【Keras】卷积神经网络数据回归预测实战
写这个主要是记录自己实习期间的工作。
参考的是本篇文章【keras】一维卷积神经网络做回归
被分配到完成一个工艺流程中各工艺参数对产品的一个功效的回归预测。
这边先给出一部分数据,红框框出来的是我们想预测的一个label。
而其他的都是用于网络输入的特征值。

首先是数据集的导入,训练集和测试集的划分
df = pd.read_csv(r"Table_5_6_Output_Input_NoNAN.csv")
X = np.hstack((df.values[:, 1:6],df.values[:, 7:])).astype(float)
# 增加一维轴
Y = df.values[:, 6]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
接下来是定义网络模型
采用的是8层的一维卷积+最大池化+Dropout层,这样的好处是可以丢弃影响较小的特征,保留有效的特征,防止过拟合。
loss函数采用的是均方差公式
# 定义一个神经网络
model = Sequential()
model.add(Conv1D(16, 3, input_shape=(84, 1), activation='relu'))
model.add(Conv1D(16, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Dropout(rate=0.2))
model.add(Conv1D(64, 3, activation='relu', ))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Dropout(rate=0.2))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Dropout(rate=0.2))
model.add(Conv1D(64, 3, activation='relu', padding='same'))
model.add(Conv1D(64, 3, activation='relu', padding='same'))
model.add(MaxPooling1D(3, padding="same"))
model.add(Dropout(rate=0.2))
model.add(Flatten())
model.add(Dense(1, activation='linear'))
plot_model(model, to_file='model_linear.png', show_shapes=True)
print(model.summary())
sgd = optimizers.SGD(lr=0.01, decay=1e-4, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='mean_squared_error', metrics=[coeff_determination])
接下来是训练模型
history = model.fit(X_train, Y_train, validation_data=(X_test, scaler_test.fit_transform(Y_test.reshape(-1,1))), epochs = 100, batch_size = 16)
可视化的过程
# 显示训练集和验证集的acc和loss曲线
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('train_valid_loss.png')
plt.show()
# 计算误差
result = np.mean(abs(predicted - Y_test))
print("The mean error of linear regression:")
print(result)
loss曲线,可以看得出来是收敛的。

