详解协同感知数据集OPV2V: An Open Benchmark Dataset and Fusion Pipeline for Perception with V2V Communication
在《详解自动驾驶仿真框架OpenCDA: An Open Cooperative Driving Automation Framework Integrated with Co-Simulation》 一文中介绍了自动驾驶仿真框架 OpenCDA。本文将介绍论文作者另一篇最新工作 OPV2V,论文收录于 ICRA2022。
OPV2V 数据集主要 feature 有:
- 提出了首个
多车协同感知大型数据集,在相同的时间戳下包含着多辆自动驾驶汽车的3D点云与相机RGB图像; - 囊括了
73个不同的场景,6种道路类型,9座不同的城市; - 数据共含有
12K LiDAR frames,48K RGB camera images,230K 3D标注bounding box; - 提供了一个包含
16个模型的综合benchmark。
作者还开源了首款协同感知代码框架 OpenCOOD,主要feature有:
- 提供了一套简单易用的API方便用户读取
OPV2V的数据,并转化成相应的格式供pytorch模型直接使用; - 提供了多个
SOTA 3D LiDAR detection backbone, 包括PointPillar, VoxelNet, Pixor, SECOND; - 支持多种常见的多智能体感知融合方式,包括
前融合,中间融合与后融合; - 提供多种协同感知
SOTA模型,并且持续更新; - 提供实用的
log replay tool来回放OPV2V数据,并支持用户在不改变原数据事件的基础上增加新的传感器、定义新的任务。
论文链接:https://arxiv.org/pdf/2109.07644v3.pdf
项目链接:https://mobility-lab.seas.ucla.edu/opv2v/
0. Abstract
简单介绍下论文摘要:
- 在自动驾驶技术中,利用
车与车通信来提高感知性能已经引起了相当大的关注,然而,由于缺乏合适的数据集用于基准算法,使得协同感知技术的开发和评估变得困难。 - 为此,作者提出了
第一个大规模用于车与车感知的模拟数据集。它包含70多个场景、11464帧和232913个带注释的3D车辆 bounding box,从9个城市小镇中收集。 - 然后作者构建了一个全面的评估基准,总共有
16个模型来评估几种信息融合策略 (即早期、后期和中期融合) 和最先进的LiDAR检测算法。此外,作者还提出了一种新的注意力中间融合策略来融合来自多个网联车辆的信息。实验表明,所提出的融合策略可以很容易地与现有的3D LiDAR检测器集成,即使在很大压缩比的情况下也能获得优异的性能。
1. Introduction & Related Work
导论中作者介绍了研究背景,尽管在感知领域3D物体检测取得了很大的突破,但是仍然存在着一些挑战:如当物体被严重遮挡或物体尺寸很小时,检测性能会大幅下降。为了解决这一问题,研究人员开始研究协同感知,利用 V2V 技术,网联汽车(CAVs)可以共享彼此的感知信息,共享信息可以是原始数据、中间特征、单一网联汽车输出以及元数据。然而目前最大的障碍是缺乏大规模的数据集,因此作者使用OpenCDA 和 CARLA 仿真器收集了73个不同场景的数据集;为了弥补仿真和真实世界交通流的差距,作者根据真实的道路拓扑和交通流情况建立了数字城市:Culver City。
研究现状中作者首先介绍了 V2V 感知 常见的融合方式:
- 前融合:在通信范围内,网联汽车共享原始数据,自车根据聚合后的数据进行预测。这种方式保留了完整的传感器数据但是需要大的带宽,因此很难满足实时性要求。
- 后融合: 只传输检测结果,自车根据接收到的检测结果进行融合,这种方式需要很低的带宽,但是严重依赖于每一个车辆的检测性能。
- 中间融合:为了同时满足检测准确率和带宽要求,只传输中间特征,根据聚合的特征来推理周围物体,如
V2VNet、F-Cooper。
2. Dataset
A. Data Collection
作者使用 CARLA 和 OpenCDA 来生成数据。数据主要来自于 CARLA 提供的8个默认小镇,在每一帧中平均有2.89辆网联汽车(最少2辆,最多7辆);每一辆 CAV 配备有4个摄像头(可覆盖360°视野)和64线激光雷达以及 GPS/IMU 传感器,数据流频率为20Hz,记录频率为10Hz。为了更好地模仿真实世界以及评估域自适应能力,作者还使用配有32线激光雷达的车辆(含2个摄像头)在 Culver City 高峰期收集传感器数据。然后使用 RoadRunner 去建立道路拓扑,选择一致的建筑物、模拟真实交通流去建立数字城市(如下图所示)。

B. Data Analysis
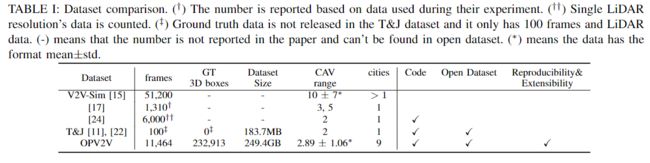
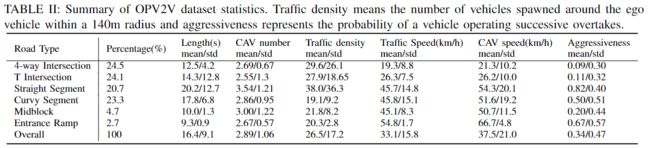
表1和2是数据集统计情况,可以看到其帧数、注释数量、数据大小、CAV数量、城市数量与其它数据比是很丰富的。数据集包含6种道路类型,平均时长为16.4秒,平均联网车辆为2.89辆,平均交通密度为26.5辆,平均交通速度为33.1km/h,CAV 平均速度为37.5km/h。
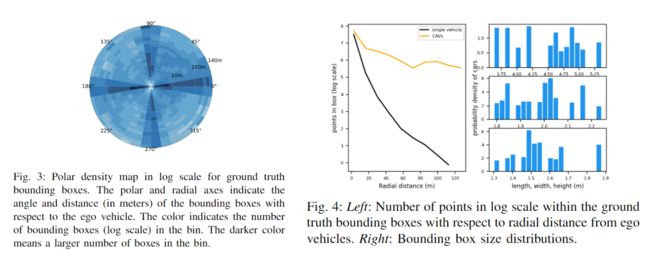
下面是 3D box 注释情况的统计,从图3可以看到,数据集当中有相当一部分比例的物体在100m视野范围之外,这与 KITTI、Waymo 数据集恰恰相反,从图4可以看到,使用 V2V 技术可以增大感知距离,在有遮挡时 CAVs 能够提供互补信息。
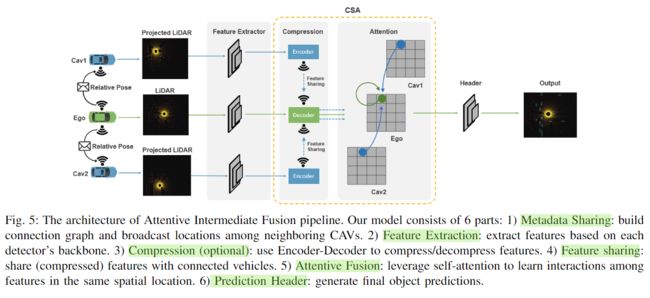
3. Attentive Intermediate Fusion Pipeline
本文提出的注意力中间融合框架如下图所示,包含6个模块:元数据共享、特征提取、压缩、特征共享、注意力融合、预测。
- 首先是
CAVs之间的相对位置和外参广播,建立一个空间图,在通信范围内,每一个节点是一辆CAV。然后选择一辆CAV为自车,所有相邻的CAVs会将其点云投影到自车坐标下并提取特征,特征提取器可以是现有的任意3D物体检测器主干网。 - 由于硬件限制,需要对传输数据进行压缩,这里作者使用一个编码器-解码器架构来压缩共享信息。编码器由一系列2D 卷积和max pooling组成、然后特征图广播给自车,解码器包括一些逆卷积层,还原被压缩信息。
- 注意力融合:作者为特征图中的每个特征向量构造一个局部图,为来自不同网联车辆的相同空间位置的特征向量建立
edge。融合后的特征传输至预测头,生成bounding box和置信度。
4. Experiments
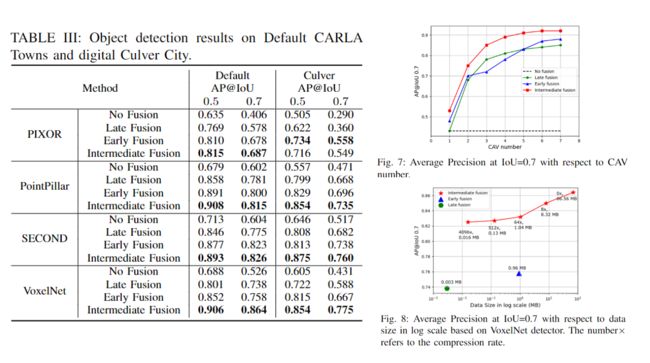
作者选择了4个3D物体检测器(SECOND、VoxelNet、PIXOR、PointPillar),然后与三种融合策略集成,同时作者还研究了不融合的车辆检测性能,加在一起总共有16个模型。
从表3可以看到,任意一种融合方式都比不融合的检测性能提高了至少10个百分点;进一步可以看到,前融合准确率都要高于后融合,在大多数情况下,中间融合都取得了最高的准确率,证明本文提出的自注意力方式捕获了 CAV 感知信息的相互关系。
图7和8分析了 CAV数量和不同压缩比率对协同感知性能影响,可以看到中间融合都取得了最好的性能。
最后是一个可视化例子,协同感知能够检测到更密集的车辆(即使被遮挡)。
