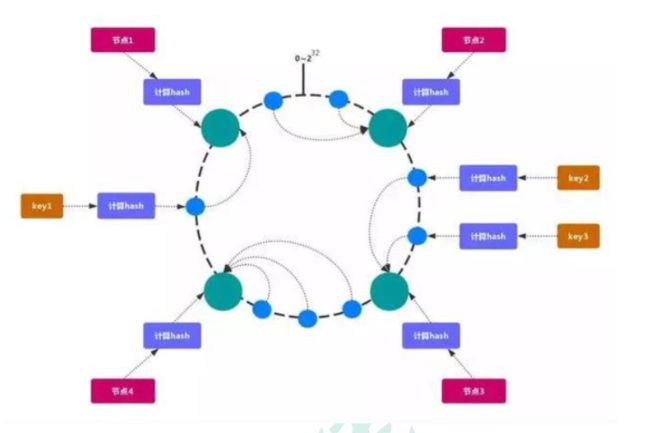
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
对一致性哈希的理解
原文链接:https://juejin.cn/post/6844903750860013576
简单的说,一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设哈希函数H的值空间为0-2^32-1(哈希值是32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织,0和2^32-1在零点中方向重合。
接下来,把服务器按照IP或主机名作为关键字进行哈希,这样就能确定其在哈希环的位置。

然后,我们就可以使用哈希函数H计算值为key的数据在哈希环的具体位置h,根据h确定在环中的具体位置,从此位置沿顺时针滚动,遇到的第一台服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
根据一致性哈希算法,数据A会被定为到Server 1上,数据B被定为到Server 2上,而C、D被定为到Server 3上。
4.2.2.2.1 一致性hash,hash倾斜问题
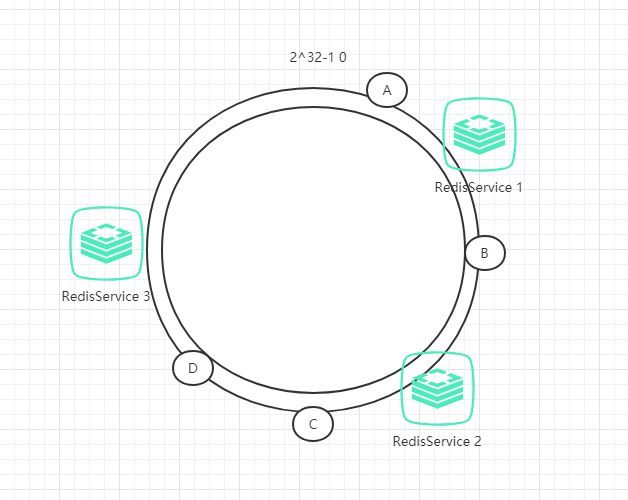
如果节点很少, 容易出现倾斜, 负载不均衡问题。 一致性哈希算法, 引入了虚拟节点, 在整个环上, 均衡增加若干个节点。 比如 a1, a2, b1, b2, c1, c2, a1 和 a2 都是属于 A 节点的。 解决 hash 倾斜问题
具体做法
具体做法可以在服务器IP或主机名的后面增加编号来实现,例如上面的情况,可以为每个服务节点增加三个虚拟节点,于是可以分为 RedisService1#1、 RedisService1#2、 RedisService1#3、 RedisService2#1、 RedisService2#2、 RedisService2#3,具体位置如下图所示:

对于数据定位的hash算法仍然不变,只是增加了虚拟节点到实际节点的映射。例如,数据C保存到虚拟节点Redis1#2,实际上数据保存到Redis1中。这样,就能解决服务节点少时数据不平均的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
4.2.3 部署Cluster

