散点图
基础的散点图
预览数据:
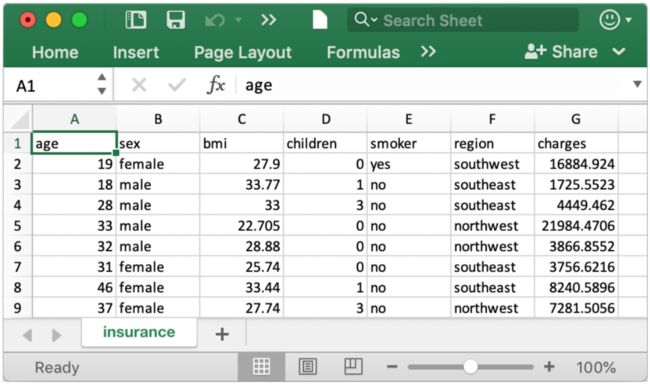
设个数据集一共有7个维度,其中数值型数据为:
- bmi
- charges
分类型数据为:
- age
- sex
- children
- smoker
- region
在数据可视化之前,需要先区分数据类型,这一方式有利于我们在可视化阶段设置参数和选择维度。
可视化结果:
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])
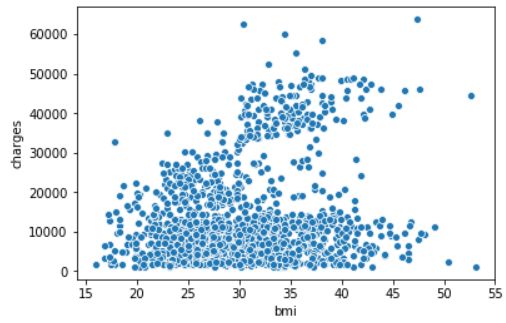
scatterplot
可以发现,散点图:scatterplot的横纵轴都是数值型数据。
再来看另一个散点图:
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])
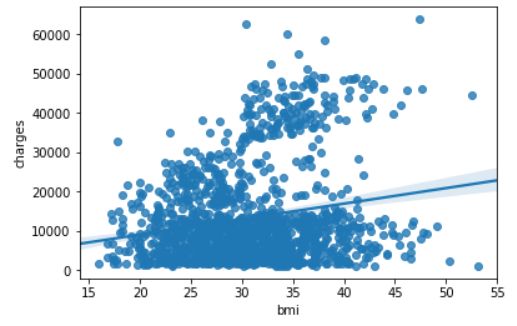
regplot
seaborn.regplot可以返回带回归曲线的散点图。
怎么用上标签?
我们在分析数据集的时候,可以使用分类型数据,为数据加上标签:
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])
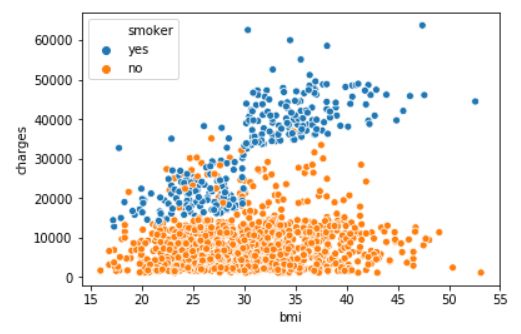
scatterplot with hue
这个散点图比上文的散点图多了一个参数:hue=insurance_data['smoker'],smoker变量是二元变量,所以会将散点图的数据点分为两种颜色。
sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)
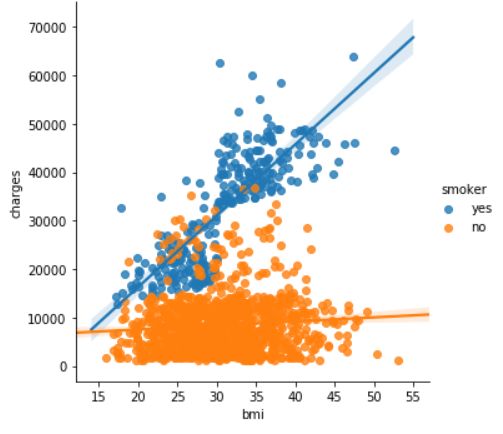
lmplot
sns.swarmplot(x=insurance_data['smoker'], y=insurance_data['charges'])
