5、Confluent Platform安装配置和常用操作详细教程
Confluent安装配置及操作教程
- > 环境准备
-
- Confluent Platform对应的Kafka版本
- 对应KSQL版本
- 对应Scala版本
- 对应Zookeeper版本
- 操作系统环境
- JAVA环境
- Step1:安装并开启Confluent Platform(本次下载社区版)
- Step2:修改配置
-
- (1)设置环境变量
- (2)Zookeeper配置
- (3)Kafka配置
- Step3:开启confluent
- Step4:创建Kafka topic
-
- (1)创建两个Kafka topic
- (2)安装Kafka Connector并生成示例数据
- Step5:使用KSQL创建并写入流和表
-
- 创建Stream和Table
- 创建Stream
- 创建Table
- 写查询
- Step6:监控数据流量
- Step7:登录Confluent Control center
- Step7:停止融合平台
> 环境准备
Confluent Platform对应的Kafka版本
| Confluent Platform | Apache Kafka |
|---|---|
| 2.0.x | 0.9.0.x |
| 3.0.x | 0.10.0.x |
| 3.1.x | 0.10.1.x |
| 3.2.x | 0.10.2.x |
| 3.3.x | 0.11.0.x |
| 4.0.x | 1.0.x |
| 4.1.x | 1.1.x |
| 5.0.x | 2.0.x |
| 5.1.x | 2.1.x |
| 5.2.x | 2.2.x |
| 5.3.x | 2.3.x |
| 5.4.x | 2.4.x |
对应KSQL版本
| KSQL version | 5.4 |
|---|---|
| Apache Kafka version | 0.11.0 and later |
| Confluent Platform version | 3.3.0 and later |
对应Scala版本
| Confluent Platform | Scala Version |
|---|---|
| 1.0.0 | 2.10, 2.11 |
| 2.0.x | 2.10, 2.11 |
| 3.0.x | 2.10, 2.11 |
| 3.1.x | 2.10, 2.11 |
| 3.2.x | 2.10, 2.11 |
| 3.3.x | 2.11 |
| 4.0.x | 2.11 |
| 4.1.x | 2.11 |
| 5.0.x | 2.11 |
| 5.1.x | 2.11 |
| 5.2.x | 2.11, 2.12 |
| 5.3.x | 2.11, 2.12 |
| 5.4.x | 2.11, 2.12 |
对应Zookeeper版本
| Confluent Platform | ZooKeeper |
|---|---|
| 3.0.x | 3.4.6 |
| 3.1.x | 3.4.8 |
| 3.2.x | 3.4.9 |
| 3.3.x | 3.4.10 |
| 4.0.x | 3.4.10 |
| 4.1.x | 3.4.10 |
| 5.0.x | 3.4.13 |
| 5.1.x | 3.4.13 |
| 5.2.x | 3.4.13 |
| 5.3.x | 3.4.14 |
| 5.4.x | 3.5.6 |
操作系统环境

Confluent Platform当前不支持Windows。Windows用户可以下载和使用ZIP和TAR档案,但必须直接运行JAR文件。
JAVA环境
从Confluent Platform 5.0开始,最低要求的版本是Java Development Kit(JDK)8。不再支持Java 7或更早版本。使用完整的JDK,而不是Java Runtime Environment(JRE)。支持OpenJDK,Zulu OpenJDK和Oracle。
| Confluent Platform | Java Version |
|---|---|
| 5.4.x | 1.8.0_202, 11.0_4 |
| 5.3.x | 1.8.0_60, 11.0_2 |
| 5.2.x | 1.8.0_60, 11.0_2 |
| 5.1.x | 1.8.0_60 |
| 5.0.x | 1.8.0_60 |
| 4.1.x | 1.7.0_60, 1.8.0_60 |
| 4.0.x | 1.7.0_60, 1.8.0_60 |
| 3.3.x | 1.7.0_60, 1.8.0_60 |
| 3.2.x | 1.7.0_60, 1.8.0_60 |
| 3.1.x | 1.7.0_60, 1.8.0_60 |
| 3.0.x | 1.7.0_60, 1.8.0_60 |
| 2.0.x | 1.7.0_60, 1.8.0_60 |
| 1.0.0 | 1.7.0_60, 1.8.0_60 |
Step1:安装并开启Confluent Platform(本次下载社区版)
方式一:通过官网下载tar包
下载地址:Get Started Free
方式二:通过命令行下载
wget -P ~/Downloads/kafka http://packages.confluent.io/archive/5.2/confluent-5.2.3-2.12.tar.gz
扩展知识:
Linux系统中的wget是一个下载文件的工具,它用在命令行下。
默认文件下载在当前工作路径,可以设置-P参数指定文件的下载地址。
下载文件到~/download目录中
#wget -P ~/download file.name
curl和wget的区别和使用
curl,wget指定下载目录,tar,unzip指定解压目录
文件目录
| 文件夹 | 描述 |
|---|---|
| /bin/ | 启动和停止服务的驱动脚本 |
| /etc/ | 配置文件 |
| /lib/ | 系统服务 |
| /log/ | 日志文件 |
| /share/ | jar包和许可证 |
| /src/ | 需要依赖于平台构建的源文件 |
Step2:修改配置
(1)设置环境变量
在/etc/profile添加
export CONFLUENT_HOME=<path>
export PATH=$PATH:CONFLUENT_HOME/bin
(2)Zookeeper配置
编辑confluent/etc/kafka/zookeeper.properites,更改存储路径
dataDir=<path-confluent>/data/zookeeper #数据存储路径
dataDir可根据自己情况更改
