Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts
代码:https://github.com/asahi417/DocumentClassification
https://github.com/asahi417/DocumentClassification/blob/master/sequence_modeling/model/cnn_char.py
abstract
短文本的情感分析
挑战:有限的文本信息
本文提出DCNN(deep convolutional neural network),从字符级到句子级来进行分析。
语料采用两个不同领域的,Stanford Sentiment Treebank (SSTb),电影评论,Stanford Twitter Sentiment corpus (STS),Twitter信息
1 Introduction
advent: [ˈædˌvent] n 到来
crescent: [ˈkrez(ə)nt] n 新月形,新月的
2 Neural Network Architecture
网络的输入:一句话的词序列,经过一系列层,抽取信息,网络从字符级到句子级抽取信息,
2.1 Initial Representation Levels

2.1.1 Word-Level Embeddings

2.1.2 Character-Level Embeddings
捕获形态和形状的信息,必须考虑词的所有字母和选择哪些信息是重要的。
例如,对Twitter数据的情感分析,重要信息可以出现在#号的部分,“#SoSad”, “#ILikeIt”,或是副词,以“ly”结束,例如“beautifully”, “perfectly” and “badly”,我们使用的方法和dos Santos and Zadrozny, 2014相同,这是基于卷积的方法,具体是:卷积产生词的character-level特征,然后用max-pooling的办法把他们结合在一起,获得这个词的基于character-level的词嵌入。


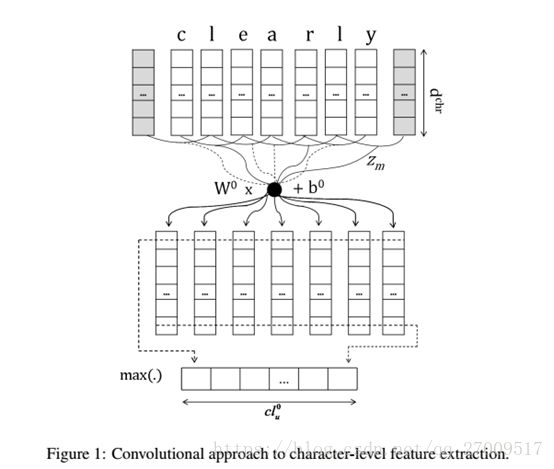
2.2 Sentence-Level Representation and Scoring


2.3 Network Training

3 Related Work
关于情感分析的网络结构
循环网络
Socher et al., 2011:a semi-supervised approach based on recursive autoencoders for predicting sentiment distributionsè这个方法给不同的短语学习向量空间表示,并探索句子的递归特征。
Socher et al., 2012:a matrix-vector recursive neural network model for semantic compositionalityè有能力学习短语和句子的compositional 向量表示。这些向量捕获了潜在句子结构,矩阵捕获邻近的词和短语的意思。
Socher et al., 2013b:Recursive Neural Tensor Network (RNTN) architectureè用词向量表示短语和parse tree,然后计算高节点的向量。
我们的工作采用前向传播网络,而不是递归的。
NLP’任务中的卷积网络
Collobert et al., 2011:use a convolutional network for the semantic role labeling task with the goal avoiding excessive task-specific feature engineering
Collobert, 2011:use a similar network architecture for syntactic parsing
CharSCNN与这些网络有关,使用一层卷积层提取句子特征,这些网络的不同在于使用多一层卷积层进行字符级的特征提取。
在神经网络结构使用intra-word,
Luong et al., 2013:use a recursive neural network (RNN) to explicitly model the morphological structures of words and learn morphologically-aware embeddings
Lazaridou et al., 2013:use compositional distributional semantic models, originally designed to learn meanings of phrases, to derive representations for complex words, in which the base unit is the morpheme
Chrupala, 2013:proposes a simple recurrent network (SRN) to learn continuous vector representations for sequences of characters, and use them as features in a conditional random field classifier to solve a character level text segmentation and labeling task
4 Experimental Setup and Results
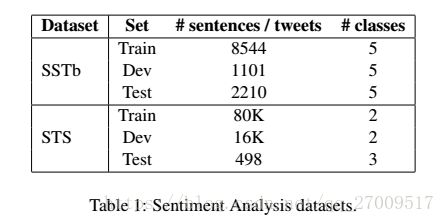
4.1 Sentiment Analysis Datasets
(Stanford Sentiment Treebank (SSTb)
Stanford Twitter Sentiment corpus (STS):test set was manually annotated by Go et al
4.2 Unsupervised Learning of Word-Level Embeddings
word-level的embedding对于CharSCNN结构很重要,他们是要捕获syntactic和semantic信息,这对于情感分析特别重要,这些工作可以有下成果获得:
Collobert et al., 2011; Luong et al., 2013; Zheng et al., 2013; Socher et al., 2013a:
Mikolov et al., 2013:implements the continuous bag-of-words and skip-gram architectures for computing vector representations of words
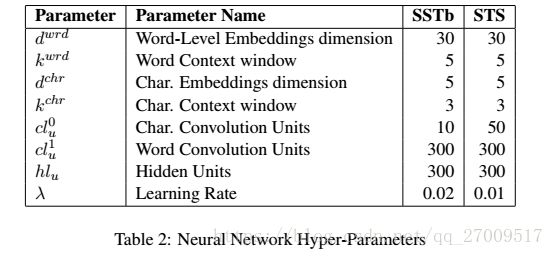
4.3 Model Setup
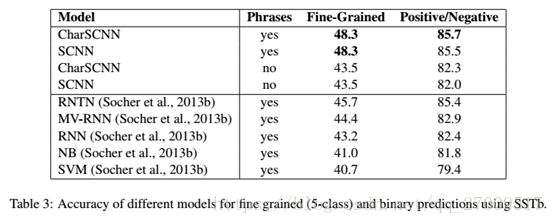
4.4 Results for SSTb Corpus
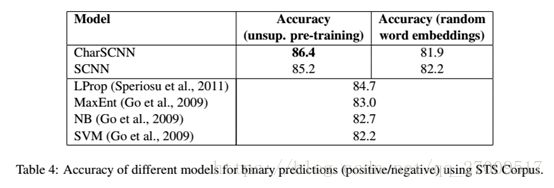
4.5 Results for STS Corpus
4.6 Sentence-level features
5 Conclusions