linux命令笔记
Linux Top 命令详解
TOP命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况。
TOP是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
top - 12:38:33 up 50 days, 23:15, 7 users, load average: 60.58, 61.14, 61.22
Tasks: 203 total, 60 running, 139 sleeping, 4 stopped, 0 zombie
Cpu(s) : 27.0%us, 73.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1939780k total, 1375280k used, 564500k free, 109680k buffers
Swap: 4401800k total, 497456k used, 3904344k free, 848712k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4338 oracle 25 0 627m 209m 207m R 0 11.0 297:14.76 oracle
4267 oracle 25 0 626m 144m 143m R 6 7.6 89:16.62 oracle
3458 oracle 25 0 672m 133m 124m R 0 7.1 1283:08 oracle
3478 oracle 25 0 672m 124m 115m R 0 6.6 1272:30 oracle
3395 oracle 25 0 672m 122m 113m R 0 6.5 1270:03 oracle
3480 oracle 25 0 672m 122m 109m R 8 6.4 1274:13 oracle
3399 oracle 25 0 672m 121m 110m R 0 6.4 1279:37 oracle
4261 oracle 25 0 634m 100m 99m R 0 5.3 86:13.90 oracle
25737 oracle 25 0 632m 81m 74m R 0 4.3 272:35.42 oracle
7072 oracle 25 0 626m 72m 71m R 0 3.8 6:35.68 oracle
16073 oracle 25 0 630m 68m 63m R 8 3.6 175:20.36 oracle
16140 oracle 25 0 630m 66m 60m R 0 3.5 175:13.42 oracle
16122 oracle 25 0 630m 66m 60m R 0 3.5 176:47.73 oracle
786 oracle 25 0 627m 63m 63m R 0 3.4 1:54.93 oracle
4271 oracle 25 0 627m 59m 58m R 8 3.1 86:09.64 oracle
4273 oracle 25 0 627m 57m 56m R 8 3.0 84:38.20 oracle
22670 oracle 25 0 626m 50m 49m R 0 2.7 84:55.82 oracle
一. TOP前五行统计信息
统计信息区前五行是系统整体的统计信息。
1. 第一行是任务队列信息
同 uptime 命令的执行结果:
[root@localhost ~]# uptime
13:22:30 up 8 min, 4 users, load average: 0.14, 0.38, 0.25
其内容如下:
| 12:38:33 |
当前时间 |
| up 50days |
系统运行时间,格式为时:分 |
| 1 user |
当前登录用户数 |
| load average: 0.06, 0.60, 0.48 |
系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
2. 第二、三行为进程和CPU的信息
当有多个CPU时,这些内容可能会超过两行。内容如下:
| Tasks: 29 total |
进程总数 |
| 1 running |
正在运行的进程数 |
| 28 sleeping |
睡眠的进程数 |
| 0 stopped |
停止的进程数 |
| 0 zombie |
僵尸进程数 |
| Cpu(s): 0.3% us |
用户空间占用CPU百分比 |
| 1.0% sy |
内核空间占用CPU百分比 |
| 0.0% ni |
用户进程空间内改变过优先级的进程占用CPU百分比 |
| 98.7% id |
空闲CPU百分比 |
| 0.0% wa |
等待输入输出的CPU时间百分比 |
| 0.0% hi |
|
| 0.0% si |
|
3. 第四五行为内存信息。
内容如下:
| Mem: 191272k total |
物理内存总量 |
| 173656k used |
使用的物理内存总量 |
| 17616k free |
空闲内存总量 |
| 22052k buffers |
用作内核缓存的内存量 |
| Swap: 192772k total |
交换区总量 |
| 0k used |
使用的交换区总量 |
| 192772k free |
空闲交换区总量 |
| 123988k cached |
缓冲的交换区总量。 内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖, 该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。 |
二. 进程信息
| 列名 |
含义 |
| PID |
进程id |
| PPID |
父进程id |
| RUSER |
Real user name |
| UID |
进程所有者的用户id |
| USER |
进程所有者的用户名 |
| GROUP |
进程所有者的组名 |
| TTY |
启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR |
优先级 |
| NI |
nice值。负值表示高优先级,正值表示低优先级 |
| P |
最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU |
上次更新到现在的CPU时间占用百分比 |
| TIME |
进程使用的CPU时间总计,单位秒 |
| TIME+ |
进程使用的CPU时间总计,单位1/100秒 |
| %MEM |
进程使用的物理内存百分比 |
| VIRT |
进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP |
进程使用的虚拟内存中,被换出的大小,单位kb。 |
| RES |
进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE |
可执行代码占用的物理内存大小,单位kb |
| DATA |
可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR |
共享内存大小,单位kb |
| nFLT |
页面错误次数 |
| nDRT |
最后一次写入到现在,被修改过的页面数。 |
| S |
进程状态。 |
| COMMAND |
命令名/命令行 |
| WCHAN |
若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags |
任务标志,参考 sched.h |
top 的man 命令解释如下:
Listed below are top's available fields. They are always associated with the letter shown, regardless of the position you may have established for them with the 'o' (Order fields) interactive command.Any field is selectable as the sort field, and you control whether they are sorted high-to-low or low-to-high. For additional information on sort provisions see topic 3c. TASK Area Commands.
a: PID -- Process Id
The task's unique process ID, which periodically wraps, though never restarting at zero.
b: PPID -- Parent Process Pid
The process ID of a task's parent.
c: RUSER -- Real User Name
The real user name of the task's owner.
d: UID -- User Id
The effective user ID of the task's owner.
e: USER -- User Name
The effective user name of the task's owner.
f: GROUP -- Group Name
The effective group name of the task's owner.
g: TTY -- Controlling Tty
