focal loss论文笔记
作者提出,训练集中的类别不平衡是阻碍一阶段检测器达到与二阶段检测器相同效果的主要原因(因为在二阶段检测中,在前景和背景数量上通过启发式采样例如固定前景背景比例,online hard mining部分解决了这一问题),因此提出一个新的loss函数。
相反在一阶段中,尽管启发式采样也被应用,但是训练过程仍然被易被分类的背景examples所主导。这一问题可以通过bootstrapping或者hard example mining解决。
对于bootstrapping介绍见https://blog.csdn.net/chenhongc/article/details/9404583
hard negative mining见https://blog.csdn.net/u012285175/article/details/77866878
而focal loss的思想即,在训练中通过scaling factor自动降低易训练的样本对训练的贡献,而提升难训练样本的权重。至于loss公式具体的形式并不是最重要的,以下给出了一种形式:

在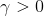 的前提下(高IOU的样本被权重弱化)调整几个值显示不同IOU下单独的loss结果。
的前提下(高IOU的样本被权重弱化)调整几个值显示不同IOU下单独的loss结果。
作者同时给出网络结构RetinaNet(基于ResNet-101-FPN主干)来显示focal loss的效果。
RetinaNet借鉴了许多先前的稠密检测器,例如RPN提出的anchor,SSD和FPN中的特征金字塔等等。然而作者宣称,这些好的效果主要来自loss函数而不是网络结构。
对于focal loss,与其说处理了hard examples,不如说是降低了easy examples的贡献权重。因此作者说,focal loss专注于训练一个hard examples的稀疏集合。
作者在cross entropy(CE)上做出修改,提出了一个loss函数的基准:

原先的交叉熵函数如下:


![]()
其中,![]() 表示ground truth class而
表示ground truth class而![]() 表示对标签为y=1下的分类的预测概率。
表示对标签为y=1下的分类的预测概率。
作者正式给出公式如下:

对于在 的不同取值loss的情况,前面图表中已给出。
的不同取值loss的情况,前面图表中已给出。
作者指出,这一公式有两个很重要的性质:1.当样本被错分类而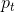 很小的时候,modulating factor接近1而loss无影响。接近1时,factor接近0而易分类的样本的被降低权重。2.平滑地调节易分类样本权重下降的比例(实验中
很小的时候,modulating factor接近1而loss无影响。接近1时,factor接近0而易分类的样本的被降低权重。2.平滑地调节易分类样本权重下降的比例(实验中![]() 效果最好)(这一点以后应该会有数学解释)
效果最好)(这一点以后应该会有数学解释)
在具体实现中采用![]() 产生相对更高的准确率。
产生相对更高的准确率。
其中![]()
二阶段检测器中经常不采用平衡因子或者提出的loss公式。因为二阶段检测器通过第一个cascade stage中去除了绝大多数易被检测的负样本,又在第二阶段中控制正负样本比例1:3,而这一比例就是一个隐含的平衡因子。
作者指出,因为在早期实验中ResNet最后一层的特征产出较低的AP,因此作者采用FPN作为backbone。
对于anchor box的使用与FPN相似。anchor的scale在金字塔P3-P7层上从32*32-512*512,宽高比采用{1:2,1:1,2:1},对于更加稠密的图像(输入图像更大)采用{![]() }倍数比例的scale的anchor。对于IOU>0.5的anchor被指派到GT上,IOU<0.4被标记为前景,其他的会被忽略。
}倍数比例的scale的anchor。对于IOU>0.5的anchor被指派到GT上,IOU<0.4被标记为前景,其他的会被忽略。
网络结构图如下:

classification subnet中接4个3*3的卷积,每个后面接RELU激活,再接softmax输出预测结果。对于分类子网权重在所有的金字塔层级连接的子网中共享。
box regression subnet使用与classification subnet相似的结构但参数不同,最终对于每一个空间位置输出4A维度的线性输出。
在前向传播中,为了加速,在每个FPN层级上仅对于IOU>0.05的最多前1000个bounding box进行处理,最后对所有层级的预测结果采用IOU阈值0.5进行非极大值抑制。
focal loss中对![]() 具有相对的鲁棒性。对于所有anchor计算loss,但是只采用分配到GT的anchor box的数量进行nomalization,因为大多数anchor是易训练的负样本并且只带来微不足道的loss。总体上来说当上升时
具有相对的鲁棒性。对于所有anchor计算loss,但是只采用分配到GT的anchor box的数量进行nomalization,因为大多数anchor是易训练的负样本并且只带来微不足道的loss。总体上来说当上升时 应该轻微下降,因为随着易分类的负样本权重被降低,正样本的重要性就不那么需要被强调了,实验中测得
应该轻微下降,因为随着易分类的负样本权重被降低,正样本的重要性就不那么需要被强调了,实验中测得![]() 时效果最好。
时效果最好。
作者在ResNet-50-FPN和ResNet-101-FPN上进行实验,RetinaNet子网(分类和回归子网)上所有除了最后一层都采用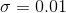 ,b=0进行高斯初始化。对于分类子网上的最后一层,设置
,b=0进行高斯初始化。对于分类子网上的最后一层,设置![]() ,其中
,其中 表示在训练刚开始时每个anchor被标记为前景的confidence。实验中使用
表示在训练刚开始时每个anchor被标记为前景的confidence。实验中使用![]() 。这样使得大量的背景anchor不会产生巨大的,不稳定的loss。
。这样使得大量的背景anchor不会产生巨大的,不稳定的loss。
实验中参数调节设置及对应结果如下:


COCO数据集结果如下:
