牛客网试题+答案分析+大牛面试经验(8)
一、对线性表进行折半查找时,要求线性表必须()
A、以顺序方式存储
B、以顺序方式存储,且数据元素有序
C、以链接方式存储
D、以链接方式存储,且数据元素有序
答案:B
解析:折半查找又称二分法查找,要求必须有序,一般是对顺序存储进行操作
二、最坏情况下,合并两个大小为n的已排序数组所需要的比较次数_____。
A、2n
B、2n-1
C、2n+1
D、2n-2
答案:B
解析:挖2n个坑,对每一个坑进行循环,比较两排带头的人,谁大谁先跳,总共比较2n-1次,最后一个不用比了,因为就剩你了。
或者采用特殊例子法:假设n=1,带入选项即可求解
三、线性表是具有n个()的有限序列(n>0)
A、表元素
B、字符
C、数据元素
D、数据项
E、信息项
答案:C
解析:
数据:信息的载体,能够被计算机识别、存储、加工,包括整数、实数、字符串、图像、声音等
数据元素:数据的基本单位,也称结点、元素、顶点、记录。一个数据元素可由若干个数据项组成
数据项:是具有独立寒意的最小标识单元,也称字段、域、属性等
数据结构:指数据之间的相互关系,即组织形式,有逻辑结构(一般程序中出现的形式)和物理结构之分(内存中的连续存储形式);
逻辑结构又有线性(非空,仅由一个开始结点和一个终端结点,除首尾结点之外,所有节点均只有一个直接前区和一个直接后继,
如一维数组、栈、队列、链表、串等)和非线性之分(一个结点可以有多个直接前区和多个直接后继,如多维数组、广义表、树、图等)
四、对两个数组 a 和 b 进行如下初始化
char a[] = "ABCDEF";
char b[] = {'A','B','C','D','E','F'};
以下叙述正确的是( )
A、a 与 b 数组完全相同
B、a 与 b 长度相同
C、a 和 b 中都存放了字符串
D、a 数组比 b 数组长
答案:D
解析:你首先要明白的是什么是长度:数组元素的个数称之为数组的长度。
现在再看问题 第一个是 字符串,第二个是字符数组 ,字符串以'\0'为结束符号,字符数组不用。
所以B 对。 要说明的是,虽然他们长度相同,不过占的内存字节数是不一样的,
第一个占7个字节(后面的'\0'占一个。)第二个占6个字节。
五、以下程序段的运行结果是( )。
char str[10] = "output";
printf("\"%s\"\n", str);
A、output
B、"output"
C、\"output\"
D、编译错误
答案:B
解析:\n 换行
\r 回车
\f 换页符
\b 退格
\0 空格
\s 字符串
\t 制表符
\” 双引号
\’ 单引号
\ddd 八进制字符串(ddd)
\uxxxx 16进制unicode字符串(xxxx)
\" 这里的\为转义字符 ,第一个和第二个一样。 第三个就不解释了。
六、一个栈的进栈序列是 a , b , c , d , e ,则栈的不可能的输出序列是 ()
A、edcba
B、decba
C、dceab
D、abcde
答案:C
解析:
A:push push push push push pop pop pop pop pop
B:push push push push pop push pop pop pop pop
C:错
D:push pop push pop push pop push pop push pop
我的理解:
网上查到的资料是
对于出栈序列的每一个元素,该元素后比该元素先入栈的一定按照降序排列。
A.比如说第一个是e,比e先进的有abcd,所以说明e进来的时候abcd已经全部进栈了,
所以只能是edcba,e的后面都是降序,嗯,没毛病。
B.第一个是d,比d先进的有abc,我们可以看到序列中出现的abc都是降序的,嗯,也没毛病。
C.第一个是d,比d先进的有abc,但是我们可以发现后面出现了ab,而不是ba,所以有毛病了。错。
D.第一个是a,没有谁比a更先进栈,所以a可以随时出栈,后面的都是一样的道理。
因此,看一道题问出栈序列对不对时这一条规矩很有用
七、一个栈的输入序列为12345,则下列序列中是栈的输出序列的是()
A、23415
B、54132
C、31245
D、14253
答案:A
解析:
A.1进栈,2进栈,2出栈,3进栈,3出栈,4进栈,4出栈,1出栈,5进栈,5出栈。可行。
B.根据5和4的顺序推断是12345依次进栈,然后再依次出栈,1的位置错了。
C.因为开头是3,所以是123依次进栈,出栈时1不可能紧靠在3后面。
D.1进栈1出栈可行。然后是234依次进栈,4出栈,2不可能跟在后面出栈。
八、元素a, b, c, d, e 依次进入初始为空的栈中,若元素进栈后可停留、可出栈,直到所有的元素都出栈,则在所有可能的出栈序列中,以元素 d 开头的序列个数是( )。
A、3
B、4
C、5
D、6
答案:B
解析:若是d第一个出栈,说明abc已经入栈,此时有以下几种情况:
ecba;ceba;cbea;cbae。
即cba的顺序是一定的,只是e可以在cba依次弹出的过程中压入再弹出。
九、若要删除 book 表中的所有数据,如下哪些语法是错误的?