The name of the controlling terminal. This is usually the device (serial port, pty, etc.) from which the process was started, and which it uses for input oroutput. However, a task need not be associated with a terminal, in which case you'll see '?' displayed.
h: PR -- Priority
The priority of the task.
i: NI -- Nice value
The nice value of the task. A negative nice value means higher priority, whereas a positive nice value means lower priority. Zero in this field simply means priority will not be adjusted in determining a task's dispatchability.
j: P -- Last used CPU (SMP)
A number representing the last used processor. In a true SMP environment this will likely change frequently since the kernel intentionally uses weak affinity. Also, the very act of running top may break this weak affinity and cause more processes to change CPUs more often (because of the extra demand for cpu time).
k: %CPU -- CPU usage
The task's share of the elapsed CPU time since the last screen update, expressed as a percentage of total CPU time. In a true SMP environment, if 'Irix mode' is Off, top will operate in 'Solaris mode' where a task's cpu usage will be divided by the total number of CPUs. You toggle 'Irix/Solaris' modes with the 'I' interactive command.
l: TIME -- CPU Time
Total CPU time the task has used since it started. When 'Cumulative mode' is On, each process is listed with the cpu time that it and its dead children has used. You toggle 'Cumulative mode' with 'S', which is a command-line option and an interactive command. See the 'S' interactive command for additional information regarding this mode.
m: TIME+ -- CPU Time, hundredths
The same as 'TIME', but reflecting more granularity through hundredths of a sec ond.
n: %MEM -- Memory usage (RES)
A task's currently used share of available physical memory.
o: VIRT -- Virtual Image (kb)
The total amount of virtual memory used by the task. It includes all code, data and shared libraries plus pages that have been swapped out. (Note: you can define the STATSIZE=1 environment variable and the VIRT will be calculated from the /proc/#/state VmSize field.)
VIRT = SWAP + RES.
p: SWAP -- Swapped size (kb)
The swapped out portion of a task's total virtual memory image.
q: RES -- Resident size (kb)
The non-swapped physical memory a task has used.
RES = CODE + DATA.
r: CODE -- Code size (kb)
The amount of physical memory devoted to executable code, also known as the'text resident set' size or TRS.
s: DATA -- Data+Stack size (kb)
The amount of physical memory devoted to other than executable code, also known the 'data resident set' size or DRS.
t: SHR -- Shared Mem size (kb)
The amount of shared memory used by a task. It simply reflects memory that could be potentially shared with other processes.
u: nFLT -- Page Fault count
The number of major page faults that have occurred for a task. A page fault occurs when a process attempts to read from or write to a virtual page that is not currently present in its address space. A major page fault is when disk access is involved in making that page available.
v: nDRT -- Dirty Pages count
The number of pages that have been modified since they were last written to disk. Dirty pages must be written to disk before the corresponding physical memory location can be used for some other virtual page.
w: S -- Process Status
The status of the task which can be one of:
'D' = uninterruptible sleep
'R' = running
'S' = sleeping
'T' = traced or stopped
'Z' = zombie
Tasks shown as running should be more properly thought of as 'ready to run' --their task_struct is simply represented on the Linux run-queue. Even without a true SMP machine, you may see numerous tasks in this state depending on top's delay interval and nice value.
x: Command -- Command line or Program name
Display the command line used to start a task or the name of the associated program. You toggle between command line and name with 'c', which is both a command-line option and an interactive command. When you've chosen to display command lines, processes without a command line (like kernel threads) will be shown with only the program name in parentheses, as in this example: ( mdrecoveryd ) Either form of display is subject to potential truncation if it's too long to fit in this field's current width. That width depends upon other fields selected, their order and the current screen width.