参考文档:Running ZooKeeper in Production
(3)Kafka配置
编辑confluent/etc/kafka/server.properties,更改存储路径
log.dirs=<path-confluent>/data/kafka
log.dirs可根据自己情况更改
参考文档:Running Kafka in Production
其余配置参考文章:数据库实时转移之Confluent环境搭建(二)
Step3:开启confluent
- 全部开启
$ bin/confluent start
This CLI is intended for development only, not for production
https://docs.confluent.io/current/cli/index.html
Using CONFLUENT_CURRENT: /tmp/confluent.kCqiBZdw
Starting zookeeper
zookeeper is [UP]
Starting kafka
kafka is [UP]
Starting schema-registry
schema-registry is [UP]
Starting kafka-rest
kafka-rest is [UP]
Starting connect
connect is [UP]
Starting ksql-server
ksql-server is [UP]
Starting control-center
control-center is [UP]
若单独启动:
# 启动zookeeper server
bin/zookeeper-server-start etc/kafka/zookeeper.properties
# 启动kafka server
bin/kafka-server-start etc/kafka/server.properties
# 启动ksql server
bin/ksql-server-start -daemon etc/ksql/ksql-server.properties
Step4:创建Kafka topic
(1)创建两个Kafka topic
创建一个名为的主题users
bin/kafka-topics --create --zookeeper localhost:2181 \
> --replication-factor 1 --partitions 1 --topic users
Created topic "users".
创建一个名为的主题pageviews
bin/kafka-topics --create --zookeeper localhost:2181 \
--replication-factor 1 --partitions 1 --topic pageviews
Created topic "pageviews".
(2)安装Kafka Connector并生成示例数据
使用Kafka Connect运行名为的演示源连接器kafka-connect-datagen,该连接器将为Kafka主题创建示例数据pageviews和users。
运行Kafka Connect Datagen连接器的一个实例,pageviews以AVRO格式为主题生成Kafka数据。
wget https://github.com/confluentinc/kafka-connect-datagen/raw/master/config/connector_pageviews_cos.config
curl -X POST -H "Content-Type: application/json" --data @connector_pageviews_cos.config http://localhost:8083/connectors
运行Kafka Connect Datagen连接器的一个实例,users以AVRO格式为主题生成Kafka数据。
wget https://github.com/confluentinc/kafka-connect-datagen/raw/master/config/connector_users_cos.config
curl -X POST -H "Content-Type: application/json" --data @connector_users_cos.config http://localhost:8083/connectors
Step5:使用KSQL创建并写入流和表
在此步骤中,将在上一步中创建的pageviews和users主题上运行KSQL查询。以下KSQL命令从KSQL CLI运行。
创建Stream和Table
启动ksql
bin/ksql
默认情况下,KSQL尝试将其日志存储在logs相对于ksql可执行文件位置的目录中。例如,如果ksql安装在/usr/local/bin/ksql,则它将尝试将其日志存储在中/usr/local/logs。如果您ksql从默认的Confluent Platform位置运行,则/bin必须使用LOG_DIR变量覆盖此默认行为。
创建Stream
从Kafka的主题pageviews中创建一个流pageviews,指定value_format的AVRO
CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR) \
WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');
- ksqlDB要求使用Kafka自己的序列化器或兼容的序列化器对密钥进行序列化。ksqlDB支持INT、BIGINT、DOUBLE和STRING键类型。
- viewtime:viewtime列值用作新流的底层Apache Kafka®主题中的Apache Kafka®消息时间戳。
- userid:userid列是新流的键。
- kafka_topic:流下面的Kafka主题的名称。如果存在将在已经存在的主题上创建流,如果不存在它将被自动创建。
- VALUE_FORMAT:ksqlDB无法推断主题值的数据格式,因此必须提供存储在主题中的值的格式。在本例中,值格式是avro。
- partitions:为location主题创建的分区的数量。请注意,对于已经存在的主题,不需要此参数。
- 创建一个包含三列的名为pageviews的Kafka主题流。如果Apache Kafka®中的消息键值与ksqlDB流中定义的列之一相同,则可以在WITH子句中提供此信息。例如,如果Apache Kafka®消息键具有与pageid列相同的值,您可以像这样编写CREATE STREAM语句:
CREATE STREAM pageviews
