体素ICCV2019(一)Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images
《Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images》论文解读
- Abstract
- 1. Related work
-
- 1.1 Single-view 3D Reconstruction
- 1.2 Multi-view 3D Reconstruction
- 2. Method
-
- 2.1 Encoder
- 2.2 Decoder
- 2.3 Context-aware Fusion
- 2.4 Refiner
- 2.5 Loss Function
- 3. Result

原文:Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images
代码:Pytorch
Abstract
3D-R2N2 采用递归神经网络(RNNs)依次融合多个特征图(输入图像中提取而来),但是给定同样一组图像,但顺序不同时,重建结果就很糟糕。此外,由于长期记忆丢失,RNNs不能充分利用输入图像来改进重构结果。
为解决上述弊端,本文提出了一种用于单视图和多视图3D重建的新框架——Pix2Vox:
- 先通过使用 encoder-decoder 来从每个输入图像生成一个粗略的3D体素;
- 再引入上下文感知的融合模块 context-aware fusion module,先自适应地从每个部分(如桌腿)的粗糙3D体素中选择质量更高的3D体素,然后整体重构,从而获得融合的3D体素;
- 最后精化器进一步精化融合的3D体素作为最终的输出。
除此之外,为了在精确度和模型大小之间取得良好的平衡,本文实现了两个版本的框架: Pix2Vox-F 和 Pix2Vox-A 。(前者的参数较少,计算复杂度较低,而后者具有较多的参数,可以构造更精确的3D形状,但计算复杂度较高)
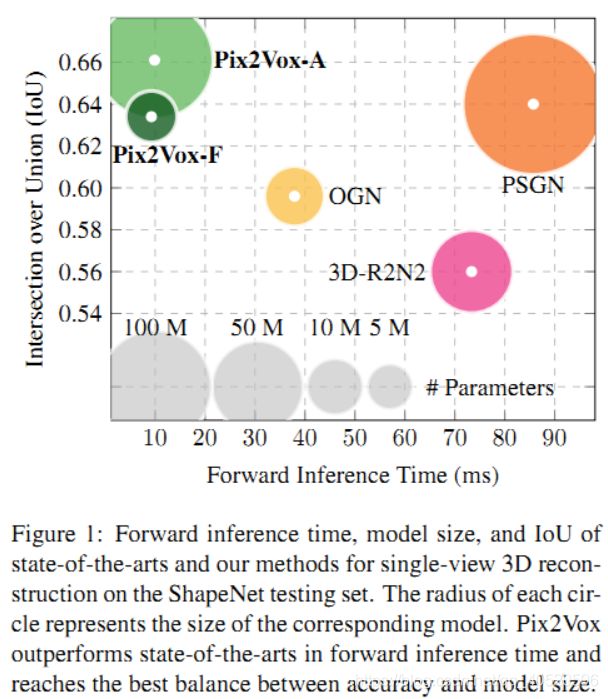
Contributions:
- We present a unified framework for both single-view and multi-view 3D reconstruction, namely Pix2Vox. We equip Pix2Vox with well-designed encoder, decoder, and refiner, which shows a powerful ability to handle 3D reconstruction in both synthetic and real world images.
- We propose a context-aware fusion module to adaptively select high-quality reconstructions for each part from different coarse 3D volumes in parallel to produce a fused reconstruction of the whole object. To the best of our knowledge, it is the first time to exploit context across multiple views for 3D reconstruction.
- Experimental results on the ShapeNet and Pix3D datasets demonstrate that the proposed approaches outperform state-of-the-art methods in terms of both accuracy and efficiency. Additional experiments also show its strong generalization abilities in reconstructing unseen 3D objects.