A、drop table book;
B、truncate table book;
C、delete from book;
D、del *from book;
答案:A D
解析:
A: drop table book 是删除整个表,题目的潜在意思是删除表中的数据而并非删除整个表。因此A错。
B: truncate table book 是删除表中的数据,删除速度比delete更快,无法撤回(回退)。
C: delete from book 删除数据表中的数据,可以回退,可添加where 子句。
D:语法错误。
十、栈和队列的共同特点是 ( ) 。
A、只允许在端点处插入和删除元素
B、都是先进后出
C、都是先进先出
D、没有共同点
答案:A
解析:A 栈:先进后出,队列:先进先出,都只允许在端点处插入和删除元素
十一、判定一个队列QU(最多元素为m0)为满队列的条件是()。
A、QU->rear - QU->front = = m0
B、QU->rear - QU->front -1= = m0
C、QU->front = = QU->rear
D、QU->front = = QU->rear+1
正确答案:A
解析:题中没有说是循环队列,所以这里指的是普通队列,front指向队首,rear指向队尾的下一个位置,所以选择A
十二、在循环队列中, 若尾指针 rear 大于头指针 front, 其元素个数为 rear- front。
A、正确
B、错误
答案:A
解析:
我觉得这样的:书上给的公式为((rear-front)+MAXSIZE)%MAXSIZE。
考虑以下两个情况。当rear小于front时,rear-front为负数,所以需要加上最大存储容量。
但是rear大于front时,rear-front+MAXSIZE比实际长度大了MAXSIZE。需要取余。
本题告诉rear大于front则只需rear-front。
十三、有一个虚拟存储系统,若进程在内存中占3页(开始时内存为空),若采用先进先出(FIFO)页面淘汰算法,当执行如下访问页号序列后1,2,3,4,5, 1,2,5,1,2,3,4,5,会发生多少缺页?
A、7
B、8
C、9
D、10
答案:D
解析:
FIFO(first in first out),发生缺页时的调入顺序即为淘汰顺序
1、访问1,缺页,调入1,内存中为 1, ,;
2、访问2,缺页,调入2,内存中为 1,2,;
3、 访问3,缺页,调入3,内存中为 1,2,3;
4、 访问4,缺页,调入4,淘汰1,内存中为 4,2,3;
5、 访问5,缺页,调入5,淘汰2,内存中为 4,5,3;
6、 访问1,缺页,调入1,淘汰3,内存中为 4,5,1;
7、 访问2,缺页,调入2,淘汰4,内存中为 2,5,1;
8、 访问5,不缺页,内存中为 2,5,1;
9、 访问1,不缺页,内存中为 2,5,1;
10、 访问2,不缺页,内存中为 2,5,1;
11、访问3,缺页,调入3,淘汰5,内存中为 2,3,1;
12、访问4,缺页,调入4,淘汰1,内存中为 2,3,4;
13、访问5,缺页,调入5,淘汰2,内存中为 5,3,4;
十四、对连通图进行深度优先遍历可以访问到该图中的所有顶点。( )
A、正确
B、错误
答案:A
解析:对连通图进行深度优先遍历是可以访问到该图的所有顶点的。注意前提:该图为连通图,不存在孤立点的情况。
十五、假设我们用d=(a1,a2,….a5)表示无向无自环图G的5个顶点的度数,下面给出的哪组值是可能的
A、{3,4,4,3,1}
B、{4,2,2,1,1}
C、{3,3,3,2,2}
D、{3,4,3,2,1}
答案:B
解析:首先要理解无自环是指一个顶点不能自己到自己,而不是图没有环,所以这题目的图是可以有环的。
然后无向图边数最多和总度数最多的情况下,就是完全无向图,边数为E=n(n-1)/2条,总度数为边数的两倍即D=n(n-1)。
所以只要边数小于等于E,度小于等于D,且总度数D是一个偶数,那么就都可以构成图。
题目5个顶点,其完全无向图的边数为10,总度数为20,备选答案所有数字之和是偶数且不大于20的,即为答案。
十六、在图G的最小生成树G1中,可能会有某条边的权值超过未选边的权值。()
A、正确
B、错误
答案:A
解析:最小生成树的性质:
1.不唯一
2.边的权值总是唯一的,虽然最小生成树不唯一,但其对应的边的权值之和总是唯一的,而且是最小的。
3.最小生成树的边数为顶点数减1.
