python内点法_最优化问题(三) 之 外点法(罚函数法)
1. 基本概念
罚函数法又称乘子法,是将约束优化问题转换为无约束最优化问题的方法之一。其基本思想就是通过在原始的目标函数中添加一个障碍函数(也可以理解成惩罚函数)来代替约束条件中的不等式约束。如果当前解不满足约束条件,就在目标项上加上一个正向的惩罚(这里考虑的都是最小化问题),强迫当前解往可行域的方向走。至于正向惩罚的力度,取决于所用的映射函数,即惩罚函数。
2. 数学定义
考虑约束优化问题:

1) 对于等式约束问题,

可采用前面提到的拉格朗日乘子法。这里我们做一些简化,对每个约束项采用相同的权重,定义如下辅助函数:

其中,δ
\deltaδ为足够大的正数。注意,这里的约束项都加了平方。前面我们提过了,不满足约束要加上一个正向的惩罚。为了保证正向这个条件,同时方便后期求导,就给约束项加上了平方。
从而,问题(1)被转化为无约束问题:
min
F
1
(
x
,
δ
)
\min F_1(x, \delta)minF1(x,δ) (3)
显然,(3)取最优解时,h
j
(
x
)
h_j (x)hj(x)趋近于0。因为如果不这样的话,δ
∑
h
j
2
(
x
)
\delta \sum h_j ^2 (x)δ∑hj2(x)将是非常大的正数,那一定存在更小的值。由此可见,求解问题(3)就能得到问题(1)的近似解。
2)对于不等式约束问题,
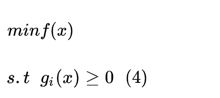
思路与上面基本思想一致,也是引入辅助函数:
F
(
x
,
δ
)
=
f
(
x
)
+
∑
i
=
1
m
I
(
g
i
(
x
)
)
F(x, \delta)=f(x)+\sum_{i=1} ^m I(g_i(x))F(x,δ)=f(x)+∑i=1mI(gi(x)) (5)
其中,I
(
u
)
I(u)I(u)即为惩罚函数(等式约束时可以理解惩罚函数为平方函数,即I
(
u
)
=
u
2
I(u)=u^2I(u)=u2),其须符合如下特性:
在可行域内,惩罚函数值等于一个趋近于0的值
不在可行域内,惩罚函数值等于一个很大的正数
对于不等式约束,引入惩罚函数的意义在于可以将约束条件直接写入到目标函数里面,这样我们直接求新的函数的极小值就可以了,而不必借助于未知乘子。这种方法统称为罚函数法。

3. 罚函数法
可分为两类:内点法和外点法。主要区别就在于惩罚函数的定义。

3.1 内点法
内点法比较完美主义,思想十分直观。满足约束就惩罚为0,不满足就正无穷大,看你老不老实。其设定的惩罚函数需要满足如下要求,
I
(
u
)
=
{
∞
u
≤
0
0
u
>
0
I(u) = {\infinu≤00u>0I(u)={∞0u≤0u>0
我们从它的函数图像(下图的红线)也可以看出,就好像是一堵墙一样的函数,在没有违反约束时,函数值为0,当违反约束时,函数值为正无穷。即在可行域边界时,惩罚力度会发生突变。由此也带来了一个问题,那就是惩罚函数在某些点上是不可导的,因此在求函数极小值的时候我们没法通过普通的微分法来确定函数的极小值。

为了规避这个问题,我们可以用一个光滑的函数来近似这个这个完美的函数。比如上图中的几条蓝色曲线表示的函数来近似这个函数。这样一个近似的函数的表达式如下:
I
(
u
)
=
−
1
t
l
o
g
(
−
u
)
I(u) = - \dfrac{1}{t} log(-u)I(u)=−t1log(−u)
其中 ,t是用于调整近似程度的参数。从图中可以看出,t越大近似效果越好。
那要怎样理解这种方法呢?
相当于在可行域的边界筑起一道很高的“围墙”,当迭代点靠近边界时,目标函数徒然增大,以示惩罚,阻止迭代点穿越边界,这样就可以将最优解“挡”在可行域之内了。
也正因为这一点,使用该方法必须保证初始值在可行域内,这一点也极大的限制了该方法的使用。
3.2 外点法
相比内点法,外点法要成熟的多。既然前面太极端了,那就折中一下:满足约束的时候惩罚为0没错,不满足的时候,惩罚跟当前的偏离程度呈正相关,毕竟狗急了还跳墙呢,咱也不能逼得太狠了是吧!其设定的惩罚函数需要满足如下要求,
I
(
u
)
=
max
{
0
,
−
u
}
=
{
u
u
≤
0
0
u
>
0
I(u) = \max\{0, -u\}={uu≤00u>0I(u)=max{0,−u}={u0u≤0u>0
这个函数大家应该都很熟悉了,深度学习里常用的ReLU函数关于y轴对称一下就是这个了。这里的惩罚力度是固定的,为了方便调节针对性的调整惩罚力度,同时方便求导,调整一下,
I
(
u
)
=
δ
(
max
{
0
,
−
u
}
)
2
I(u) = \delta (\max\{0, -u\})^2I(u)=δ(max{0,−u})2
其中,δ
\deltaδ为足够大的正数,为惩罚因子。内点法是不需要惩罚因子的,因为内点法的惩罚为无穷大,乘以一个正数也还是无穷大。可以看到,外点法的惩罚力度取决于惩罚因子δ
\deltaδ的大小。
相比于内点法,外点法可以从非可行解出发,逐步移动到可行域内,这就意味着使用外点法不需要提供初始可行解。这一点在实际问题求解中十分关键,毕竟对于复杂问题,找到一组可行解还是有一定难度的。但是,外点法多了一个超参:惩罚因子,如何设定合适的惩罚因子也会极大的影响最终的结果。
原文链接:https://blog.csdn.net/SkullSky/article/details/107621121