Note: The 'Command' field/column is unique, in that it is not fixed-width. When displayed, this column will be allocated all remaining screen width (up to the maximum 512 characters) to provide for the potential growth of program names into command lines.
y: WCHAN -- Sleeping in Function
Depending on the availability of the kernel link map ('System.map'), this field will show the name or the address of the kernel function in which the task is currently sleeping. Running tasks will display a dash ('-') in this column.
Note: By displaying this field, top's own working set will be increased by over 700Kb. Your only means of reducing that overhead will be to stop and restart top.
z: Flags -- Task Flags
This column represents the task's current scheduling flags which are expressed in hexadecimal notation and with zeros suppressed. These flags are officially documented in <linux/sched.h>. Less formal documentation can also be found on the 'Fields select' and 'Order fields' screens.
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。
2.1 用快捷键更改显示内容。
(1)更改显示内容通过 f键可以选择显示的内容。
按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
(2)按o键可以改变列的显示顺序。
按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
设置完按回车返回界面。
三. 命令使用
详细内容可以参考MAN 帮助文档。这里列举部分内容:
命令格式:
top [-] [d] [p] [q] [c] [C] [S] [n]
参数说明:
d: 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。
p: 通过指定监控进程ID来仅仅监控某个进程的状态。
q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
S: 指定累计模式
s : 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
i: 使top不显示任何闲置或者僵死进程。
c: 显示整个命令行而不只是显示命令名
在top命令的显示窗口,我们还可以输入以下字母,进行一些交互:
帮助文档如下:
Help for Interactive Commands - procps version 3.2.7
Window 1:Def: Cumulative mode Off. System: Delay 4.0 secs; Secure mode Off.
Z,B Global: 'Z' change color mappings; 'B' disable/enable bold
l,t,m Toggle Summaries: 'l' load avg; 't' task/cpu stats; 'm' mem info
1,I Toggle SMP view: '1' single/separate states; 'I' Irix/Solaris mode
f,o . Fields/Columns: 'f' add or remove; 'o' change display order
F or O . Select sort field
<,> . Move sort field: '<' next col left; '>' next col right
R,H . Toggle: 'R' normal/reverse sort; 'H' show threads
c,i,S . Toggle: 'c' cmd name/line; 'i' idle tasks; 'S' cumulative time
x,y . Toggle highlights: 'x' sort field; 'y' running tasks
z,b . Toggle: 'z' color/mono; 'b' bold/reverse (only if 'x' or 'y')
u . Show specific user only
n or # . Set maximum tasks displayed
k,r Manipulate tasks: 'k' kill; 'r' renice
d or s Set update interval
W Write configuration file
q Quit
( commands shown with '.' require a visible task display window )
Press 'h' or '?' for help with Windows,
h或者? : 显示帮助画面,给出一些简短的命令总结说明。
k :终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i:忽略闲置和僵死进程。这是一个开关式命令。
q: 退出程序。
r: 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S:切换到累计模式。
s : 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F :从当前显示中添加或者删除项目。
o或者O :改变显示项目的顺序。
l: 切换显示平均负载和启动时间信息。即显示影藏第一行
m: 切换显示内存信息。即显示影藏内存行
t : 切换显示进程和CPU状态信息。即显示影藏CPU行
c: 切换显示命令名称和完整命令行。 显示完整的命令。 这个功能很有用。
M : 根据驻留内存大小进行排序。
P:根据CPU使用百分比大小进行排序。
T: 根据时间/累计时间进行排序。
W: 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法
-
忘记root登录密码
- 开机出现GRUB引导程序时,按e编辑GRUB引导参数
- 选择以kernel开始的行按e进行编辑
- 在kernel行末尾加上single后回车,按b启动系统进入单用户模式
- 在单用户模式下输入命令passwd root,输入两次密码
- 修改成功,shutdown -r now重启系统
- 新密码登入,成功。
-
history命令显示所有命令记录,然后通过!命令编号调用该命令
- 清屏命令大家都知道clear,还有一个快捷键更方便——ctrl+l
- Vim普通模式下输入ZZ,可以实现保存并退出文档
- echo "hello123" | passwd --stdin jack 通过管道为用户jack设置密码
- uptime 监控CPU使用情况
一、ACL访问控制权限
两个命令:getfacl、setfacl
- getfacl 查看文档的ACL权限
-
setfacl 设置文档ACL权限
- -b 删除所有附加的ACL条目
- -k 删除默认的ACL
- -m 添加ACL权限
- -x 删除指定的ACL条目
- -R 递归处理所有的子文件与子目录
-
实例
- getfacl 2.log 查看文档2.log的ACL权限
- setfacl -m u:user01:rw 2.log 添加ACL条目,使用户user01对2.log文件可读可写
- setfacl -m g:group01:r 2.log 使用户组group01对文件2.log有可写权限
- setfacl -x u:user01 2.log 删除用户user01的ACL条目
- setfacl -x g:group01 2.log 删除组的权限
- setfacl -b 2.log 清除文件2.log所有ACL权限
二、磁盘分区
之前在一篇笔记里已经介绍了fdisk命令的用法,这里就不重复了,这里说一下另外两个命令partprobe和parted。
-
partprobe
- partprobe /dev/sdb 让内核立即读取新的分区表,无需重启电脑就可以识别新创建的分区
-
parted GPT分区方式,不同与传统的MBR分区(使用fdisk)
三、开机启动
学习开机启动命令,先要了解Linux的6种运行级别。
- 0 关机模式
- 1 单用户模式
- 2 无NFS(共享服务)网络的字符界面模式
- 3 全功能字符界面模式
- 4 暂时未定义使用
- 5 图形模式
- 6 重启模式
通过runlevel命令可以查看当前所处的运行级别。服务器版本的Linux一般都是3级别,通过init命令可以改变当前的运行级别,如init 0命令可以直接关机.
好了,可以进入正题了,如何设置开机启动呢?使用命令chkconfig,用法如下:
- chkconfig --list 查询系统服务运行级别信息
- chkconfig --level 指定操作的运行级别,不指定级别时默认为2,3,4,5级别
- 实例:
- chkconfig --list sshd 查看sshd命令的运行级别

