论文阅读笔记之——《CBAM: Convolutional Block Attention Module》
目录
Attention Mechanism
Channel attention module
Spatial attention module
论文:https://arxiv.org/pdf/1807.06521.pdf
代码实现:https://github.com/luuuyi/CBAM.PyTorch
https://github.com/JunrQ/backbones
已经有很多论文证明了在网络结构中引入attention机制可以提升网络模型的特征表达能力。attention不止能告诉网络模型该注意什么,同时也能增强特定区域的表征。本文的CBAM在channel和spatial两个维度上引入了attention机制。之前有一篇论文提出了SENet,在feature map的通道上进行attention生成,然后与原来的feature map相乘。这篇文章指出,该种attention方法只关注了通道层面上哪些层会具有更强的反馈能力,但是在空间维度上并不能体现出attention的意思。CBAM作为本文的亮点,将attention同时运用在channel和spatial两个维度上,CBAM与SE Module一样,可以嵌入了目前大部分主流网络中,在不显著增加计算量和参数量的前提下能提升网络模型的特征提取能力。
CBAM extends the idea of SE-Net, combining GAvP (全局平均池化) along channel dimension as well as spatial dimension for accomplishing selfattention.
随着ResNet,Inception等网络结构的出现,人们边热衷于寻找更加高效,有效的网络结构。这篇论文就是在网络结构上的一种尝试。它依然采用了block的形式,但是在每一个block上进行更加细致的设计来使得网络的结构更加合理有效。(在此有一个启发:好的paper,不是要复杂的网络结构,反倒是证明某一个block有效,这样的工作的意义或许会更大。)
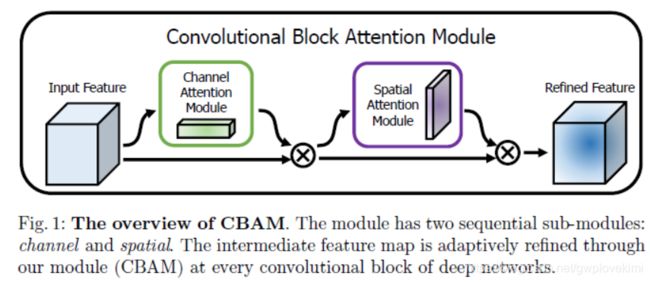
网络的整体结构如下图(这也的一个结果就是channel-wise和HW-wise的attention,《Global Second-order Pooling Convolutional Networks》这篇论文的思路就跟这篇很像了。只是改为用了协方差pooling)
作者采用了类似于人类attention,也就是注意力的机制,对一个特征矩阵进行重新构造。注意力机制其实并不复杂,就是采用一种可以学习的方式来对特征重新赋予权重,权重高的特征就是注意力的注意点。
Attention Mechanism
当输入F作为input feature map时,本文提出的CBAM主要对其进行以下两个运算:

其中等号右边的操作符表示的是element-wise的点乘。Mc表示在channel维度上做attention提取的操作,Ms表示的是在spatial维度上做attention提取的操作。
Channel attention module
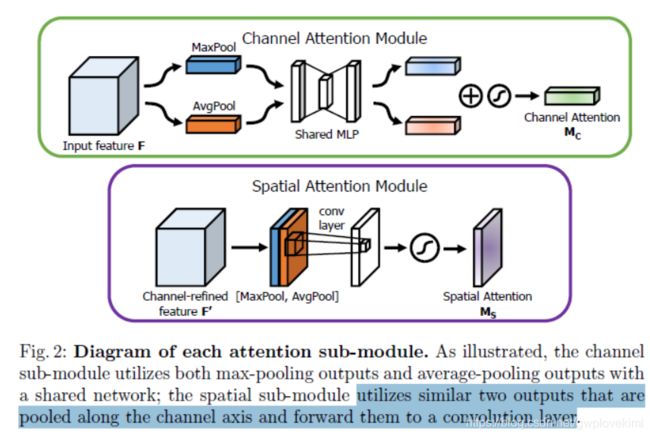
首先是通道注意力,我们知道一张图片经过几个卷积层会得到一个特征矩阵,这个矩阵的通道数就是卷积层核的个数。那么,一个常见的卷积核经常达到1024,2048个,并不是每个通道都对于信息传递非常有用了的。因此,通过对这些通道进行过滤,也就是注意,来得到优化后的特征。
主要思路就是:增大有效通道权重,减少无效通道的权重(SENet)
在通道维度上进行全局的pooling操作,再经过同一个multi-layer perceptron (MLP)得到权重,相加作为最终的注意力向量(权重)。
这里非常像SENet,SENet在很多论文中都被证实对效果有提升,这里的区别是,SENet采用的是平均值的pooling,这篇论文又加入了最大值pooling。作者在论文中,通过对比实验,证实max pooling提高了效果。(这部分的工作与SENet很相似,都是首先将feature map在spatial维度上进行压缩,得到一个一维矢量以后再进行操作。与SENet不同之处在于,对输入feature map进行spatial维度压缩时,作者不单单考虑了average pooling,额外引入max pooling作为补充,通过两个pooling函数以后总共可以得到两个一维矢量。global average pooling对feature map上的每一个像素点都有反馈,而global max pooling在进行梯度反向传播计算只有feature map中响应最大的地方有梯度的反馈,能作为GAP的一个补充)
注意这里的mlp的中间层较小,这个可能有助于信息的整合。
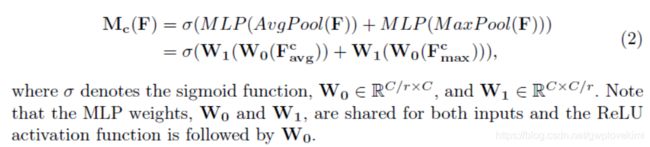
值得注意的是,多层感知机模型中W0和W1之间的feature需要使用ReLU作为激活函数去处理。
Spatial attention module
We generate a spatial attention map by utilizing the inter-spatial relationship of features. Different from the channel attention, the spatial attention focuses on ‘where’ is an informative part, which is complementary to the channel attention.
这部分工作是论文跟SENet区别开来的一个重要贡献,除了在channel上生成了attention模型,作者表示在spatial层面上也需要网络能明白feature map中哪些部分应该有更高的响应。首先,还是使用average pooling和max pooling对输入feature map进行压缩操作,只不过这里的压缩变成了通道层面上的压缩,对输入特征分别在通道维度上做了mean和max操作。最后得到了两个二维的feature,将其按通道维度拼接在一起得到一个通道数为2的feature map,之后使用一个包含单个卷积核的隐藏层对其进行卷积操作,要保证最后得到的feature在spatial维度上与输入的feature map一致。
![]()

下图分别表示了Channel Attention Module和Spatial Attention Module的处理过程。
实验部分就不深入分析了~
参考资料:
https://www.jianshu.com/p/2eb15b577120
https://blog.csdn.net/u013738531/article/details/82731257
https://blog.csdn.net/shi19871987/article/details/82899551
https://www.jianshu.com/p/4fac94eaca91
https://www.cnblogs.com/wangxiaocvpr/p/9649205.html
https://www.cnblogs.com/seniusen/p/10854780.html