python 学习笔记十 rabbitmq,twisted,redis (进阶篇)
RabbitMQ
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
安装
http://erlang.org/download/otp_win64_18.3.exe #依赖包erlang
http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.1/rabbitmq-server-3.6.1.exe
pip install pika
简单的通信
import pika #producer端 #建立连接 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) #创建channel channel = connection.channel() #声明queue channel.queue_declare(queue='testMQ') channel.basic_publish(exchange='',#Producer只能发送到exchange,它是不能直接发送到queue的,发送到默认exchange routing_key="testMQ",#路由key发送指定队列 body="hello this is test!") #消息 print(" [x] Sent 'hello this is test!'") #关闭连接 connection.close()
import pika #建立连接 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) #创建channel channel = connection.channel() #如果生产者先运行并创建了队列这里就可以不用声明,但是有可能消费者先运行 下面的basic_consume就会因为没有队列报错。 channel.queue_declare(queue="testMQ") #定义回调函数用于取出队列中的数据 def callback(ch, method, properties, body): print(" [x] Received %r" % body) channel.basic_consume(callback, queue="testMQ", no_ack=True) #不用确认消息 print(" [*] Waiting for messages. To exit press Ctrl + C ") channel.start_consuming()#监听数据
默认情况下,RabbitMQ 会顺序的分发每个Message。当每个收到ack后,会将该Message删除,然后将下一个Message分发到下一个Consumer。这种分发方 式叫做round-robin。
acknowledgment 消息确认
每个Consumer可能需要一段时间才能处理完收到的数据。如果在这个过程中,Consumer出错了,异常退出了,而数据还没有处理完成,那么 非常不幸,这段数据就丢失了。因为我们采用no-ack的方式进行确认,也就是说,每次Consumer接到数据后,而不管是否处理完 成,RabbitMQ Server会立即把这个Message标记为完成,然后从queue中删除了。
如果一个Consumer异常退出了,它处理的数据能够被另外的Consumer处理,这样数据在这种情况下就不会丢失了(注意是这种情况下)。
为了保证数据不被丢失,RabbitMQ支持消息确认机制,即acknowledgments。为了保证数据能被正确处理而不仅仅是被Consumer收到,那么我们不能采用no-ack。而应该是在处理完数据后发送ack。
在处理数据后发送的ack,就是告诉RabbitMQ数据已经被接收,处理完成,RabbitMQ可以去安全的删除它了。
如果Consumer退出了但是没有发送ack,那么RabbitMQ就会把这个Message发送到下一个Consumer。这样就保证了在Consumer异常退出的情况下数据也不会丢失。
这里并没有用到超时机制。RabbitMQ仅仅通过Consumer的连接中断来确认该Message并没有被正确处理。也就是说,RabbitMQ给了Consumer足够长的时间来做数据处理。
import pika #producer端 #建立连接 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) #生成通道 channel = connection.channel() #声明queue 生产者必须声明 channel.queue_declare(queue='testMQ') channel.basic_publish(exchange='', routing_key="testMQ", body="hello this is test!") print(" [x] Sent 'hello this is test!'") #关闭连接 connection.close()
#client
import pika connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) channel = connection.channel() #如果生产者先运行并创建了队列这里就可以不用声明,但是有可能消费者先运行 下面的basic_consume就会因为没有队列报错。 #channel.queue_declare(queue="testMQ") #已经创建的队列不是durable再赋值durable也无法改变 channel.queue_declare(queue="task_mq",durable=True) #定义回调函数用于取出队列中的数据 def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(5) print("ok") ch.basic_ack(delivery_tag = method.delivery_tag) #消息持久化 channel.basic_consume(callback, queue = "task_mq", no_ack = False) #no-ack = False,如果生产者遇到情况(its channel is closed, connection is closed, #or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。但是生产者挂了,消息就没有了!!! print(" [*] Waiting for messages. To exit press Ctrl + C ") channel.start_consuming()
Message durability消息持久化
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() #确保队列不丢失 channel.queue_declare(queue='task_mq', durable=True) channel.basic_publish(exchange='', routing_key='task_mq', body="will i come back!", properties=pika.BasicProperties( delivery_mode = 2,#make messages persistent )) print(" [x] Sent 'will i come back!'") connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters("localhost")) channel = connection.channel() #如果生产者先运行并创建了队列这里就可以不用声明,但是有可能消费者先运行 下面的basic_consume就会因为没有队列报错。 #channel.queue_declare(queue="testMQ") #已经创建的队列,再赋值durable是无法改变的,rabbitmq已经再维护它了。 channel.queue_declare(queue="task_mq",durable=True) #定义回调函数用于取出队列中的数据 def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(5) print("ok") ch.basic_ack(delivery_tag = method.delivery_tag) #消息持久化 channel.basic_consume(callback, queue = "task_mq", no_ack = False) #no-ack = False,如果生产者遇到情况(its channel is closed, connection is closed, #or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。 #也就是说如果生产者挂了,消息就没有了!!! print(" [*] Waiting for messages. To exit press Ctrl + C ") channel.start_consuming()