- chkconfig sshd on 设置sshd服务在2.3.4.5级别开机启动

- chkconfig --list sshd 查看sshd命令的运行级别
四、内存和硬盘使用情况
1、内存使用
内存的使用情况查看命令,应该很熟悉了,那就是free,但是你真的知道显示出来的各个数据都代表的是什么意思吗?至少之前我是没怎么去了解。

每次看的时候,也就扫了一眼,总共498M,用了263M,还剩235M,就完事了。其他的数据就没怎么看了,这里简单介绍一下其他数是什么含义。
在Linux开机后就会预先提取一部分内存,并划为buffer与cache以供进程随时使用。第一行的used就是这部分内存数263,而后面的buffers代表的是buffer使用剩余的内存数65,cached就是cache剩余的内存数145。那么buffer和cache用了多少呢?第二行中used就是buffer和cache使用的内存数51,那么就有等式263=65+145+51,接下来446系统总剩余的内存数,为分配的有235,分配了但是没有用完的有65+145,那么446=65+145+235。
细心的读者也许一眼就看出了,等式根本不等嘛!别着急,换成字节单位,你再算算!至于原因就很明了了

2、硬盘使用
这里就补充两点。
- df -hT中T的参数代表显示文件系统

- df -i中 i代表的是磁盘inode使用量信息

这里可以看出根分区还剩下313077个inode节点,也就是说如果在更分区下创建313077个空文件,那么就算该磁盘还有容量也再也容不下新增文件了。
五、网络
1、网络参数设置
有两种方式设置网络参数,一是通过命令行设置;二是通过修改参数文件。
命令行设置不外乎ifconfig、route这两个命令,具体使用可以自行查询帮助文档,这里介绍一下修改参数文件来设置网络。
网络的参数文件在/etc/sysconfig/network-scripts/ifcfg-<iface>,其中iface为网卡接口名称。如果只有一块以太网网卡,则一般为ifcfg-eth0,文件有一下字段:
- DEVICE 设备名称 eh0,eth1...
- TYPE 设备类型 ethernet
- BOOTPROTO 启动协议 none|dhcp|static
- HWADDR 硬件地址 MAC地址
- NM_CONTROLLED 网卡是否可以被NetworkManager控制 yes|no
- ONBOOT 开机是否启动该网卡 yes|no
- ONPARENT 真实接口启动后虚拟接口是否启动 yes|no
- IPADDR IP地址
- PREFIX 网络位掩码个数
- NETMASK 子网掩码
- GATEWAY 默认网关
- DNS{1,2} DNS服务器
如我网卡eth1设置静态IP,配置如下图

2、网络故障排错
这块主要介绍5个命令,ping、traceroute、nslookup、dig、netstat。
-
ping 非常常用的命令,测试基本就是4步
- ping 127.0.0.1 ping本地回环,测试本地网络协议是否正常
- ping 192.168.1.101 ping本地IP,测试本地网络接口是否正常
- ping 192.168.1.1 ping本地网关,测试网关是否正常工作
- ping 61.135.169.121 ping外部网络,测试服务商网络是否正常工作
- ping www.baidu.com ping网址,如果上述都正常,而这步ping不通,那么肯定是DNS的问题了
-
traceroute 跟踪数据包的路由过程,可以查看数据包在互联网中哪个节点出现问题,如图
 [+]查看原图
[+]查看原图 -
nslookup 检测本地设置的DNS服务器工作是否正常
- nslookup www.baidu.com 检测本地DNS服务器是否能解析到百度,如图

本地设置的DNS服务器是8.8.8.8,检测到百度对应的两个IP地址
- nslookup www.baidu.com 检测本地DNS服务器是否能解析到百度,如图
-
dig 查看更多关于DNS记录的信息
- dig www.baidu.com 显示比nslookup更详细的信息
-
netstat 网络监控命令,该命令比较强大,可以自行查看帮助文档学习
- netstat -nutlp 查看当前系统开启端口信息

-
一、linux添加swap分区
512M的物理内存,太小了,而阿里云方面初始化系统并没有交换分区;手动添加一个1G大小的swap分区,swap的物理文件在/var目录下创建。
1.1、检测并创建swap
- [root@www ~]# cd /var #进入/var目录
- [root@www var]# dd if=/dev/zero of=swapfile bs=1024 count=1048576 #检测是否存在swap 若不存在则创建
上述命令执行dd时需要一段时间,执行完毕会有类似如下提示信息:
- 1048576+0 records in
- 1048576+0 records out
- 1073741824 bytes (1.1 GB) copied, 18.8023 seconds, 57.1 MB/s
1.2、将刚才dd命令创建的文件转换为swap类型的文件(分区)
- [root@www var]# /sbin/mkswap swapfile #创建swap文件(或分区)
- [root@www var]# /sbin/swapon swapfile #挂载(启用)该swap分区文件
1.3、添加开启启动配置项
- [root@www var]# vi /etc/fstab #vi命令编辑这个文件
- ##################
- #在该文件末尾添加如下内容#
- ##################
- /var/swapfile swap swap defaults 0 0
此处配置是为了下次开机自动挂载该swap分区文件,不需要再手动使用swapon命令。
二、修改linux的主机名
2.1、临时的主机名
- [root@www var]# hostname www.lvfuxin.com #hostname命令后跟需要成的名称
2.2、修改/etc/sysconfig/network文件中的HOSTNAME
- [root@www var]# vi /etc/sysconfig/network #vi编辑该文件 找到HOSTNAME,将该项=号后的内容修改即可
2.3、修改/etc/hosts文件中的内网Ip对应的名称以及127.0.0.1对应的名称
- [root@www var]# vi /etc/hosts #同理修改该文件中127.0.0.1 后方的名称 以及内网ip(若存在)对应的名称
三、更换ssh端口
默认的ssh端口为22,很容易被暴力破解。修改/etc/sshd/sshd_config文件即可。
- vi /etc/ssh/sshd_config #编辑ssh文件
- #找到#Port 22位置 去掉Port前的井号(井号表示注释)
- #然后将22换成你需要的端口,建议大于1000以后的端口号均可 比如8412
- #vi保存退出
- service sshd restart #重启ssh服务
四、修改yum源为阿里云的镜像源
这个没什么技术含量,直接留代码:
- #备份原先的yum源信息
- mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
- #从阿里云镜像站下载centos6的repo
- wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
- [若是centos5系列,则:]
- wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-5.repo
- #最后yum重新生成缓存
- yum makecache
文件系统的管理命令
绝对路径和相对路径
文件的路径:就是文件存放的地方,通过它系统就可以找到该文件。
绝对路径:路径的写法一定是由根目录“/”写起的。例如:“/usr/local/mysql”。
相对路径:路径的写法不是由根目录“/”写起的。例如

可以看出,现在用户的所在路径是“/home/miraclewong”,第二个命令中的“miraclewong”是相对于“/home”目录来讲的,是相对路径。命令
- 命令cd:用来变更用户所在的目录,后面只能是目录名;如果跟文件名,会报错;若后面什么都不跟,就直接进如当前用户的根目录。示例如下:

- 命令pwd:用于打印当前所在目录。“.”表示当前目录,“..”表示当前目录的上一级目录。示例如下:

- 命令mkdir:用于创建目录。mkdir是make directory的缩写。
语法:mkdir [参数] [目录名]
主要参数:
-m:用于指定要创建的目录的权限。(不常用)
-p:创建一大串级联目录,并且当创建一个已经存在的目录时不会报错。
--help:显示帮助。
--version:显示版本信息。
示例如下:

- 命令rmdir:用于删除空目录,可以是一个,也可以是多个目录(用空格分隔),该命令只能删除目录,不能删除文件。(不常用,常用rm)
- 命令rm:该命令用于在用户授权情况下,完成一个或者多个文件和目录的删除。它可以实现递归删除。大家可以通过命令“man rm”看帮助。
语法:rm [参数] [目的地址]
主要参数:
-f:强制删除文件或目录。
-i:删除既有文件或目录之前先询问用户。
-r:递归处理,将指定目录下的所有文件及子目录一并处理。等同于rmdir。
-v:显示指令的执行过程
示例如下:

- 环境变量PATH:
这里的“echo”表示输出“$PATH”的值。“PATH”前面的“$”是变量的前缀符号。

- 其他命令:
命令which:用于查找某个命令的绝对路径。
命令alias:设置命令或者文件的别名。
命令mv:用于移动目录或者文件,还有重命名的作用。
1.命令touch:
功能:若之前对应文件不存在,创建一个新文件;若存在,则修改这个文件的最后修改期限。
语法:touch [参数] [文件名]
主要参数:
-a:只更改存取时间
-c:不建立任何文件
-d<时间日期>:使用指定的日期时间
-m:只更改变动时间
-r<参考文件或目录>:把指定的文件或者目录的日期时间,统统设置成为参考文件或目录的日期时间。:
-t<时间日期>:使用指定的日期时间

2.命令cp:
功能:用于复制一个文件或多个文件,或者复制目录。
语法:cp [参数] [来源文件] [目的文件]
主要参数:
-r: 递归处理,将指定目录下的文件和子目录一起复制。
-i:覆盖现有的文件之前先询问用户。
-v:显示指令执行的过程


3.命令cat:
语法:cat [选项] [文件] ...
功能:显示全部文件内容,若果内容超过一屏,则显示最后一屏的内容。
主要参数:
-n:由1开始对所有输出的行数进行编号。
-b:和-n相似,但是对于空白的行不进行编号。
-s:当遇到有连续的两行以上的空白行时,代换为一行的空白行。

4.命令mv:功能:用于移动文件或者目录,也可以对文件或者目录进行重命名。
语法:mv [参数] [源地址] [目的地址]
主要参数:
-b:若需覆盖文件,覆盖前先备份。
-f:若目标文件和现有的文件或目录重复,则直接覆盖现有的文件或目录。
-i:覆盖现有的文件之前先询问用户。
-v:显示指令执行的过程

