1.背景
最近研究了数据库实时转移的方案,目的是要把数据库中某些表的指定数据实时的转移到别的数据库中。
这与平时了解的数据库备份概念不同,数据库备份是对全库数据进行复制,永许有一定的延时。而本次研究的是对数据过滤后实时的转移,延迟时间要控制到毫秒级。
在调研的过程中了解到Confluent平台可以很好的实现这个功能,于是开始逐步深入探究其使用方法和工作原理。
但在实践的过程中发现国内用此平台的不多,这方面的资料非常之少,都是些只言片语的介绍,并没有一个实践的教程。
各种资料搜索下来,发现唯一的途径只能通过官网去学习,但是官网都是英文文档,对于英语不好的人学习起来更是吃力。
最后本人通过对官网文档的翻译,以及一些源码的阅读,最终成功搭建了一套实时数据转移系统,运行结果也比较稳定,满足了实际需求。
在此我也把这次的学习、实践成果分享出来,供需要的人参考,避免后来人走一些弯路。
2.Confluent初探
Confluent 官网资料很多,本章主要对一些必要的概念或者是和本实验有关的东西进行重点讲解。
2.1 Confluent Platform功能
说起Kafka相信大家很多人都知道,知道是一个高吞吐量的分布式发布订阅消息系统,国内很多公司也在用,但对于Confluent大家可能相对了解的较少。
Confluent是一家创业公司,由当时编写Kafka的几位程序员从Linked In公司离职后创立的,Confluent Platform 就是Confluent公司的主要产品,其平台实现主要依赖的就是Kafka。
以下是截取的两段官方文字介绍:
The Confluent Platform is a streaming platform that enables you to
organize and manage data from many different sources with one
reliable, high performance system.
https://docs.confluent.io/current/getting-started.html
Confluent Platform makes it easy build real-time data pipelines and
streaming applications. By integrating data from multiple sources and
locations into a single, central Event Streaming Platform for your
company.
https://docs.confluent.io/current/platform.html
上面两段话翻译过了就是:
Confluent是用来管理和组织不同数据源的流媒体平台,可以实时地把不同源和位置的数据集成到一个中心的事件流平台。而且还强调了这个平台很可靠、性能很高,总之就是很好用,很强大。
下面的图形象说明了Confluent可以实现的功能。
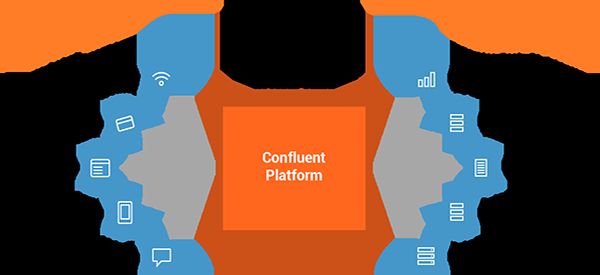
2.2 Confluent Platform组成
Confluent目前提供了社区版和商业版两个版本,社区版永久免费,商业版面向企业收费。
社区版提供了Connectors、REST Proxy、KSQL、Schema-Registry等基础服务。
商业版为企业提供了控制面板、负载均衡,跨中心数据备份、安全防护等高级特性。
2.3 社区版功能介绍
通过对两个版本功能的比对,发现社区版已经能满足我们的要求,因此本文后面都以社区版来进行研究。
下载链接:https://www.confluent.io/download/
解压下载的社区版本包,包含以下文件夹:
各文件目录功能描述如下:

通过查看bin和etc目录发现每个组件都互相独立,都有各自的启动/停止脚本以及相应的配置文件,可以对各项服务进行灵活的配置。
2.4 confluent命令
Confluent提供了多种命令来对confluent平台进行管理监控,命令列表及描述如下:

上面的命令介绍都比较简单,相信大家基本都能看懂,此处也不再一一介绍。
这里主要提一下我们最可能最常用到confluent start
start命令如果不带参数会把相关服务按顺序启动,stop会逆序把各服务停止。
执行start命令:
confluent start
结果如下,[UP]表示该服务启动成功:
Startingzookeeper
zookeeper is[UP]
Startingkafka
kafka is[UP]
Startingschema-registry
schema-registry is[UP]
Startingkafka-rest
kafka-rest is[UP]
Startingconnect
connect is[UP]
Startingksql-server
ksql-server is[UP]
执行stop命令:
confluent stop
结果如下,[DOWN]表示该服务停止成功:
Stoppingksql-server
ksql-server is [DOWN]
Stopping connect
connect is [DOWN]
Stopping kafka-rest
kafka-rest is [DOWN]
Stopping schema-registry
schema-registry is [DOWN]
Stopping kafka
kafka is [DOWN]
Stopping zookeeper
zookeeper is [DOWN]
从上面命令可以看到服务的启动关闭都有一定的顺序性,不能随意颠倒。
3. 服务功能介绍
3.1 Zookeeper
Zookeeper是一个开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop、Hbase、Storm的重要组件。
Zookeeper主要功能包含:维护配置信息、命名、提供分布式同步、组管理等集中式服务 。
Kafka uses ZooKeeper to store persistent cluster metadata and is a critical component of the Confluent Platform deployment.