1. Related work
1.1 Single-view 3D Reconstruction
从理论上讲,恢复单视图图像的3D形状是一个病态的问题。为了解决这个问题,人们做了很多尝试,比如 ShapeFromX,其中X可以代表轮廓、阴影、纹理。然而,这些方法几乎不能应用于真实场景,因为它们都需要很强的假设和丰富的自然图像专业知识。……
1.2 Multi-view 3D Reconstruction
……(这部分有时间还是自己多看看,不是本文重点部分,就先不翻译了,想知道网络具体结构往下看)
2. Method
-
网络总览图:

-
网络详述:

2.1 Encoder
如网络详述图可知,编码器由两部分组成:①使用一个预训练的VGG16网络提取特征。②再使用3个卷积层来将语义信息映射为特征向量。
- 代码详述:
#-----------------------------------------------------------------
#--------------------- Pix2Vox-A -------------------------------
#-----------------------------------------------------------------
class Encoder(torch.nn.Module):
def __init__(self, cfg):
super(Encoder, self).__init__()
self.cfg = cfg
# Layer Definition
vgg16_bn = torchvision.models.vgg16_bn(pretrained=True)
# Choose the first 27 layers of VGG16
self.vgg = torch.nn.Sequential(*list(vgg16_bn.features.children()))[:27]
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(512, 512, kernel_size=3),
torch.nn.BatchNorm2d(512),
torch.nn.ELU(),
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(512, 512, kernel_size=3),
torch.nn.BatchNorm2d(512),
torch.nn.ELU(),
torch.nn.MaxPool2d(kernel_size=3)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(512, 256, kernel_size=1),
torch.nn.BatchNorm2d(256),
torch.nn.ELU()
)
# Don't update params in VGG16
for param in vgg16_bn.parameters():
param.requires_grad = False
def forward(self, rendering_images):
# print(rendering_images.size()) # torch.Size([batch_size, n_views, img_c, img_h, img_w])
rendering_images = rendering_images.permute(1, 0, 2, 3, 4).contiguous()
rendering_images = torch.split(rendering_images, 1, dim=0)
image_features = []
for img in rendering_images:
features = self.vgg(img.squeeze(dim=0))
# print(features.size()) # torch.Size([batch_size, 512, 28, 28])
features = self.layer1(features)
# print(features.size()) # torch.Size([batch_size, 512, 26, 26])
features = self.layer2(features)
# print(features.size()) # torch.Size([batch_size, 512, 24, 24])
features = self.layer3(features)
# print(features.size()) # torch.Size([batch_size, 256, 8, 8])
image_features.append(features)
a = torch.stack(image_features)
image_features = torch.stack(image_features).permute(1, 0, 2, 3, 4).contiguous()
# print(image_features.size()) # torch.Size([batch_size, n_views, 256, 8, 8])
return image_features
- 具体每一层细节如下:
Encoder(
(vgg): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
)
(layer1): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ELU(alpha=1.0)
)
(layer2): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ELU(alpha=1.0)
(3): MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, ceil_mode=False)
)
(layer3): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ELU(alpha=1.0)
)
)
7,772,480 total parameters.
2.2 Decoder
解码器作用则是将 2D特征图 的信息转化为 3D体素。最后一层使用sigmoid函数是为了求出每个体素在真实物体内部的概率(相当于二分类,要么0要么1)
- 代码详述:
#-----------------------------------------------------------------
#--------------------- Pix2Vox-A -------------------------------
#-----------------------------------------------------------------
class Decoder(torch.nn.Module):
def __init__(self, cfg):
super(Decoder, self).__init__()
self.cfg = cfg
# Layer Definition
self.layer1 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(2048, 512, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(512),
torch.nn.ReLU()
)
self.layer2 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(512, 128, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(128),
torch.nn.ReLU()
)
self.layer3 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(128, 32, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(32),
torch.nn.ReLU()
)
self.layer4 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(32, 8, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(8),