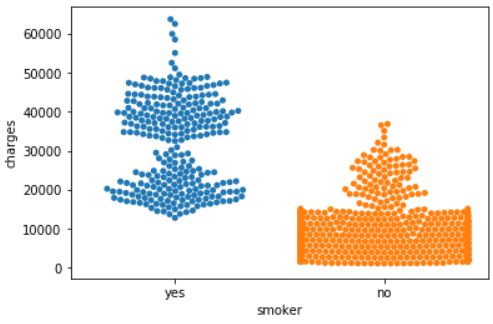
swarmplot
seaborn.swarmplot用于查看数据的分布
频率直方图和密度图
直方图
sns.distplot(a=iris_data['Petal Length (cm)'], kde=False)
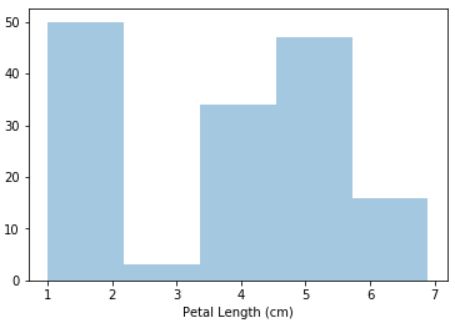
distplot
seaborn.distplot函数的输入是一列数据,因为直方图用于统计
密度图
sns.kdeplot(data=iris_data['Petal Length (cm)'], shade=True)
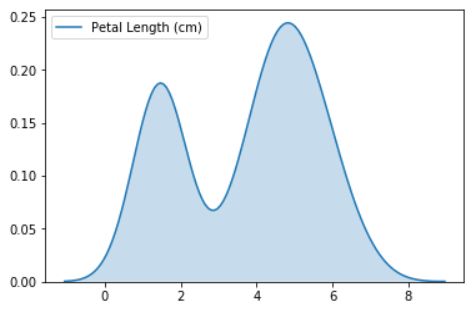
2D KDE plots
sns.jointplot(x=iris_data['Petal Length (cm)'], y=iris_data['Sepal Width (cm)'], kind="kde")
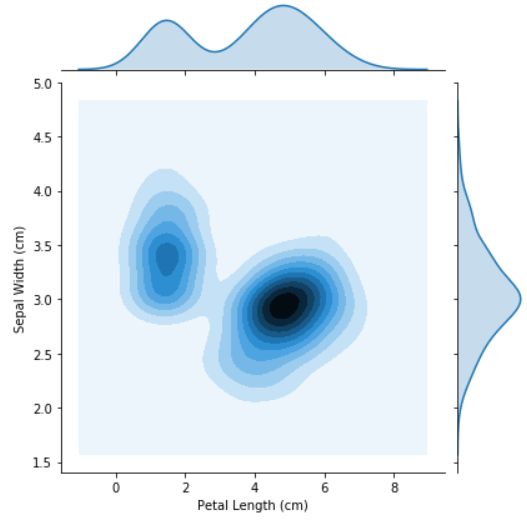
2D KDE plots
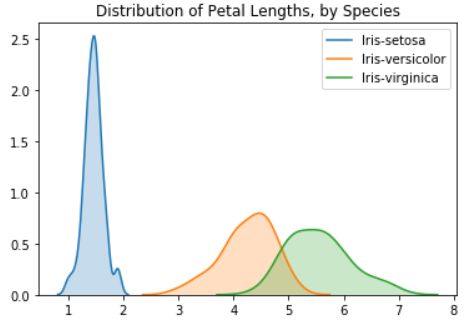
KDE重叠
# KDE plots for each species
sns.kdeplot(data=iris_set_data['Petal Length (cm)'], label="Iris-setosa", shade=True)
sns.kdeplot(data=iris_ver_data['Petal Length (cm)'], label="Iris-versicolor", shade=True)
sns.kdeplot(data=iris_vir_data['Petal Length (cm)'], label="Iris-virginica", shade=True)
# Add title
plt.title("Distribution of Petal Lengths, by Species")