其他命令:
命令tac:和cat一样,不过是将文件的内容以颠倒的方式显示在屏幕上。先显示最后一行,然后显示倒数第二行。
命令more:查看一个文件的内容,后面直接根文件名。看完一屏后,按空格键(Space)可以继续看下一瓶,看完所有的内容后就会退出。提前退出:q。
命令less:查看一个文件的内容,后面直接根文件名。按空格键(Space)可以实现翻页,“j”向上移动,“k”向下移动。
技巧:在more和了less命令下,输入“/mooc”,再回车,就可以在当前文件下搜索查找“mooc”。其中,“/”是当前行向下搜索,“?”是当前行向下搜索。
命令head:显示文件的前10行,后接文件名。参数:-n,表示显示前n行。
命令tail:显示文件的后10行,后接文件名。参数:-n,表示显示前n行。Linux目录结构
Linux文件系统对文件的管理包括两方面,一方面是文件 本身,另一方面是目录管理。我所使用的是Ubuntu12.04版本的系统,其采用的是ext3文件系统,从而实现了将整个硬盘的写入动作完整地记录在磁盘的某个区域上,而且可以很轻松地挂载Windows的文件系统,以实现文件的共享。在Ubuntu中,一切资源都是以目录的形式存储,其最终的体现为一切都是文件。
Linux目录树
Linux整个文件系统以根目录(/)为最顶层目录,即根目录,系统中的所有的数据文件和硬件资源都是以文件和目录的形式出现,并且都挂载与更目录之下,整个目录结构看起来就像一棵倒挂着的树,称之为“Linux目录树”,如下图所示。整个Linux有且只有这样一棵树。

打开Ubuntu的文件浏览器,切换到根目录,实际呈现给我们的内容如下图所示。

这个目录树实际上是一个虚拟的概念,并不与任何文件、任何介质绑定,也没有容量,甚至连读写规则都没有。只有将某个介质如磁盘或者光驱挂载(mount)到这棵树的某个目录后,这个目录下面才有文件。但是,此时这个目录依旧没有容量的概念,看到的容量仅仅是这个磁盘或者光驱这个设备的容量属性,并不是文件系统的属性。
Linux目录树标准
理论上,Linux目录树的目录结构是可以随意安排的,事实上很多Linux系统开发人员也这么做,但这就带来了不同开发人员之间不统一的情况存在,很容易出现混乱。后来这样的问题得到了重视,文件层次标准(FHS,Filesystem Hierarchy Standard)就在这种情况下出台的。FHS对Linux根文件系统的基本目录结构做了比较详细的规定,尽管不是强制标准,但事实上,大部分Linux发行版都遵循这个标准。
Linux目录树下各子目录的简单说明如下表所列。

Vi/Vim概述
Linux用户经常需要对系统配置文件进行文本编辑,所以至少掌握一种文本编辑器,首选编辑器是Vi/Vim。几乎任何一个发行版都有Vi或者Vim编辑器。
Vi编辑器可以对文本进行编辑、删除、查找和替换、文本块操作等,全部操作都是在命令模式下进行的。Vi有两种工作模式:命令模式和输入模式。
Vim是Vi的加强版,比Vi更容易使用。Vi的命令几乎全部都可以在Vim上使用,安装了Vim的系统,在命令行输入vi,实际启动的是Vim编辑器。
Vim的安装
Ubuntu默认安装了Vi编辑器,但没有安装Vim,可用apt-get install命令进行安装:
miraclwong@miraclwong$ sudo apt-get install vim
启动和关闭Vim
1.启动Vim
在Linux Shell终端,输入vi或者“vi 文件名”或者“vim”以及“vim 文件名”即可启动Vim编辑器,默认进入命令模式。启动界面如下图所示。


2.退出Vim
在命令模式下输入下面的命令都可以退出Vi编辑器,回到Shell界面。

光标移动
Vi编辑器的整个文本编辑都用键盘而非鼠标来完成,传统的光标移动方式是在命令模式下输入h、j、k、l完成光标的移动,后来也支持键盘的方向键以及Page Up和Page Down翻页键了,并且这些键可在命令模式和编辑模式下使用。
总结一下,在命令模式下光标移动的方法:
上:k、Ctrl+P、↑
下:j、Ctrl+N、↓
左:h、Backspace、←
右:l、Space、→无论在编辑模式下还是命令模式下,都支持Page Up和Page Down翻页。
Vim的3种模式:一般模式、编辑模式和命令模式。
一般模式
当我们是用“vim filename”编辑一个文件的时候,默认进入该文件的一般模式。
打开文件的命令有很多,如下图所示。

在这个模式下,可以进行的操作有:上下移动光标、删除某个字符、删除某行以及复制或粘贴一行或者多行。
下面我们新建一个文件,然后使用Vim打开该文件,如下所示:


首先是复制当前目录下的文件test.txt到“/home/miraclewong/abcd”目录下,并改名为“1.txt”。然后使用Vim工具编辑它,按回车键后进入文件“1.txt”,该模式就是一般模式。该模式下,我们可以移动光标的位置,操作命令如下表所示。

在一般的模式下,我们还可以实现字符串的复制、删除、粘贴等操作。
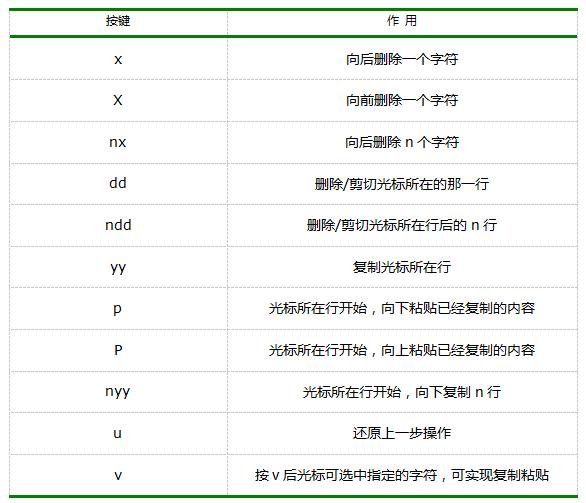
编辑模式
在一般的模式下不可以修改某一个字符,如果修改字符,只能进入编辑模式。从一般模式进入编辑模式,你只需要按i、I、a、A、o、O、r和R中的某一个键即可。当进入编辑模式,在屏幕的尾行会出现“插入”的字样。从编辑模式退回到一般模式,只需要按“Esc”键即可。具体命令如下表所示。