(viewtime BIGINT,
userid VARCHAR,
pageid VARCHAR)
WITH (KAFKA_TOPIC='pageviews',
VALUE_FORMAT='DELIMITED',
KEY='pageid');
Message
----------------
Stream created
----------------
查看Stream
SHOW STREAMS;
Stream Name | Kafka Topic | Format
-------------------------------------------------
PAGEVIEWS | pageviews | AVRO
-------------------------------------------------
创建Table
从Kafk主题的主题users中创建一个多列的表users,用value_format的AVRO
CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, \
userid VARCHAR) \
WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO', KEY = 'userid');
Message
---------------
Table created
---------------
查询Tabel
SHOW TABELS;
Table Name | Kafka Topic | Format | Windowed
--------------------------------------------------------------
USERS | users | AVRO | false
--------------------------------------------------------------
写查询
(1)earliest为auto.offset.reset参数添加定制查询属性。指示KSQL查询从头开始读取所有可用的主题数据。此配置用于每个后续查询。有关更多信息,请参阅KSQL Configuration Parameter Reference
SET 'auto.offset.reset'='earliest';
Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'
(2)创建一个查询,该查询从流中返回数据,结果限制为三行。
SELECT pageid FROM pageviews LIMIT 3;
Page_45
Page_38
Page_11
LIMIT reached for the partition.
Query terminated
(3)创建一个针对female用户的持久查询。该查询的结果将写入Kafka的PAGEVIEWS_FEMALE 主题。此查询丰富了pageviews通过执行STREAM与用户ID表,该查询需要有条件gender = 'FEMALE'
CREATE STREAM pageviews_female AS SELECT users.userid AS userid, pageid, \
regionid, gender FROM pageviews LEFT JOIN users ON pageviews.userid = users.userid \
WHERE gender = 'FEMALE';
Message
----------------------------
Stream created and running
----------------------------
(4)使用LIKE创建一个符合条件(regionid)的永久查询。该查询的结果将写入名为pageviews_enriched_r8_r9的Kafka主题
CREATE STREAM pageviews_female_like_89 WITH (kafka_topic='pageviews_enriched_r8_r9', \
value_format='AVRO') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9';
Message
----------------------------
Stream created and running
----------------------------
(5)创建一个持久查询,当计数大于1时,将在30秒的翻滚窗口中对每个区域和性别组合的浏览量进行 计数。由于该过程是分组和计数,因此结果现在是表而不是流。该查询的结果将写入名为的Kafka主题PAGEVIEWS_REGIONS。
CREATE TABLE pageviews_regions AS SELECT gender, regionid , \
COUNT(*) AS numusers FROM pageviews_female WINDOW TUMBLING (size 30 second) \
GROUP BY gender, regionid HAVING COUNT(*) > 1;
Message
---------------------------
Table created and running
---------------------------
Step6:监控数据流量
使用命令查看流或表的详细信息。例如,运行以下命令以查看流
DESCRIBE EXTENDED pageviews_female_like_89;
Type : STREAM
Key field : PAGEVIEWS.USERID
Timestamp field : Not set - using
Key format : STRING
Value format : AVRO
Kafka output topic : pageviews_enriched_r8_r9 (partitions: 4, replication: 1)
Field | Type
--------------------------------------
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system)
USERID | VARCHAR(STRING) (key)
PAGEID | VARCHAR(STRING)
REGIONID | VARCHAR(STRING)
GENDER | VARCHAR(STRING)
--------------------------------------
Queries that write into this STREAM