https://docs.confluent.io/current/zookeeper/deployment.html
Kafka使用ZooKeeper对集群元数据进行持久化存储,是Confluent平台部署的关键组件。
如果ZooKeeper丢失了Kafka数据,集群的副本映射关系以及topic等配置信息都会丢失,最终导致Kafka集群不再正常工作,造成数据丢失的后果。
想要了解更多Zookeeper信息,可以查看官方链接:https://zookeeper.apache.org/
3.2 Kafka
Kafka是一个分布式流处理平台,最初由Linkedin公司开发,是一个基于zookeeper协调并支持分区和多副本的分布式消息系统。
Kafka最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎、web/nginx日志、访问日志、消息服务等等。
Kafka用Java和Scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Apache Kafka® is a distributed streaming platform.
Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
Store streams of records in a fault-tolerant durable way.
Process streams of records as they occur.
http://kafka.apache.org/intro
Kafka工作原理是一种高吞吐量的分布式发布订阅消息系统,消息队列中间件,主要功能是负责消息传输,Confluent就是依赖Kafka来进行消息传输。
3.3 Kafka-rest
The Confluent REST Proxy provides a RESTful interface to a Kafka cluster, making it easy to produce and consume messages, view the state of thecluster, and perform administrative actions without using the native Kafka protocol or clients.
https://docs.confluent.io/current/kafka-rest/docs/index.html
Confluent提供的Kafka RESTful接口服务组件。
可以通过Restful接口而不是本机Kafka协议或客户端的情况下,很容易的生成和使用消息,而且还可以查看集群状态以及执行管理操作。
3.4 Schema-Registry
Schema Registry provides a serving layer for your metadata. Itprovides a RESTful interface for storing and retrieving Avro schemas. It storesa versioned history of all schemas, provides multiple compatibility settingsand allows evolution of schemas according to the configured compatibilitysettings and expanded Avro support.
https://docs.confluent.io/current/schema-registry/docs/index.html
Schema-Registry是为元数据管理提供的服务,同样提供了RESTful接口用来存储和获取schemas,它能够保存数据格式变化的所有版本,并可以做到向下兼容。
Schema-Registry还为Kafka提供了Avro格式的序列化插件来传输消息。
Confluent主要用Schema-Registry来对数据schema进行管理和序列化操作。
3.5 Connect
Kafka Connect is a framework for connecting Kafka with external systems such as databases,key-value stores, search indexes, and file systems.Using Kafka Connect you canuse existing connector implementations for common data sources and sinks to move data into and out of Kafka.
https://docs.confluent.io/current/connect/index.html
Kafka Connect是 Kafka的一个开源组件,是用来将Kafka与数据库、key-value存储系统、搜索系统、文件系统等外部系统连接起来的基础框架。
通过使用Kafka Connect框架以及现有的连接器可以实现从源数据读入消息到Kafka,再从Kafka读出消息到目的地的功能。
Confluent 在Kafka connect基础上实现了多种常用系统的connector免费让大家使用,提供的列表如下:
- Kafka Connect ActiveMQ Connector
- Kafka FileStream Connectors
- Kafka Connect HDFS
- Kafka Connect JDBC Connector
- Confluent Kafka Replicator
- Kafka Connect S3
- Kafka Connect Elasticsearch Connector
- Kafka Connect IBM MQ Connector
- Kafka Connect JMS Connector
这些connector都可以拿来免费使用,而且Confluent 在GitHub上提供了源码,可以根据自身业务需求进行修改。
3.6 ksql-server
KSQL is thestreaming SQL engine for Apache Kafka that you can use to perform streamprocessing tasks using SQL statements.
https://docs.confluent.io/current/streams-ksql.html
KSQL是使用SQL语句对Apache Kafka执行流处理任务的流式SQL引擎。
Confluent 使用KSQL对Kafka的数据提供查询服务.
4. 小结
以上主要对Confluent的起源,Confluent Platform的功能、组成以及相关服务进行了介绍。相信大家通过本文对Confluent有了初步的认识与了解,这也为后面的实践打下了基础。
因为Confluent Platform功能庞大,服务众多,刚开始用起来也可能比较迷惑。但好在官网各种文档比较详细,也有相应的博客供大家交流,如果有本文还未说明的地方,大家也可以到官网进一步查阅。
最后尽请期待接下来的实践篇,下篇将一步步介绍如何搭建出一套高性能的数据转移系统。
如果想获得更多,欢迎关注公众号:七分熟pizza
公众号里我会分享更多技术以及职场方面的经验,大家有什么问题也可以直接在公众号向我提问交流。