为了数据不丢失,我们采用了: 在数据处理结束后发送ack,这样RabbitMQ Server会认为Message Deliver 成功。 持久化queue,可以防止RabbitMQ Server 重启或者crash引起的数据丢失。 持久化Message,理由同上。 但是这样能保证数据100%不丢失吗? 答案是否定的。问题就在与RabbitMQ需要时间去把这些信息存到磁盘上,这个time window虽然短,但是它的确还是有。
在这个时间窗口内如果数据没有保存,数据还会丢失。还有另一个原因就是RabbitMQ并不是为每个Message都做fsync:
它可能仅仅是把它保存到Cache里,还没来得及保存到物理磁盘上。
消息公平分发
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() #确保队列不丢失 channel.queue_declare(queue='task_mq', durable=True) channel.basic_publish(exchange='', routing_key='task_mq', body="will i come back!", properties=pika.BasicProperties( delivery_mode = 2,#make messages persistent )) print(" [x] Sent 'will i come back!'") connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() # make message persistent channel.queue_declare(queue='testMQ') def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(5) print('ok') ch.basic_ack(delivery_tag = method.delivery_tag) #告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。 channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue='testMQ', no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
Publish\Subscribe(消息发布\订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了,
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息。
- fanout: 所有bind到此exchange的queue都可以接收消息
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
import pika import sys #发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。 # 所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。 connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #定义exchange 类型为fanout channel.exchange_declare(exchange='logs', type='fanout') #发送消息 message = ' '.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #定义exchange channel.exchange_declare(exchange='logs', type='fanout') #定义队列每一个订阅者都有自己的队列,队列名是随机的 #Consumer关闭连接时,这个queue要被deleted。可以加个exclusive的参数。 result = channel.queue_declare(exclusive=True) #获取队列名 queue_name = result.method.queue #将队列和exchangebanding 默认发布不是直接发送到队列而是先到exchange #由exchange分发给订阅者 channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
有选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
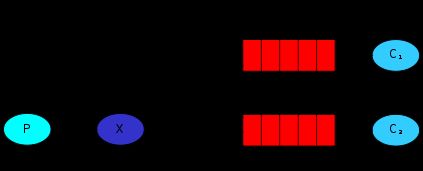
exchange X和两个queue绑定在一起。C1的binding key是error。C2的binding key是info,error和warning。当P publish key是info时,exchange会把它放到C2。如果是error那么就会到C1,C2。
import pika import sys #连接rabbitmq connection = pika.BlockingConnection(pika.ConnectionParameters( host="localhost" )) #生成channel channel = connection.channel() #设置exchange为direct模式 channel.exchange_declare(exchange="direct_logs", type = "direct") #队列关键字 自己输入或默认info serverity = sys.argv[1] if len(sys.argv) > 1 else "info" #消息 自己输入或默认 message = ' '.join(sys.argv[2:]) or "hello world" #发布 channel.basic_publish(exchange="direct_logs", routing_key=serverity, #根据关键字发送到指定队列 body=message) print(" [x] Sent %r:%r" % (serverity, message)) connection.close()
import pika import sys #建立连接 connection = pika.BlockingConnection(pika.ConnectionParameters( host="localhost" )) #生成channel channel = connection.channel() #声明exchang channel.exchange_declare(exchange="direct_logs", type="direct") #声明专用队列队列名随机 result = channel.queue_declare(exclusive=True) #获取队列名 queue_name = result.method.queue #用户定义消息关键字 serverities = sys.argv[1:] if not serverities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for serverity in serverities: channel.queue_bind(exchange="direct_logs", queue=queue_name, routing_key=serverity)#关键字 print(' [*] Waiting for logs. To exit prees CTRL+C') #获取数据 def callback(ch, method, propertes, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
Topic exchange
对于Message的routing_key是有限制的,不能使任意的。格式是以点号“."分割的字符表。比如:"stock.usd.nyse", "nyse.vmw", "quick.orange.rabbit"。你可以放任意的key在routing_key中,当然最长不能超过255 bytes。
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
发送者路由值 队列中 old.boy.python old.* -- 不匹配 old.boy.python old.# -- 匹配
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()