torch.nn.ReLU()
)
self.layer5 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(8, 1, kernel_size=1, bias=cfg.NETWORK.TCONV_USE_BIAS),
torch.nn.Sigmoid()
)
def forward(self, image_features):
image_features = image_features.permute(1, 0, 2, 3, 4).contiguous()
image_features = torch.split(image_features, 1, dim=0)
gen_volumes = []
raw_features = []
for features in image_features:
# Reshape to 2048*2*2*2: (256, 8, 8) --> (2048, 2, 2, 2)
gen_volume = features.view(-1, 2048, 2, 2, 2)
# print(gen_volume.size()) # torch.Size([batch_size, 2048, 2, 2, 2])
gen_volume = self.layer1(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 512, 4, 4, 4])
gen_volume = self.layer2(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 128, 8, 8, 8])
gen_volume = self.layer3(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 32, 16, 16, 16])
gen_volume = self.layer4(gen_volume)
raw_feature = gen_volume
# print(gen_volume.size()) # torch.Size([batch_size, 8, 32, 32, 32])
gen_volume = self.layer5(gen_volume)
# print(gen_volume.size()) # torch.Size([batch_size, 1, 32, 32, 32])
raw_feature = torch.cat((raw_feature, gen_volume), dim=1)
# print(raw_feature.size()) # torch.Size([batch_size, 9, 32, 32, 32])
gen_volumes.append(torch.squeeze(gen_volume, dim=1))
raw_features.append(raw_feature)
gen_volumes = torch.stack(gen_volumes).permute(1, 0, 2, 3, 4).contiguous()
raw_features = torch.stack(raw_features).permute(1, 0, 2, 3, 4, 5).contiguous()
# print(gen_volumes.size()) # torch.Size([batch_size, n_views, 32, 32, 32])
# print(raw_features.size()) # torch.Size([batch_size, n_views, 9, 32, 32, 32])
return raw_features, gen_volumes
- 具体每一层细节如下:
Decoder(
(layer1): Sequential(
(0): ConvTranspose3d(2048, 512, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): BatchNorm3d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(layer2): Sequential(
(0): ConvTranspose3d(512, 128, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(layer3): Sequential(
(0): ConvTranspose3d(128, 32, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(layer4): Sequential(
(0): ConvTranspose3d(32, 8, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(layer5): Sequential(
(0): ConvTranspose3d(8, 1, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(1): Sigmoid()
)
)
71,583,064 total parameters.
2.3 Context-aware Fusion
由于从不同的视角看到的物体的部分是不同的,因此重建的效果也是各不相同,能看到的部分重建效果要远好于看不到的部分。从不同视角得到的3D Volume中,有的部分效果好,有的部分效果差,且不同的3D Volume中效果好的部分是不一样的。因此,如何将这些好的部分重新来组合则是这章重点,本文使用 感知上下文的融合模块(context-aware fusion module) 将decoder产生的不同的3D 体素里高质量的体素融合到一起,起到“取长补短”的作用,来生成最终的整个物体的3D Volume。

具体实现:
具体地说,假设一共有 n n n 个视角,经过 encoder-decoder 后得到了 n n n 个 coarse3D体素,则我们首先对每个volume计算出一个 context(其中 c r c_{r} cr 表示第r个视角3D体素的context),再用这个 context 计算出对应体素的 score(这个score是体素级别的,即对3D体素中每个位置的体素都有一个分值,其中 m r m_{r} mr 表示第r个视角3D体素的score),然后还需要归一化一次,本文采用 s o f t m a x softmax softmax 来归一化得到最终的 score,具体式子如(式2.3.1),最后再使用 score 对n个视角的体素进行加权求和来得到,如(式2.3.2)。
s r ( i , j , k ) = exp ( m r ( i , j , k ) ) ∑ p = 1 n exp ( m p ( i , j , k ) ) s_{r}^{(i, j, k)}=\frac{\exp \left(m_{r}^{(i, j, k)}\right)}{\sum_{p=1}^{n} \exp \left(m_{p}^{(i, j, k)}\right)} sr(i,j,k)=∑p=1nexp(mp(i,j,k))exp(mr(i,j,k)) (2.3.1)
其中 ( i , j , k ) (i,j,k) (i,j,k) 指的是3D体素空间位置
v f = ∑ r = 1 n s r v r c v^{f}=\sum_{r=1}^{n} s_{r} v_{r}^{c} vf=∑r=1nsrvrc (2.3.2)
- 代码详述:
class Merger(torch.nn.Module):
def __init__(self, cfg):
super(Merger, self).__init__()
self.cfg = cfg
# Layer Definition
self.layer1 = torch.nn.Sequential(
