去噪扩散概率模型(Denoising Diffusion Probabilistic Model,DDPM)
去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM)在2020年被提出,向世界展示了扩散模型的强大能力,带动了扩散模型的火热。笔者出于兴趣自学相关知识,结合网络上的参考资料和自己的理解介绍DDPM。需要说明的是,笔者能力很有限,学习过程中遇到了很多知识盲区,只能硬着头皮现学现卖。如果发现文中有错误,欢迎评论指出,大家一起学习,共同进步。
前置知识
① 贝叶斯公式
![]()
![]()
若满足马尔科夫链关系  ,即当前时刻的概率分布仅与上一时刻有关,则有:
,即当前时刻的概率分布仅与上一时刻有关,则有:
![]()
![]()
② 高斯分布的概率密度函数、高斯函数的叠加公式
给定均值为  ,方差为
,方差为  的单一变量高斯分布
的单一变量高斯分布 ![]() ,其概率密度函数为:
,其概率密度函数为:
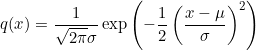
很多时候,为了方便起见,可以将前面的常数系数去掉,写成:
给定两个高斯分布  ,
,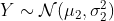 ,则它们叠加后的分布
,则它们叠加后的分布  满足:
满足:

③ KL散度与交叉熵
详细讲解可参照我之前的博客。假设随机变量的真实概率分布为  ,而我们通过建模得到的一个近似分布为
,而我们通过建模得到的一个近似分布为  ,则 与 的KL散度和交叉熵满足下式:
,则 与 的KL散度和交叉熵满足下式:
![]()
对于两个单一变量的高斯分布 ![]() 和
和  而言,它们的KL散度为:
而言,它们的KL散度为:
![]()
④ 参数重整化(重参数技巧)
若要从高斯分布  中采样,可先从标准分布
中采样,可先从标准分布 ![]() 中采样出
中采样出  ,再得到
,再得到 ![]() ,即我们的采样值。这样做的目的是将随机性转移到 上,让采样值对 和
,即我们的采样值。这样做的目的是将随机性转移到 上,让采样值对 和  可导。
可导。
基本介绍
如下图所示,DDPM模型主要分为两个过程:加噪过程(从右往左)和去噪过程(从左往右)。
★ 加噪过程:给定真实图像  ,逐步对它添加高斯噪声,得到
,逐步对它添加高斯噪声,得到  ,显然这是一个马尔科夫链过程,在进行了足够多的
,显然这是一个马尔科夫链过程,在进行了足够多的  次加噪后,图像会被高斯噪声淹没,可以认为是各向独立的高斯噪声的图像。
次加噪后,图像会被高斯噪声淹没,可以认为是各向独立的高斯噪声的图像。
★ 去噪过程:针对噪声图像 ![]() ,让神经网络模型对其逐步去噪,得到
,让神经网络模型对其逐步去噪,得到 ![]() ,最终复原出没有噪声的逼真图像 ,所以加噪过程其实可以看作是在为去噪过程构建标签。
,最终复原出没有噪声的逼真图像 ,所以加噪过程其实可以看作是在为去噪过程构建标签。

前向过程(扩散过程,加噪过程)
给定初始图像 ,向其中逐步添加高斯噪声,加噪过程持续 次,产生一系列带噪图像,达到破坏图像的目的。由  加噪至
加噪至 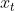 的过程中,所加噪声的方差为
的过程中,所加噪声的方差为  ,又称扩散率,是一个给定的,大于 0 小于 1 的,随扩散步数增加而逐渐增大的值。定义扩散过程如下式:
,又称扩散率,是一个给定的,大于 0 小于 1 的,随扩散步数增加而逐渐增大的值。定义扩散过程如下式:
![]()
根据定义式,加噪过程可以看作在上一步的状态 上乘了一个系数 ![]() ,然后加上了均值为0,方差为
,然后加上了均值为0,方差为  的高斯分布。所以加噪过程是确定的,并不是可学习的过程,将其写成概率分布的形式,则有:
的高斯分布。所以加噪过程是确定的,并不是可学习的过程,将其写成概率分布的形式,则有:
![]()
此外,加噪过程是一个马尔科夫链过程,所以联合概率分布可以写成下式:

定义 ![]() ,即
,即 ![]() ,代入 表达式并迭代推导,可以得到 到 的公式:
,代入 表达式并迭代推导,可以得到 到 的公式:
![]()
![]()
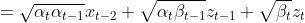
![]()
![]()
上式从第二项到最后一项都是独立的高斯噪声,它们的均值都为0,方差为各自系数的平方。根据高斯分布的叠加公式,它们的和满足均值为0,方差为各项方差之和的高斯分布。又有上式每一项系数的平方和(包括第一项)为1,证明如下,注意始终有 ![]() :
:
![]()

![]()
那么,将 ![]() 记作
记作  ,则正态噪声的方差之和为
,则正态噪声的方差之和为  , 可表示为:
, 可表示为:
![]()
由该式可以看出, 实际上是原始图像 和随机噪声 ![]() 的线性组合,即只要给定初始值,以及每一步的扩散率,就可以得到任意时刻的 ,写成概率分布的形式:
的线性组合,即只要给定初始值,以及每一步的扩散率,就可以得到任意时刻的 ,写成概率分布的形式:
![]()
当加噪步数 足够大时, 趋向于 0,![]() 趋向于 1,所以
趋向于 1,所以 ![]() 趋向于标准高斯分布。
趋向于标准高斯分布。
反向过程(逆扩散过程,去噪过程)
前向过程对原始图像 逐步加噪声变成 ![]() ,反向过程则是从
,反向过程则是从 ![]() 逐步恢复到 。前向过程我们用
逐步恢复到 。前向过程我们用 ![]() 来表示,而反向过程则是求
来表示,而反向过程则是求 ![]() 。如果能实现这种逆转,就可以从一个随机的高斯噪声
。如果能实现这种逆转,就可以从一个随机的高斯噪声  中重建出一个真实的原始样本,即从杂乱无章的噪声图像中得到真实图像,实现图像生成的目的。
中重建出一个真实的原始样本,即从杂乱无章的噪声图像中得到真实图像,实现图像生成的目的。
有文献证明,如果 ![]() 满足高斯分布且 足够小,则
满足高斯分布且 足够小,则 ![]() 也满足高斯分布。虽然我们已知前向过程中每一步所加的噪声都采样自特定的高斯分布,但是采样有无数种可能,所以我们无法简单地预测
也满足高斯分布。虽然我们已知前向过程中每一步所加的噪声都采样自特定的高斯分布,但是采样有无数种可能,所以我们无法简单地预测 ![]() ,这时候深度学习就有用武之地了,可以通过学习一个深度网络(参数为
,这时候深度学习就有用武之地了,可以通过学习一个深度网络(参数为  )来模拟。
)来模拟。
反向过程仍然是一个马尔科夫链过程,网络以当前时刻  和当前时刻的图像 作为输入,构建反向过程条件概率,其中,均值和方差都是含参的,且都以 和 作为输入,有下式:
和当前时刻的图像 作为输入,构建反向过程条件概率,其中,均值和方差都是含参的,且都以 和 作为输入,有下式:


而真实的反向过程,或者称作扩散过程的后验条件概率,可以写成:

其中,![]() 是不可知的,但是如果知道 ,则扩散过程的后验条件概率可以写成:
是不可知的,但是如果知道 ,则扩散过程的后验条件概率可以写成:
又根据前向过程的推导,有下面三个式子满足:
将三个式子代入,并结合前置知识中的高斯函数概率密度函数,展开后合并同类项,有下式:
此式符合前置知识中高斯函数概率密度函数的展开形式,有以下两个式子满足:
对第一个式子,有:
对第二个式子,有:
所以,在给定 的条件下,反向过程真实的概率分布的均值只与 和 ![]() 有关,满足下式:
有关,满足下式:
优化目标
我们的目标是得到尽可能真实的 ,即求模型参数 ,使其最终得到 的概率最大,这显然是一个极大似然估计问题,写出似然函数:
![]()
![]()
由 ![]() 不等式,对任一凸函数
不等式,对任一凸函数  ,始终满足函数值的期望大于等于期望的函数值,对上式两边取对数,得到对数似然函数,满足:
,始终满足函数值的期望大于等于期望的函数值,对上式两边取对数,得到对数似然函数,满足:
再对两边同时取负,得到负对数似然函数,满足:
![- \log p_{\theta }(x_{0}) \leq \mathbb{E}_{ q(x_{1:T}\mid x_{0})}\left [\log \frac{ q(x_{1:T}\mid x_{0})}{ p_{\theta}(x_{0:T})}\right]](http://img.e-com-net.com/image/info8/b07972cbc2974882822f09eba0563eb9.gif)
式子右侧称为变分上界,最大化对数似然函数可以转换为最小化变分上界,结合马尔科夫链的贝叶斯公式将变分上界展开:
因为和的期望等于期望的和,可得:
因为期望目标与部分时间步的概率无关可以直接省去,可得:
中间的求和项根据前置知识中的贝叶斯公式改写,可得:
![]()
对 ![]() 而言,先验分布
而言,先验分布 ![]() 是一个确定的值,而
是一个确定的值,而 ![]() 是一个各向同性的高斯分布,二者都不含参,KL散度近似为 0,最小化变分上界时不用考虑。而对于中间的求和项,当 的取值为 1 时,分子为
是一个各向同性的高斯分布,二者都不含参,KL散度近似为 0,最小化变分上界时不用考虑。而对于中间的求和项,当 的取值为 1 时,分子为 ![]() ,即在已知 的条件下求 的概率分布,肯定是一个确定值,所以对比下来发现其实
,即在已知 的条件下求 的概率分布,肯定是一个确定值,所以对比下来发现其实  可以并入
可以并入 ,由此可将变分上界简化一些。推导到这里,优化目标就被转化为了最小化后验分布与网络参数化的高斯分布之间的KL散度。
,由此可将变分上界简化一些。推导到这里,优化目标就被转化为了最小化后验分布与网络参数化的高斯分布之间的KL散度。
为了简化计算,DDPM对 ![]() 做了进一步简化,采用固定的方差:
做了进一步简化,采用固定的方差:![]() ,这里的
,这里的  是一个无需训练的常量,文中提到,设置为 或
是一个无需训练的常量,文中提到,设置为 或  有相似的效果,这里假定
有相似的效果,这里假定 ![]() ,则KL散度中的两项分别可写作:
,则KL散度中的两项分别可写作:
结合前置知识中高斯分布的KL散度公式,有:
将此式代回之前变分上界的式子,则优化目标 可以写作:
![L_{t-1} = \mathbb{E}_{ q(x_{t}\mid x_{0})}\left [ \frac{1}{2\sigma_{t} ^{2}}\left \| \tilde{\mu }_{t}(x_{t},x_{0}) - \mu _{\theta}(x_{t}, t) \right \| ^{2} \right ]](http://img.e-com-net.com/image/info8/f59f002deefc465caf16cefe59cdae3a.gif)
也就是说,我们希望网络参数化高斯分布的均值 ![]() 与后验分布的均值
与后验分布的均值  一致。但是,此式还可以继续扩展,在反向过程中, 可以写成用 和
一致。但是,此式还可以继续扩展,在反向过程中, 可以写成用 和 ![]() 表示的形式,而在前向过程中, 又可以写成用 和
表示的形式,而在前向过程中, 又可以写成用 和 ![]() 表示的形式,将它们代入上式,则有:
表示的形式,将它们代入上式,则有:
其中,参数化高斯分布的均值 ![]() 可以相应改写成与真实均值 一样的形式:
可以相应改写成与真实均值 一样的形式:
这里的 ![]() 是神经网络的拟合项,即优化目标由原来的拟合均值转换成了拟合噪声。将其代入 的表达式中,则有:
是神经网络的拟合项,即优化目标由原来的拟合均值转换成了拟合噪声。将其代入 的表达式中,则有:
可以将系数项去掉,进一步简化:
虽然背后的推导比较复杂,但是最终得到的优化目标非常简单,就是让网络预测的噪声与真实的噪声一致。
参考
大一统视角理解扩散模型Understanding Diffusion Models: A Unified Perspective 阅读笔记 - 知乎
扩散模型之DDPM - 知乎
动态-哔哩哔哩
什么是 Diffusion Models/扩散模型?_哔哩哔哩_bilibili
Jensen不等式及其应用 - 知乎
单变量高斯分布的KL散度_昕晛的博客-CSDN博客_高斯分布的kl散度
组会分享:生成扩散概率模型简介 Diffusion Models_哔哩哔哩_bilibili
简单基础入门理解Denoising Diffusion Probabilistic Model,DDPM扩散模型_xiongxyowo的博客-CSDN博客
轻松学习扩散模型(diffusion model),被巨怪踩过的脑袋也能懂——原理详解+pytorch代码详解(附全部代码) - 知乎