paper report: 调研self-ensembling相关文章
paper list:
-
Temporal Ensembling for Semi-Supervised Learning
-
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
-
Self-ensembling for visual domain adaptation
Temporal Ensembling
这篇文章针对Semi-Supervised Learning的问题提出了在时间维度进行ensembling的方式。核心算法是在训练过程中将每个样本的预测输出在时间维度上滑动平均。相比于 ∏ − m o d e l \prod-model ∏−model模型优点在于数据只用通过一次网络就可以完成训练。
之前提出的 ∏ − m o d e l \prod-model ∏−model模型
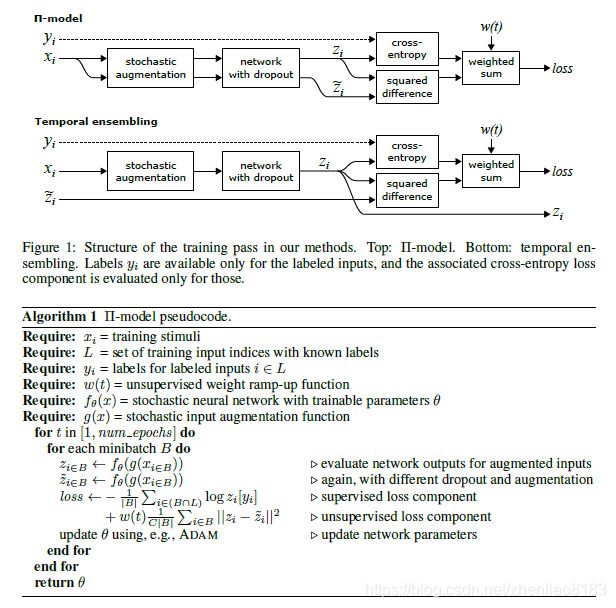
本文的temproal ensembling算法:

Mean Teacher
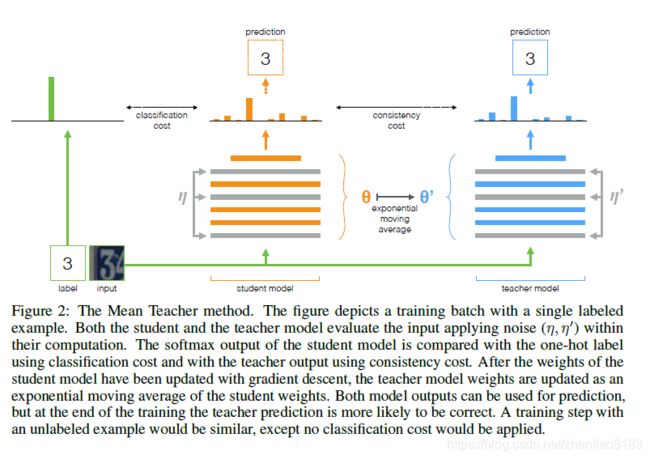
这篇文章是受到了上一篇Temporal Ensembling的启发,但是没有对输出的预测标签进行时间上的滑动平均。Mean Teacher采用两个网络,student网络是直接使用SGD训练的网络,而teacher网络是student网络的滑动平均,两个网络使用不同的dropout,noise和输入图像的增强特征。
Mean Teacher的网络模型如下所示:
Self-ensembling in visual domain adaptation
这篇文章将Mean Teacher的方法用到了unsupervised domain adaptation上,原有的方法是在semi-supervised learning的情景下提出的。
本文的网络结构:
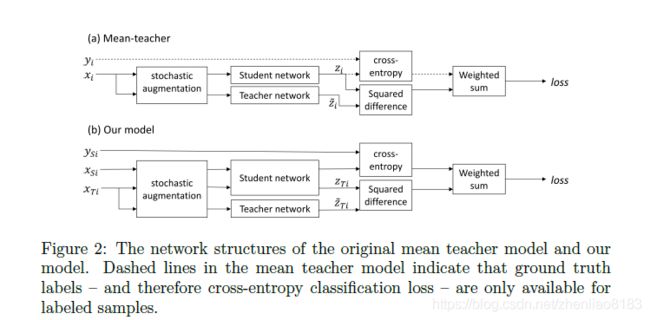
对source domain的数据只计算分类损失,对target domain的数据使用student和teacher两个网络的预测输出值做self-ensembling的损失(MSELoss),但是和Mean Teacher不同的是没有采用Gaussian的ramp-up方式,而是使用一个confidence threshold的方式,如果target数据的预测标签输出小于阈值就不计算它的self-ensembling loss。
由于看到USPS数据集存在class之间数据量差异大导致在训练过程的问题,提出了一个class balance loss,将每个mini-batch的预测标签求平均,和全局真实分布计算binary cross entropy loss加以惩罚,防止其向数据量多的class偏移。
在Mean Teacher和Temporal Ensembling的基础上增加了数据增强的方式,random affine transformations, 直接对像素加Gaussian噪声
总结
这三篇文章层层推进,将self-ensembling的方式在temporal的方向上发展并引入到domain adaptation这个无监督学习的方向中,模型简单而有效。
本人博客主页:https://www.frankzhang.tech/
参考文献
- [1]. S. Laine and T. Aila. Temporal Ensembling for Semi-Supervised Learning. arXiv:1610.02242 [cs], Oct. 2016.
- [2]. A. Tarvainen and H. Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In NIPS, 2017.
- [3]G. French, M. Mackiewicz, and M. Fisher. Self-ensembling for visual domain adaptation. In International Conference on Learning Representations, 2018.