最后预测值是不变的,我到这里也很懵逼。

博主首先分析有以下几个因素:
- 特征值没有归一化,存在标签类型的特征值
- 优化器,学习率的调整
- epoch、batch、激活函数…
数据预处理
首先对数据分别进行归一化和标准化进行训练。
归一化对预测结果并不起作用,这里直接省略。
快进到标准化,首先实例化标准化对象。
这里对训练集和测试集分别实例化一个对象,是博客上的大神这么做的,具体为啥这么做我这里也不了解。
# 实例化数据标准化对象
scaler_train = StandardScaler()
scaler_test = StandardScaler()
# 划分训练集,测试集
# 数据标准化
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
X_train = np.expand_dims(scaler_train.fit_transform(X_train), axis= 2)
Y_train = scaler_train.fit_transform(Y_train.reshape(-1, 1))
X_test = np.expand_dims(scaler_test.fit_transform(X_test), axis= 2)
这里模型的形状一定要和网络输入层的对的上,博主在这个地方大概花了一天才调通。
然后这里提一点,因为我们的训练数据是标准化符合高斯分布的,所以我们用训练的模型去预测数据时,要反标准化数据,否则预测值就不是原来想要数据了。
改动的几条代码在这里
history = model.fit(X_train, Y_train, validation_data=(X_test, scaler_test.fit_transform(Y_test.reshape(-1,1))), epochs = 100, batch_size = 64)
```
```python
scores = model.evaluate(X_test, scaler_test.fit_transform(Y_test.reshape(-1, 1)), verbose=0)
predicted = scaler_test.inverse_transform(model.predict(X_test))
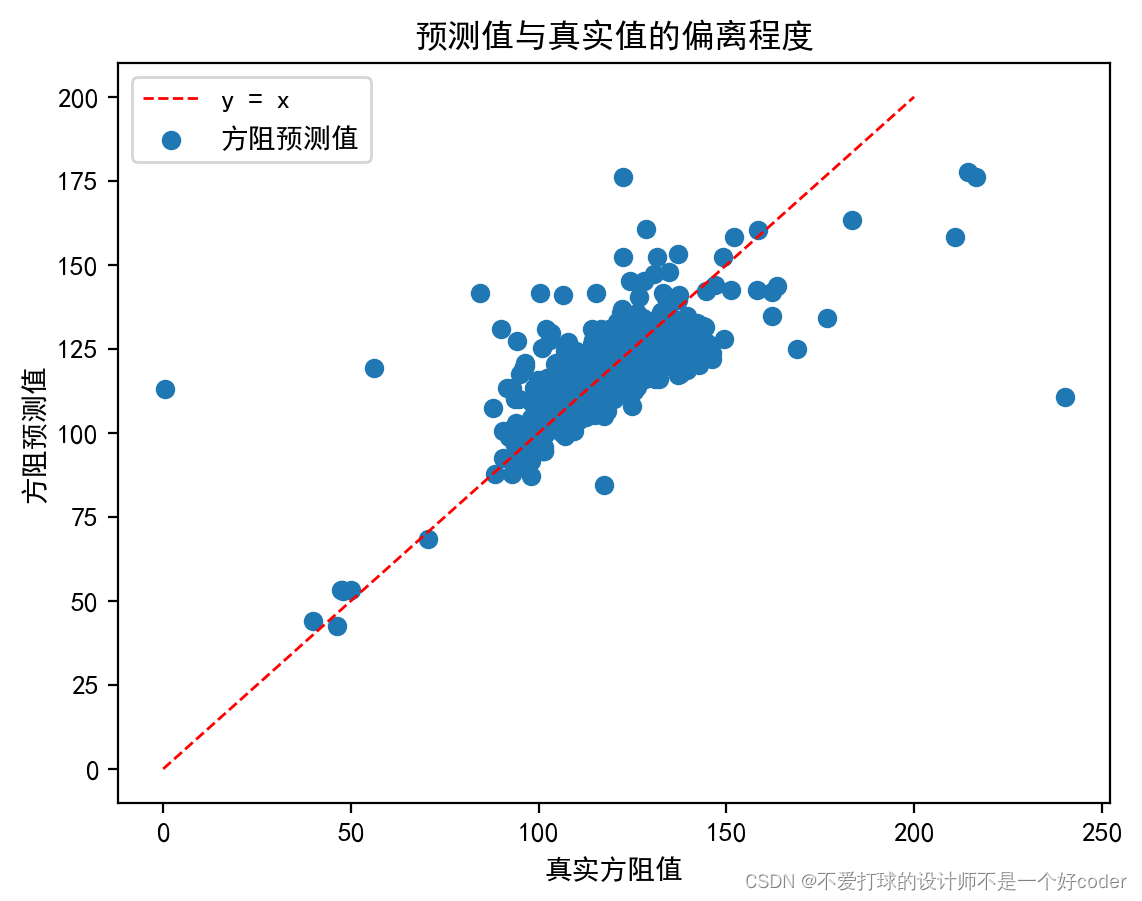
最后的一个预测结果还算不错