torch.nn.Conv3d(9, 16, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(16),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv3d(16, 8, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(8),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv3d(8, 4, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(4),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer4 = torch.nn.Sequential(
torch.nn.Conv3d(4, 2, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(2),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
self.layer5 = torch.nn.Sequential(
torch.nn.Conv3d(2, 1, kernel_size=3, padding=1),
torch.nn.BatchNorm3d(1),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE)
)
def forward(self, raw_features, coarse_volumes):
n_views_rendering = coarse_volumes.size(1)
raw_features = torch.split(raw_features, 1, dim=1)
volume_weights = []
for i in range(n_views_rendering):
raw_feature = torch.squeeze(raw_features[i], dim=1)
# print(raw_feature.size()) # torch.Size([batch_size, 9, 32, 32, 32])
volume_weight = self.layer1(raw_feature)
# print(volume_weight.size()) # torch.Size([batch_size, 16, 32, 32, 32])
volume_weight = self.layer2(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 8, 32, 32, 32])
volume_weight = self.layer3(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 4, 32, 32, 32])
volume_weight = self.layer4(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 2, 32, 32, 32])
volume_weight = self.layer5(volume_weight)
# print(volume_weight.size()) # torch.Size([batch_size, 1, 32, 32, 32])
volume_weight = torch.squeeze(volume_weight, dim=1)
# print(volume_weight.size()) # torch.Size([batch_size, 32, 32, 32])
volume_weights.append(volume_weight) # 将所有n_views的权值组合成list
volume_weights = torch.stack(volume_weights).permute(1, 0, 2, 3, 4).contiguous()
volume_weights = torch.softmax(volume_weights, dim=1)
# print(volume_weights.size()) # torch.Size([batch_size, n_views, 32, 32, 32])
# print(coarse_volumes.size()) # torch.Size([batch_size, n_views, 32, 32, 32])
coarse_volumes = coarse_volumes * volume_weights
coarse_volumes = torch.sum(coarse_volumes, dim=1)
return torch.clamp(coarse_volumes, min=0, max=1)
- 具体每一层细节如下:
Merger(
(layer1): Sequential(
(0): Conv3d(9, 16, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(layer2): Sequential(
(0): Conv3d(16, 8, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(layer3): Sequential(
(0): Conv3d(8, 4, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(layer4): Sequential(
(0): Conv3d(4, 2, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
(layer5): Sequential(
(0): Conv3d(2, 1, kernel_size=(3, 3, 3), stride=(1, 1, 1), padding=(1, 1, 1))
(1): BatchNorm3d(1, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
)
)
8,571 total parameters.
2.4 Refiner
Refiner可以被视为一个ResNet (residual network),其目标是校正重建后的3D体素中错误的部分。通过使用 U-Net详述 中shortcut connections的思想,融合后的3D体素能够保留局部细节。
- 代码详述:
class Refiner(torch.nn.Module):
def __init__(self, cfg):
super(Refiner, self).__init__()
self.cfg = cfg
# Layer Definition
self.layer1 = torch.nn.Sequential(
torch.nn.Conv3d(1, 32, kernel_size=4, padding=2),
torch.nn.BatchNorm3d(32),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE),
torch.nn.MaxPool3d(kernel_size=2)
)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv3d(32, 64, kernel_size=4, padding=2),
torch.nn.BatchNorm3d(64),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE),
torch.nn.MaxPool3d(kernel_size=2)
)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv3d(64, 128, kernel_size=4, padding=2),
torch.nn.BatchNorm3d(128),
torch.nn.LeakyReLU(cfg.NETWORK.LEAKY_VALUE),
torch.nn.MaxPool3d(kernel_size=2)
)
self.layer4 = torch.nn.Sequential(
torch.nn.Linear(8192, 2048),
torch.nn.ReLU()
)
self.layer5 = torch.nn.Sequential(
torch.nn.Linear(2048, 8192),
torch.nn.ReLU()
)
self.layer6 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(128, 64, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(64),