十七、若(u,v)是连通网络的一条最小权值的边,则不论采用何种方法构造该网络的最小生成树, 所构造出最小生成树一定包含(u,v)这条边。
A、是
B、否
答案:B
解析:题目表诉不明确,如果(u,v)是连通网络的唯一的一条最小权值的边,那么一定包含(u,v)这条边
十八、若用邻接矩阵存储有向图,矩阵中主对角线以下的元素均为零,则关于该图拓扑序列的结论是()。
A、存在,且唯一
B、存在,且不唯一
C、存在,可能不唯一
D、无法确定是否存在
答案:C
解析:上三角矩阵说明有向图只有序号小的节点单向指向序号大的节点,所以存在拓扑序列。
加上条件A[i][i+1]全为1才是唯一的,题目没有说明这一点,所以是可能唯一
十九、在哈希查找中,"比较"操作一般也是不可避免的()
A、对
B、错
答案:A
解析:由于冲突的产生,使得哈希表的查找过程仍然是一个给定值与关键字比较的过程。
二十、假设把整数关键码K散列到有N个槽的散列表,以下那些散列函数是好的散列函数?
A、h(k)=k/n
B、h(k)=1
C、h(k)=k mod N
D、h(k)=(k + Random(N )) mod N;Random(N)返回一个0到N-1的整数
答案:C
解析:D中random(N)会造成hash后的数值不确定
好的散列函数要求:(1)计算简单,至少散列函数的计算时间不应该超过其他查找技术与关键字比较的时间;
(2)计算出的散列地址分布均匀,这样可以保证存储空间的有效利用,并减少为处理冲突而耗费的时间。
二十一、散列法存储的思想是由关键字值决定数据的存储地址,这样的说法正确吗?
A、正确
B、不正确
答案:A
解析:散列法存储的基本思想是:由节点的关键码值决定节点的存储地址。
二十二、散列函数有一个共同性质,即函数值应按()取其值域的每一个值。
A、最大概率
B、最小概率
C、同等概率
D、平均概率
答案::C
二十三、以下说法正确的是 。
A、散列法存储的思想是由关键字值决定数据的存储地址
B、散列表的结点中只包含数据元素自身的信息,不包含指针
C、负载因子是散列表的一个重要参数,它反映了散列表的饱满程度
D、散列表的查找效率主要取决于散列表构造时选取的散列函数和处理冲突的方法
答案:C
解析:
A:散列法存储的思想是由关键字和散列函数共同决定数据的存储地址的。
B:对于拉链法来说,数组的每一个节点指向一个链表,链表中的每一个节点都存储了散列值为该索引的键值对,
而链表的维护需要节点之间的指针来维护!