-----------------------------------
id:CSAS_PAGEVIEWS_FEMALE_LIKE_89 - CREATE STREAM pageviews_female_like_89 WITH (kafka_topic='pageviews_enriched_r8_r9', value_format='AVRO') AS SELECT * FROM pageviews_female WHERE regionid LIKE '%_8' OR regionid LIKE '%_9';
For query topology and execution plan please run: EXPLAIN
Local runtime statistics
------------------------
messages-per-sec: 2.01 total-messages: 10515 last-message: 3/14/18 2:25:40 PM PDT
failed-messages: 0 failed-messages-per-sec: 0 last-failed: n/a
(Statistics of the local KSQL server interaction with the Kafka topic pageviews_enriched_r8_r9)
使用EXPLAIN命令发现查询执行计划。例如,运行以下命令以查看以下查询的执行计划CTAS_PAGEVIEWS_REGIONS:
EXPLAIN CTAS_PAGEVIEWS_REGIONS;
Type : QUERY
SQL : CREATE TABLE pageviews_regions AS SELECT gender, regionid , COUNT(*) AS numusers FROM pageviews_female WINDOW TUMBLING (size 30 second) GROUP BY gender, regionid HAVING COUNT(*) > 1;
Local runtime statistics
------------------------
messages-per-sec: 1.42 total-messages: 13871 last-message: 3/14/18 2:50:02 PM PDT
failed-messages: 0 failed-messages-per-sec: 0 last-failed: n/a
(Statistics of the local KSQL server interaction with the Kafka topic PAGEVIEWS_REGIONS)
Execution plan
--------------
> [ PROJECT ] Schema: [GENDER : STRING , REGIONID : STRING , NUMUSERS : INT64].
> [ FILTER ] Schema: [PAGEVIEWS_FEMALE.GENDER : STRING , PAGEVIEWS_FEMALE.REGIONID : STRING , PAGEVIEWS_FEMALE.ROWTIME : INT64 , KSQL_AGG_VARIABLE_0 : INT64 , KSQL_AGG_VARIABLE_1 : INT64].
> [ AGGREGATE ] Schema: [PAGEVIEWS_FEMALE.GENDER : STRING , PAGEVIEWS_FEMALE.REGIONID : STRING , PAGEVIEWS_FEMALE.ROWTIME : INT64 , KSQL_AGG_VARIABLE_0 : INT64 , KSQL_AGG_VARIABLE_1 : INT64].
> [ PROJECT ] Schema: [PAGEVIEWS_FEMALE.GENDER : STRING , PAGEVIEWS_FEMALE.REGIONID : STRING , PAGEVIEWS_FEMALE.ROWTIME : INT64].
> [ SOURCE ] Schema: [PAGEVIEWS_FEMALE.ROWTIME : INT64 , PAGEVIEWS_FEMALE.ROWKEY : STRING , PAGEVIEWS_FEMALE.USERID : STRING , PAGEVIEWS_FEMALE.PAGEID : STRING , PAGEVIEWS_FEMALE.REGIONID : STRING , PAGEVIEWS_FEMALE.GENDER : STRING].
Processing topology
-------------------
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [PAGEVIEWS_FEMALE])
--> KSTREAM-MAPVALUES-0000000001
Processor: KSTREAM-MAPVALUES-0000000001 (stores: [])
--> KSTREAM-TRANSFORMVALUES-0000000002
<-- KSTREAM-SOURCE-0000000000
...
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000008 (topics: [KSQL_Agg_Query_1521052072079-repartition])
--> KSTREAM-AGGREGATE-0000000005
Processor: KSTREAM-AGGREGATE-0000000005 (stores: [KSQL_Agg_Query_1521052072079])
--> KTABLE-FILTER-0000000009
<-- KSTREAM-SOURCE-0000000008
...
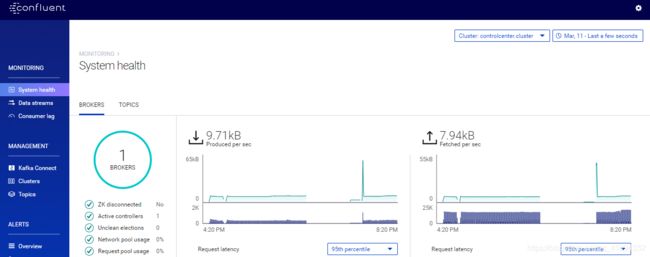
Step7:登录Confluent Control center
localhost:9021 查看情况
Step7:停止融合平台
使用Confluent CLI stop命令停止Confluent Platform
bin/confluent stop
使用destroy命令销毁Confluent Platform实例中的数据。
bin/confluent destroy
参考文章:
Quick Start using Community Components(Local)
使用confluent本地安装和使用kafka
Confluent完全分布式框架搭建