命令模式
在一般模式下,输入“:”或者“/”,即可以进入命令模式。在该模式下,我们可以进行搜索、保存、替换、退出、显示行号等操作。命令如下表所示。

命令模式的其他(如退出),如下表所示。

Linux下的最常见的文件通常都是.tar.gz格式的,除此之外还有其他的格式,压缩文件最好后面都加上后缀名,这样可以判断是该压缩文件是哪一种压缩工具压缩的,然后才能正确地解压。
.gz:表示由gz压缩的文件。
.bz2:表示由bzip2压缩的文件。
.tar:表示由tar打包的文件(tar没有压缩功能,只是把一个目录合并成一个文件)。
.tar.gz:可以认为是先tar打包,再由gz压缩。
.tar.bx2:可以认为是先tar打包,再由bzip2压缩。gzip压缩工具
命令格式:gzip [-d#] filename,其中“#”为1~9的数字。
-d:解压缩时使用。
-#:表示压缩等级。1为最差,9为最好,6位默认。
示例代码如下:

gzip后面直接跟文件名,表示在当前目录下压缩该文件,而源文件也会消失。解压缩文件的方法如下:

命令“gzip -d”后面跟压缩文件,表示解压缩该文件。
gzip不支持压缩目录,否则会报错。如下。

bzip2压缩工具
命令格式:bzip2 [-dz] filename
-z:表示压缩文件,也可以不加。
-d:表示解压缩文件。

bzip2又不能压缩目录,否则会报错。如下。

tar压缩工具
tar本身是一个打包工具,可以把目录打包成为一个文件,方面复制和移动。
命令格式:tar [-dzjxcvf] filename
-z:表示同时使用gzip压缩。
-j:
-x:表示解包或者解压缩。
-t:表示查看tar包里的文件。
-c:表示建立一个tar包或者压缩文件包。
-v:表示可视化。
-f:后面跟文件名,表示压缩后的文件名为filename,或者解压缩后的文件名为filename。
(注:在多个参数的情况下,f放在最后面)

上例子中有一个“!$”,他表示上一条命令的最后一个参数。指的是“test111/test2.txt”。tar命令不仅可以dabao目录也可以打包文件,打包时可以不加-v选项,表示不可视化。

打包或者解包的时候,原来的文件是不会删除的,而且它会覆盖当前已经存在的文件或目录。下面我们先删除test111目录,再来解包test.tar。

打包的同时使用gzip压缩
tar命令可以在打包的同时直接压缩。支持gzip和bzip2两种格式。使用-z选项可以压缩成gzip格式的文件。

使用-tf可以查看包或者压缩包的文件列表,示例如下:

使用-zxvf可以解压.tar.gz的压缩包,示例如下:

打包的同时使用bzip2压缩
使用-j选项可以压缩成bzip2格式的文件。

使用-tf可以查看包或者压缩包的文件列表,示例如下:

使用-jxvf可以解压.tar.bz2的压缩包,示例如下:

使用zip压缩
zip压缩在windows和Linux下都很常见,可以压缩目录和文件,压缩目录时,需要指定目录下的文件,示例代码:

解压zip格式的文件并不是用zip命令,而是unzip命令,如下所示:

认识/etc/passwd和/etc/shadow
这两个目录在Linux中的重要性不言而喻,和你的登录有关。
先看看/etc/passwd,示例代码如下:

‘/etc/passwd’ 由 ‘:’ 分割成7个字段,每个字段的具体含义是:
(1)用户名(如第一行中的root就是用户名),代表用户账号的字符串。用户名字符可以是大小写字母、数字、减号(不能出现在首位)、点以及下划线,其他字符不合法。
(2)存放的就是该账号的口令。
(3)这个数字代表用户标识号,也叫做uid。系统识别用户身份就是通过这个数字来的,0就是root。通常uid的取值范围是0~65535,0是超级用户(root)的标识号,1~499由系统保留,作为管理账号,普通用户的标识号从500开始。
(4)表示组标识号,也叫做gid。这个字段对应着/etc/group 中的一条记录,其实/etc/group和/etc/passwd基本上类似。
(5)注释说明,该字段没有实际意义,通常记录该用户的一些属性。
(6)用户的家目录,当用户登录时就处在这个目录下。root的家目录是/root,普通用户的家目录则为/home/username,这个字段是可以自定义的。
(7)shell,用户登录后要启动一个进程,用来将用户下达的指令传给内核,这就是shell。
然后是/etc/shadow这个文件,和/etc/passwd类似,用 ‘:’ 分割成9个字段。

