查询优化:sql2000中的连接两个表的查询语句的执行路径对性能的影响比较
sql2000中的连接两个表的查询语句的执行路径对性能的影响
有两个表
表1 pay_itemdetail 大概 2-3百万条数据
表2 pay_builddetail 大概 55 条数据
1原语句,效率非常低,用时20秒以上
select * from pay_itemdetail with(nolock)
where builditemid in (select id from pay_builddetail where buildid = 1)
2 改进的语句求count ,又两种方法,连接,用时1秒
1)in 的方式
select count(1) from pay_itemdetail with(nolock)
where builditemid in (select id from pay_builddetail where buildid = 1)
2)连接的方式
select count(1) from pay_itemdetail a with(nolock),pay_builddetail b with(nolock)
where b.buildid=100 and a.builditemid = b.id
3 最后的改进 top ,用时0秒
select top 1 a.* from pay_itemdetail a with(nolock),pay_builddetail b with(nolock)
where b.buildid=1 and a.builditemid =b.id
4 求top时如果没有记录匹配,速度很慢,用时10秒
select top 1 a.* from pay_itemdetail a with(nolock),pay_builddetail b with(nolock)
where b.buildid=100 and a.builditemid =b.id
5. 对4进行进一步分析祥解
用
select top 1 a.* from pay_itemdetail a with(nolock),pay_builddetail b with(nolock)
where b.buildid=1 and a.builditemid =b.id
来取第一条符合条件的 pay_itemdetail 中的数据,当 b.buildid=1 条件成立时,执行时间只用0秒;
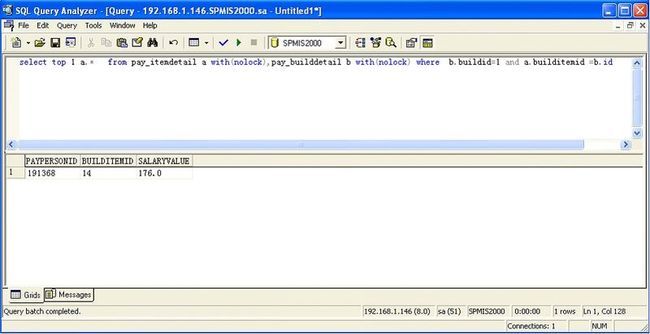
但当将语句该为
select top 1 from pay_itemdetail a with(nolock),pay_builddetail b with(nolock)
where b.buildid=100 and a.builditemid =b.id
pay_builddetail 表中不存在 b.buildid=100 的记录,执行时间竟用了12秒。
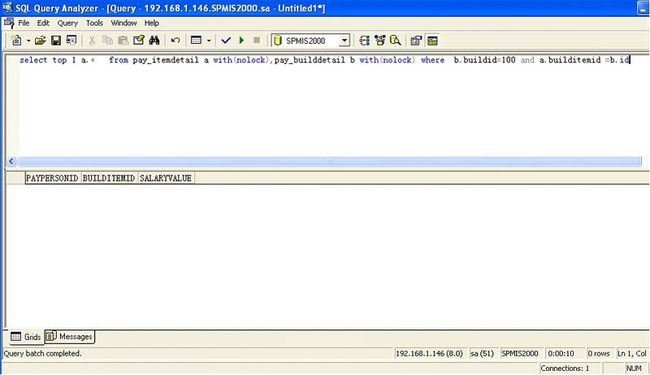
通过查看sql语句查询路径发现问题
sql2000在进行查询解释时,
1)把 pay_itemdetail 中的记录全部取出
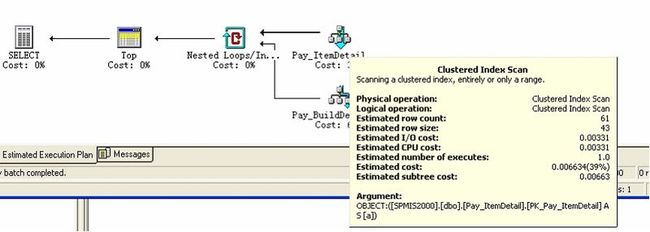
2)在根据b.buildid=1 条件从pay_builddetail表中的取出符合条件的记录;
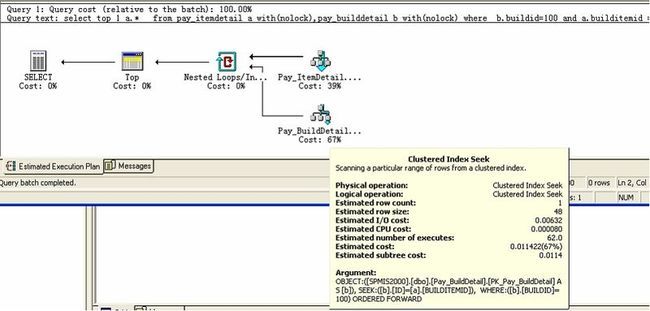
3)最后进行 nested loop 从 取出符合的第一条的记录。
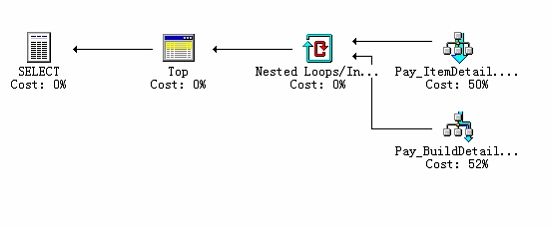
4)但pay_builddetail表中不存在b.buildid=100记录时,它要在nested loop 时循环了2-3百万次,所以就用了20多秒。
知道慢的原因了,只要让sql2000在进行查询解释时先从 pay_builddetail 表中取出符合条件的id,再从 pay_itemdetail 中去出符合条件的记录,循环的次数最多也就 55次了吗。
于是语句修改为
select top 1 a.* from pay_itemdetail a with(nolock),pay_builddetail b with(nolock) where b.buildid=100 and a.builditemid = (b.id+0)
再查看sql用时语句查询路径,变为了
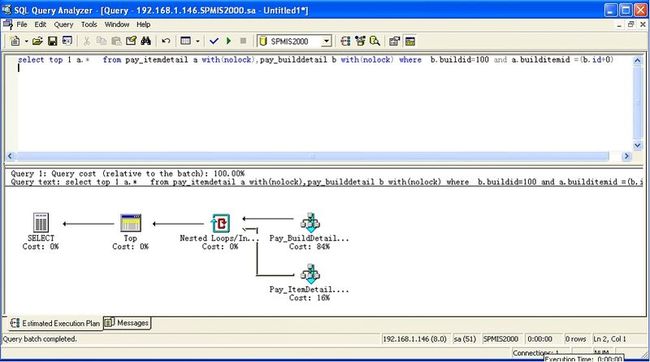
OK问题解决。
<<sql2000中的连接两个表的查询语句的执行路径对性能的影响.doc>>