这里loss曲线图 在1000代之后验证集的loss开始不下降,所以我们取epoch=1000时为最好的模型、权重。

下面贴个完整代码:
# -*- coding: utf8 -*-
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.utils import np_utils, plot_model
from sklearn.model_selection import cross_val_score, train_test_split
from keras.layers import Dense, Dropout, Flatten, Conv1D, MaxPooling1D
from keras.models import model_from_json
import matplotlib.pyplot as plt
from keras import backend as K
from keras import optimizers
from keras import regularizers
from keras.callbacks import LearningRateScheduler
from sklearn.preprocessing import MinMaxScaler, StandardScaler, LabelEncoder
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
# 回调函数,我们让被观测值为验证集loss,当它连续10个epoch没有被优化时,终止训练。
earlystopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience= 10)
# 载入数据
# df = pd.read_csv(r"Table_5_6_Output_Input_NoNAN.csv")
df = pd.read_csv(r"D:\xdcplus\datasets\new_dataset.csv")
X = df.values[:, :-1].astype(float) # 输入的特征
Y = df.values[:, -1] # 方阻均值
scaler_train = StandardScaler()
scaler_test = StandardScaler()
#
# X = np.column_stack((df.values[:, 4], df.values[:, 8:])).astype(float) # 增加一维轴
# Y = df.values[:, 6]
# 划分训练集,测试集
# 数据标准化
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
X_train = np.expand_dims(scaler_train.fit_transform(X_train), axis= 2)
Y_train = scaler_train.fit_transform(Y_train.reshape(-1, 1))
X_test = np.expand_dims(scaler_test.fit_transform(X_test), axis= 2)
# 自定义度量函数
def coeff_determination(y_true, y_pred):
SS_res = K.sum(K.square(y_true - y_pred))
SS_tot = K.sum(K.square(y_true - K.mean(y_true)))
return (1 - SS_res / (SS_tot + K.epsilon()))
myReduce_lr = LearningRateScheduler(myScheduler)
sgd = optimizers.SGD(lr=0.01, decay=1e-4, momentum=0.9, nesterov=True)
# kernel_regularizer=regularizers.l2(0.01)
# 定义一个神经网络
model = Sequential()
model.add(Conv1D(16, 3, input_shape=(81, 1), activation='relu'))
model.add(Conv1D(16, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Dropout(rate=0.2))
model.add(Conv1D(64, 3, activation='relu', ))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Dropout(rate=0.2))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Dropout(rate=0.2))
model.add(Conv1D(64, 3, activation='relu', padding='same'))
model.add(Conv1D(64, 3, activation='relu', padding='same'))
model.add(MaxPooling1D(3, padding="same"))
model.add(Dropout(rate=0.2))
model.add(Flatten())
model.add(Dense(1, activation='linear'))
plot_model(model, to_file='model_linear.png', show_shapes=True)
print(model.summary())
model.compile(optimizer=sgd, loss='mean_squared_error', metrics=[coeff_determination])
# 训练模型
history = model.fit(X_train, Y_train, validation_data=(X_test, scaler_test.fit_transform(Y_test.reshape(-1,1))), epochs = 1000, batch_size = 64, callbacks = [earlystopping])
# 将其模型转换为json
model_json = model.to_json()
with open(r"model.json", 'w')as json_file:
json_file.write(model_json) # 权重不在json中,只保存网络结构
model.save_weights('model.h5')
#
# # 加载模型用做预测
# json_file = open(r"C:\Users\Desktop\model.json", "r")
# loaded_model_json = json_file.read()
# json_file.close()
# loaded_model = model_from_json(loaded_model_json)
# loaded_model.load_weights("model.h5")
# print("loaded model from disk")
# scores = model.evaluate(X_test,Y_test,verbose=0)
# print('%s: %.2f%%' % (model.metrics_names[1], scores[1]*100))
# 准确率
scores = model.evaluate(X_test, scaler_test.fit_transform(Y_test.reshape(-1, 1)), verbose=0)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('train_valid_loss.png')
plt.show()
# 预测值散点图
predicted = scaler_test.inverse_transform(model.predict(X_test))
plt.scatter(Y_test, predicted)
x = np.linspace(0, 200, 100)
y = x
plt.plot(x, y, color='red', linewidth=1.0, linestyle='--', label='line')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.legend(["y = x", "方阻预测值"])
plt.title("预测值与真实值的偏离程度")
plt.xlabel('真实方阻值')
plt.ylabel('方阻预测值')
plt.savefig('test_result.png', dpi=200, bbox_inches='tight', transparent=False)
plt.show()
# 计算误差
result = np.mean(abs(predicted - Y_test))
print("The mean error of linear regression:")
print(result)