D:散列表的查找效率主要取决于散列函数、处理冲突的方法和装载因子
二十四、下面的序列中,()是堆
A、1,2,8,4,3,9,10,5
B、1,5,10,6,7,8,9,2
C、9,8,7,6,4,8,2,1
D、9,8,7,6,5,4,3,7
答案: A
解析: 先画出完全二叉树结构,判断是否满足
最大堆:左右孩子都比父节点小
最小堆:左右孩子都比父节点大
二十五、堆是一种有用的数据结构。下列关键码序列 是一个堆()。
A、94,31,53,23,16,72
B、94,53,31,72,16,23
C、16,53,23,94,31,72
D、16,31,23,94,53,72
答案:D
二十六、已知序列25, 13, 10, 12, 9 是大根堆,在序列尾部插入新元素 18,将其再调整为大根堆,调整过程中元素之间进行的比较次数是( )。
A、1
B、2
C、4
D、5
答案: B
解析:把大根堆画成完全二叉树后,堆插入元素相当于是从最后面添加叶子节点18,
先是18和10比较,18>10,将18与10对调,继续判断18与25的大小。 所以总共比较2次。
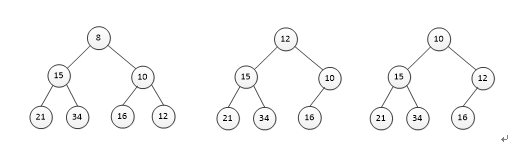
二十七、已知小根堆为8,15,10,21,34,16,12,删除关键字8之后需重建堆,在此过程中,关键字之间的比较次数是 。
A、1
B、2
C、3
D、4
答案:C
解析:删除8后,将12移动到堆顶,第一次是15和10比较,第二次是10和12比较并交换,第三次还需比较12和16,故比较次数为3次。
二十八、就平均查找速度而言,下列几种查找速度从慢至快的关系是___________。
A、顺序 折半 哈希 分块
B、顺序 分块 折半 哈希
C、分块 折半 哈希 顺序
D、顺序 哈希 分块 折半
答案:B
解析:顺序查找的时间复杂度为o(n)
分块查找的时间复杂度为o(log2n)到o(n)之间
二分查找的时间复杂度为o(log2n)
哈希查找的时间复杂度为o(1)
二十九、当采用分快查找时,数据的组织方式为 ( )
A、数据分成若干块,每块内数据有序
B、数据分成若干块,每块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引块
C、数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引块
D、数据分成若干块,每块(除最后一块外)中数据个数需相同
答案:B
三十、公司里面有1001个员工,现在要在公司里面找到最好的羽毛球选手,也就是第一名,每个人都必须参赛,问至少要比赛多少次才能够找到最好的羽毛球员工。
A、1001
B、1000
C、500
D、501
答案: B
解析:相当于冒泡法排序第一趟找出最大值,比较n-1次
三十一、已知有序序列b c d e f g q r s t,则在二分查找关键字b的过程中,先后进行比较的关键字依次是多少?()
A、f d b
B、f c b
C、g c b
D、g d b
答案: B
解析:
b c d e f g q r s t 二分查找,折半法
① low = 0,high = 9,mid = (low+ high)/2=4, ∴ 'b'比较a[4]='f',<,找左边 ( b~e )
② low = 0,high = mid-1 = 3, mid = 3/2=1, ∴ 'b'比较a[1]='c' , <,找左边(b~b)
③ low = 0,high = mid -1 = 0,mid = 0,∴ 'b' 比较a[0] = 'b',找到(若未找到,low=high,也停止查找)
所以比较的顺序就是f c b
三十二、设有关键字n=2h -1,构成二叉排序树,每个关键字查找的概率相等,查找成功的ASL最大是n()
A、对
B、错
答案: B
解析 :
什么是ASL?平均查找长度。
ASL =∑PiCi (Pi 为查找第i个记录的概率,Ci为找到第i个记录数据需要比较的次数,Ci随查找过程的不同而不同。)
二分查找:
满二叉树时,若每个记录的查找概率相等时,Pi =1/n;ASL = 1/n(1*20+2*21+.....+n*2n-1)=log2(n+1)-1
要求查找成功的ASL最大,就是只有左子树或者只有右子树的情况@羽毛,即顺序表以第一个数或最后一个数为根节点作二叉排序树。
同样,若每个记录的查找概率相等时,Pi =1/n。∑PiCi =1/n∑(n-i+1)=(n+1)/2
所以是错的,选B。