4.2.3.1 创建6个redis节点(3 主 3 从方式,从为了同步备份,主进行 slot 数据分片 )
for port in $(seq 7001 7006); \
do \
mkdir -p /mydata/redis/node-${port}/conf
touch /mydata/redis/node-${port}/conf/redis.conf
cat << EOF >/mydata/redis/node-${port}/conf/redis.conf
port ${port}
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 192.168.157.128
cluster-announce-port ${port}
cluster-announce-bus-port 1${port}
appendonly yes
EOF
docker run -p ${port}:${port} -p 1${port}:1${port} --name redis-${port} \
-v /mydata/redis/node-${port}/data:/data \
-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \
-d redis:5.0.7 redis-server /etc/redis/redis.conf; \
done
port:节点端口;requirepass:添加访问认证;masterauth:如果主节点开启了访问认证,从节点访问主节点需要认证;protected-mode:保护模式,默认值 yes,即开启。开启保护模式以后,需配置bind ip或者设置访问密码;关闭保护模式,外部网络可以直接访问;daemonize:是否以守护线程的方式启动(后台启动),默认 no;appendonly:是否开启 AOF 持久化模式,默认 no;cluster-enabled:是否开启集群模式,默认 no;cluster-config-file:集群节点信息文件;cluster-node-timeout:集群节点连接超时时间;cluster-announce-ip:集群节点 IP,填写宿主机的 IP;cluster-announce-port:集群节点映射端口;cluster-announce-bus-port:集群节点总线端口。


如想停用或删除所有节点
#停用所有节点
docker stop $(docker ps -a |grep redis-700 | awk '{ print $1}')
#删除所有容器
docker rm $(docker ps -a |grep redis-700 | awk '{ print $1}')
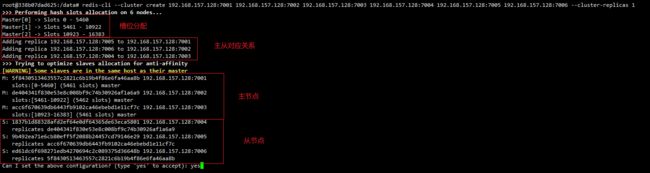
4.2.3.2 使用redis建立集群
这里我们将redis-7001作为主节点
#进入redis-7001容器
docker exec -it redis-7001 bash
#创建一个集群,拉入集群成员
redis-cli --cluster create 192.168.157.128:7001 192.168.157.128:7002 192.168.157.128:7003 192.168.157.128:7004 192.168.157.128:7005 192.168.157.128:7006 --cluster-replicas 1
redis-cluster会为我们自动分配节点
4.2.3.3 测试集群效果
#随便进入一个redis容器
docker exec -it redis-7002 /bin/bash
#使用 redis-cli 的 cluster 方式进行连接(get/set命令可以对其他节点进行操作)
redis-cli -c -h 192.168.157.128 -p 7006
#获取节点信息
cluster info
#获取集群节点
cluster nodes
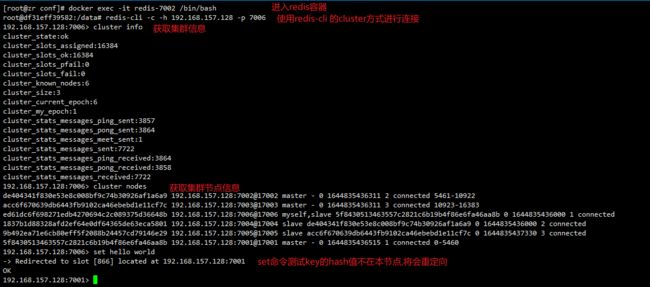
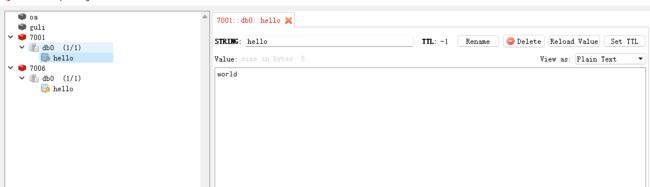
之前set了一个key为hello的数据,被重定向到7001,使用redis-manager连上7001及7001的从机7006看看

4.2.3.3.1 模拟主节点宕机
关闭主节点7001
docker stop redis-7001
查看节点信息
7001节点失去连接,其从节点7006变为主节点

重启7001,查看节点信息
7001变为7006的从节点
