pyspark学习--2、pyspark的运行方法尝试
pyspark学习--2、pyspark的运行方法尝试以及各种示例代码尝试
- 运行方法
- pycharm运行
- 系统中的spark运行:spark-submit
- 启动spark任务运行
- 示例代码
- 流式文本处理 streamingcontext
- 流文本单词计数
- 报错汇总
运行方法
先使用pycharm构建一个小的项目:环境目录如下,需要红框中的两个文件:

其中 test.json中文件内容如下:
{'name': 'goddy','age': 23}
{'name': 'wcm','age': 31}
test_pyspark.py文件内容如下:
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark = SparkSession \
.builder \
.appName("goddy-test") \
.getOrCreate()
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
# 这里路径可是是相对路径,但是如果要放到系统的pyspark执行,那要指定绝对路径,否则会报错
data = spark.read.schema(schema).json('../data/')
#data = spark.read.schema(schema).json('/Users/ciecus/Documents/pyspark_learning/data/')
data.printSchema()
data.show()
pycharm运行
直接点击pycharm的运行键,结果如下:

系统中的spark运行:spark-submit
(1)索引到spark目录下
(2)./bin/spark-submit /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
运行结果:结果很长,所以需要用grep进行结果过滤,这里没有对结果过滤,只截取部分结果
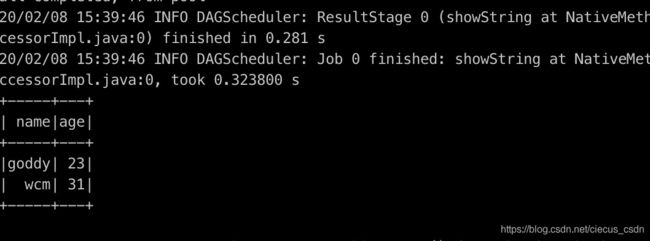
启动spark任务运行
(1)索引到spark目录下
(2)启动master节点
./sbin/start-master.sh
此时,用浏览器打开 http://localhost:8080/ ,我们就可以看到spark的管理界面了,从中取到spark master的地址。

(3)启动slave节点,即工作节点
./sbin/start-slave.sh spark://promote.cache-dns.local:7077
后面的spark地址就是上图红框中的地址
此时管理界面,多了一个工作节点。

(4)提交任务到master
这里也需要绝对路径
./bin/spark-submit --master spark://promote.cache-dns.local:7077 /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
- 分布式(这里还没有尝试过)
示例运行命令
./bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 520M --executor-memory 520M --executor-cores 1 --num-executors 1 /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
执行时可以观察下管理界面。
![]()
点击application id 查看结果,日志分成两个部分,stdout(记录结果)stderr(记录错误)
- 这里任务被kill了,查找原因

示例代码
流式文本处理 streamingcontext
流文本单词计数
wordcount.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a local StreamingContext with two working thread and batch interval of 1 second
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 5)
# Create a DStream that will connect to hostname:port, like localhost:9999
lines = ssc.socketTextStream("localhost", 9999)
# Split each line into words
words = lines.flatMap(lambda line: line.split(" "))
# Count each word in each batch
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.pprint()
ssc.start() # Start the computation
ssc.awaitTermination() #
(1)先到终端运行如下命令:
nc -lk 9999(按完之后毫无反应,接下来直接执行就行)
(2)在pycharm中运行word_count.py
然后在刚刚的命令行界面输入:
a b a d d d d

然后摁回车。可以看到pycharm中输出如下结果:

报错汇总
(1)执行:./bin/spark-submit /Users/ciecus/Documents/pyspark_learning/src/test_pyspark.py
错误:py4j.protocol.Py4JJavaError: An error occurred while calling o31.json.

错误原因分析:代码中文件路径为相对路径,如果在命令行中运行,文件路径必须为绝对路径。
(2)启动spark任务之后,任务被kill
参考链接:
- 使用pyspark & spark thrift server的使用
- Mac下安装spark,并配置pycharm-pyspark完整教程
【备注,这里的pycharm的环境配置的所有操作我都没有做,但是还是能正常运行,所以我觉得不用配置pycharm环境】