torch.nn.ReLU()
)
self.layer7 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(64, 32, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.BatchNorm3d(32),
torch.nn.ReLU()
)
self.layer8 = torch.nn.Sequential(
torch.nn.ConvTranspose3d(32, 1, kernel_size=4, stride=2, bias=cfg.NETWORK.TCONV_USE_BIAS, padding=1),
torch.nn.Sigmoid()
)
def forward(self, coarse_volumes):
volumes_32_l = coarse_volumes.view((-1, 1, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX))
# print(volumes_32_l.size()) # torch.Size([batch_size, 1, 32, 32, 32])
volumes_16_l = self.layer1(volumes_32_l)
# print(volumes_16_l.size()) # torch.Size([batch_size, 32, 16, 16, 16])
volumes_8_l = self.layer2(volumes_16_l)
# print(volumes_8_l.size()) # torch.Size([batch_size, 64, 8, 8, 8])
volumes_4_l = self.layer3(volumes_8_l)
# print(volumes_4_l.size()) # torch.Size([batch_size, 128, 4, 4, 4])
flatten_features = self.layer4(volumes_4_l.view(-1, 8192))
# print(flatten_features.size()) # torch.Size([batch_size, 2048])
flatten_features = self.layer5(flatten_features)
# print(flatten_features.size()) # torch.Size([batch_size, 8192])
volumes_4_r = volumes_4_l + flatten_features.view(-1, 128, 4, 4, 4)
# print(volumes_4_r.size()) # torch.Size([batch_size, 128, 4, 4, 4])
volumes_8_r = volumes_8_l + self.layer6(volumes_4_r)
# print(volumes_8_r.size()) # torch.Size([batch_size, 64, 8, 8, 8])
volumes_16_r = volumes_16_l + self.layer7(volumes_8_r)
# print(volumes_16_r.size()) # torch.Size([batch_size, 32, 16, 16, 16])
volumes_32_r = (volumes_32_l + self.layer8(volumes_16_r)) * 0.5
# print(volumes_32_r.size()) # torch.Size([batch_size, 1, 32, 32, 32])
return volumes_32_r.view((-1, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX, self.cfg.CONST.N_VOX))
- 具体每一层细节如下:
Refiner(
(layer1): Sequential(
(0): Conv3d(1, 32, kernel_size=(4, 4, 4), stride=(1, 1, 1), padding=(2, 2, 2))
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
(3): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv3d(32, 64, kernel_size=(4, 4, 4), stride=(1, 1, 1), padding=(2, 2, 2))
(1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
(3): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer3): Sequential(
(0): Conv3d(64, 128, kernel_size=(4, 4, 4), stride=(1, 1, 1), padding=(2, 2, 2))
(1): BatchNorm3d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
(3): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer4): Sequential(
(0): Linear(in_features=8192, out_features=2048, bias=True)
(1): ReLU()
)
(layer5): Sequential(
(0): Linear(in_features=2048, out_features=8192, bias=True)
(1): ReLU()
)
(layer6): Sequential(
(0): ConvTranspose3d(128, 64, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): BatchNorm3d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(layer7): Sequential(
(0): ConvTranspose3d(64, 32, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): BatchNorm3d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(layer8): Sequential(
(0): ConvTranspose3d(32, 1, kernel_size=(4, 4, 4), stride=(2, 2, 2), padding=(1, 1, 1), bias=False)
(1): Sigmoid()
)
)
34,880,352 total parameters.
2.5 Loss Function
- 损失函数定义为体素级的二元交叉熵损失(voxel-wise binary cross entropies):

- 使用 IoU 作为评价指标,其公式为:
I o U = ∑ i , j , k I ( p ( i , j , k ) > t ) I ( g t ( i , j , k ) ) ∑ i , j , k I [ I ( p ( i , j , k ) > t ) + I ( g t ( i , j , k ) ) ] \mathrm{IoU}=\frac{\sum_{i, j, k} \mathrm{I}\left(p_{(i, j, k)}>t\right) \mathrm{I}\left(g t_{(i, j, k)}\right)}{\sum_{i, j, k} \mathrm{I}\left[\mathrm{I}\left(p_{(i, j, k)}>t\right)+\mathrm{I}\left(g t_{(i, j, k)}\right)\right]} IoU=∑i,j,kI[I(p(i,j,k)>t)+I(gt(i,j,k))]∑i,j,kI(p(i,j,k)>t)I(gt(i,j,k))
3. Result
- Single-view:

- Multi-view:
