【文本分类】文本分类案例
在NLP中,文本分类是一项非常常见的任务,他的目的是将一个文本归结为特定的某个标签。实践过程中可以用各种数据集作为研究的对象,比如哔哩哔哩视频评论、IMDB电影评论、微博评论的个作为数据集,搭建模型来预测这些评论中包含的情感极性。
本次以互联网新闻作为数据集,搭建模型来精准区分文本的情感极性,情感分为正、中、负三类,分别以0、1、2来表示。
以下是文本分类流程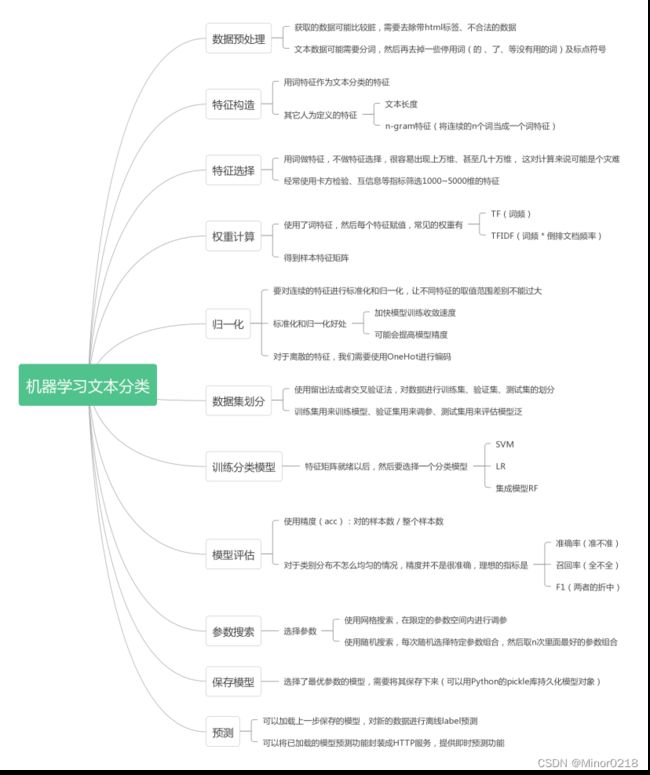
首先查看原始数据,可以看到一共有7340条新闻数据,后面的标签代表了情感极性
import pandas as pd
import jieba
raw_df = pd.read_csv('data/sentiment_analysis_data.csv') # 加载原始数据
print(raw_df)
1. 数据预处理
把文本数据去除标点符号,以空格进行分词,并使用jieba去除停用词(对文本分类意义不大的词),将处理好的文本数据以词和标签的形式展示出来
stop_words = set(open('data/stop_words.txt', encoding='utf-8').read().strip().split('\n'))
# 分词,生成新的dataframe
data = [] # 存储分词后的数据和label
for title, content, label in raw_df.values:
words = [
# 过滤停用词
word for word in jieba.cut(str(title) + ' ' + str(content)) if word.strip() and word.strip() not in stop_words
]
data.append([' '.join(words), label])
df = pd.DataFrame(data, columns=['cut', 'label'])
print(df)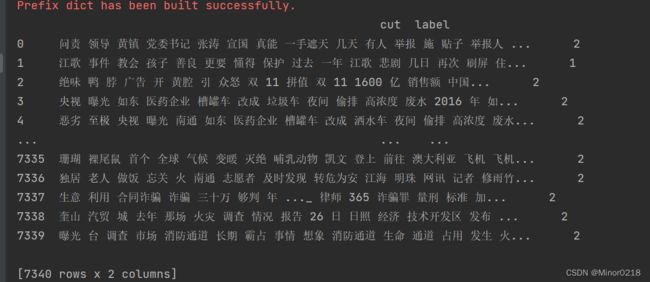
2.特征构造和特征选择
除了词特征,还增加了bigram特征,也就是将连续的n个词作为一个词。这样一来,特征词可能会达到上万维,会造成资源浪费。因此,要进行降维处理,选择最重要的特征
# 使用CountVectorizer生成 文档词频矩阵
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(ngram_range=(1, 2)) # 特征除了词特征外,增加了bigram特征
X = vectorizer.fit_transform(df['cut']) # 获取文档词的词频矩阵
print(type(X)) # 打印类型,稀疏矩阵存储
X.shape # 超多的特征词![]()
查看最后十个特征词
# 打印最后10个特征词
print(vectorizer.get_feature_names()[-10:])![]()
使用卡方检验进行特征选择,用selector.get_support()来选择最重要的50个特征词转成array对象并打印出来
# 使用卡方检验进行特征选择
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectKBest
#selector = SelectKBest(chi2, k=5000) # 选择5000个特征词
selector = SelectKBest(chi2, k=50)
new_X = selector.fit_transform(X, df['label'])
# 打印最重要的50个特征词
import numpy as np
np.array(vectorizer.get_feature_names())[selector.get_support()]
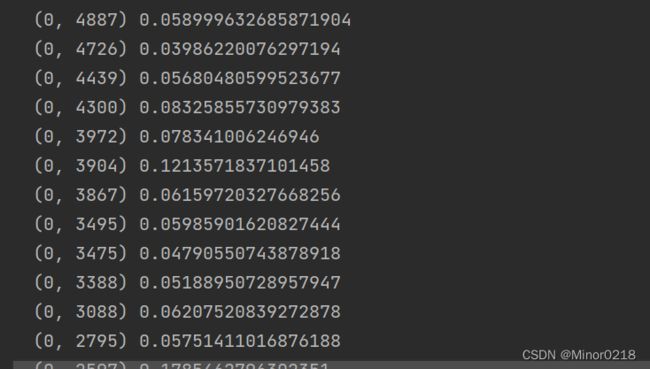
3.权重计算
权重计算就是为各个特征赋值,出了各个词特征的重要性。常见的权重有tf(词频),tfidf,这里使用的是tfidf,也就是词频乘上倒排文档频率
# 使用TfidfTransformer对词频矩阵进行tfidf计算
from sklearn.feature_extraction.text import TfidfTransformer
weight_X = TfidfTransformer().fit_transform(new_X)
print(weight_X)
4.归一化
通常我们需要对连续的特征进行归一化,归一化是让预处理的数据被限定在一定的范围内,从而消除奇异样本数据导致的不良影响。数据归一化处理后,可以加快梯度下降求最优解的速度,且有可能提高精度。上一步的tfidf已经做了归一化,如果没有自己加额外的特征,这一步可以忽略
5. 数据集划分
使用train_test_split函数进行划分,test_size=0.3表示把训练集和测试集按照7:3进行划分,打印维度查看
# 使用留出法划分训练集和测试集
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(weight_X, df['label'], test_size=0.3) # 训练集测试集7 3开
print('train data: ', train_X.shape, train_y.shape) # 打印训练集shape
print('test data: ', test_X.shape, test_y.shape) # 打印测试集shape

6.训练分类模型,这里使用逻辑回归模型
从sklearn.linear_model调用LogisticRegression,实例化 LogisticRegression()这个类,并使用fit(train_X, train_y) 传入训练集的x和y,训练模型
# 使用逻辑回归模型
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression().fit(train_X, train_y) # 创建一个lr模型,使用训练集训练7.评估模型
测试训练集和测试集准确率,发现训练集准确率达到百分之83,测试集准确率达到百分之73,准确率较低,可能是由于某些参数没有达到最优
clf.score(test_X, test_y) # 评估测试集acc![]()
clf.score(train_X, train_y) # 评估训练集acc,训练集上都没很好,可能是参数没设置好,需要调参![]()
8.参数搜索
手动声明c的值为10(正则化系数),把max_iter这个参数设置为1000,训练新的模型。
# 这里演示手动调参
clf = LogisticRegression(C=10, max_iter=1000).fit(train_X, train_y) # 声明某些参数
print('train acc: ', clf.score(train_X, train_y)) # 评估训练集acc
print('test acc: ', clf.score(test_X, test_y)) # 评估训练集acc可以看到训练集和测试集的准确率都提高了

9.保存模型
# 使用pickle保存模型
import pickle
pickle.dump(clf, open('/tmp/lr.model', 'wb'))10.预测
将训练好的模型保存下来,调用predict方法,传入权重矩阵的x,可以预测出y,也就是情感极性类别
# 加载模型并预测
clf = pickle.load(open('/tmp/lr.model', 'rb'))
clf.predict(test_X)运行代码发现报错,这是因为保存模型的路径不对,我们需要预先建立文件夹
把
pickle.dump(clf, open('/tmp/lr.model', 'wb'))改为自己实际预先建立的文件夹(r'D:\Desktop\play-nlp-master\tmp)
pickle.dump(clf, open(r'D:\Desktop\play-nlp-master\tmp\lr.model', 'wb'))

可以得到预测结果
![]()
上述所需要用到的数据放在链接:https://pan.baidu.com/s/1ICkMbPvvf0CvoCBp7MEjIA?p
提取码:l4s2