(1)用户名,跟/etc/passwd对应。
(2)用户密码,这个才是该账号的真正的密码,已经加密过。
(3)上次更改密码的日期,计算得来的,距离1970年1月1日到上次更改密码的日期。
(4)要过多少天才可以更改密码,默认是0,即不限制。
(5)密码多少天后到期。即在多少天内必须更改密码,默认是99999,可以理解为永远不需要改。
(6)密码到期前的警告期限。
(7)账号失效期限。
(8)账号的生命周期,跟第三段一样,是按距离1970年1月1日多少天算的。它表示的含义是,账号在这个日期前可以使用,到期后账号作废。
(9)作为保留用的,没有什么意义。
新增/删除用户和用户组
新增一个组
语法 : groupadd [-g GID] groupname

不加 “-g” 选项则按照系统默认的gid创建组,跟用户一样,gid也是从500开始的。
“-g” 选项可以自定义gid.删除组
命令 : groupdel

有一种情况不能删除组,这是因为miraclewong组中包含miraclewong账户,只有删除miraclewong账户后才可以删除该组。增加账户
语法 : useradd [-u UID] [-g GID] [-d HOME] [-M] [-s]
‘-u’ 自定义UID
‘-g’ 使其属于已经存在的某个组,后面可以跟组id, 也可以跟组名
‘-d’ 自定义用户的家目录
‘-M’ 不建立家目录
‘-s’ 自定义shell‘useradd’ 不加任何选项直接跟用户名,则会创建一个跟用户名同样名字的组。

‘-g’ 选项后面跟一个不存在的gid会报错,提示该组不存在。刚刚上面说过 ‘-M’ 选项加上后则不建立用户家目录,但是在/etc/passwd文件中仍然有这个字段。但是您使用 ls /home/user11 查看一下会提示该目录不存在。所以 ‘-M’ 选项的作用只是不创建那个目录。

删除账户的命令
语法 : userdel [-r] username
‘-r’ 选项的作用只有一个,就是删除账户的时候连带账户的家目录一起删除。
其他的命令:
passwd:修改密码
mkpasswd:生成密码
chfn:更改用户的finger
su:用于切换用户,切换到root用户。Linux用户管理
查看用户
直接使用whoami命令可以查看当前登录用户的用户名,此外还有who命令可以查看更多详细的信息。
创建用户
root权限,是系统权限的一种。root是Linux和unix系统中的超级管理员用户帐户,该帐户拥有整个系统至高无上的权力,所有对象他都可以操作,所以很多黑客在入侵系统的时候,都要把权限提升到root权限。root账户就相当于Linux的“上帝”。
一般登录系统时都是以普通账户的身份登录的(即“凡人”)。如果要添加一个用户(上帝造人),那么需要“借用”一下上帝的权力,即使用sudo命令。使用这个命令有两个大前提,一是你要知道当前登录用户的密码,二是当前用户必须在sudo用户组。
- sudo adduser <user>:创建一个新用户(默认会自动创建一个同名的用户组),同时会在/home目录下创建一个对应的文件夹
- su -l <user>:切换登录用户
- exit(或CTRL+D):退出当前登录用户
用户组
在linux里面每个用户都有一个归属(用户组),用户组简单地理解就是一组用户的集合,它们共享一些资源和权限,同时拥有私有资源。一个用户可以属于多个用户组。
- groups <user>:查看user属于哪个用户组。输出内容冒号之前表示用户,之后表示该用户所属的用户组。
- cat /etc/group |sort:输出如下所示。/etc/group文件内容包括用户组(Group)、用户组口令、GID及该用户组所包含的用户(User),每个用户组一条记录。格式为group_name:password:GID:user_list,其中密码字段为表示密码不可见。
daemon::1:root
kmem::2:root
sys::3:root …… - usermod -G <group> <user>:为用户添加用户组(需要root权限)。可以用这个命令把用户加入sudo组,这样这个用户就能借用root权限。
- deluser <user> --remove-home:删除用户(需要root权限)。--remove-home参数表示连带删除home目录下的文件夹。
Linux文件权限
ls命令可以列出当前文件夹的文件,附带参数说明如下:
- -l:以较详细的格式列出文件(如下所示)
- -A:显示除了.(当前目录),..上一级目录之外的包含隐藏文件的所有文件(Linux下以.开头的文件为隐藏文件)
- -dl <dir>:查看某一个目录的完整属性,而不是显示目录里面的文件属性
-
-sSh:小s为显示文件大小,大S为按文件大小排序,h显示所有文件大小,并以普通人类能看懂的方式呈现
drwxr-xr-x@ 11 root wheel 374 1 25 22:23 usr
从左到右依次是:文件类型和权限,链接数,所有者,所属用户组,文件大小,最后修改时间,文件名。
1、文件类型和权限(drwxr-xr-x@)
第1位d表示文件类型。其余文件类型有:
- d:目录
- l:软链接
- b:块设备
- c:字符设备
- s:Socket
- p:管道
- -:普通文件
后面9位每3个1组,分为3组,分别是拥有者权限、所属用户组权限、其他用户权限,字符的意义是:
- r:允许读权限,比如可以使用cat <file name>之类的命令来读取某个文件的内容
- w:允许写权限,表示你可以编辑和修改某个文件
- x:允许执行权限,通常指可以运行的二进制程序文件或者脚本文件。Linux上不是通过文件后缀名来区分文件的类型。注意:一个目录要同时具有读权限和执行权限才可以打开,而一个目录要有写权限才允许在其中创建其它文件,这是因为目录文件实际保存着该目录里面的文件的列表等信息
2、链接数
链接到该文件所在的inode结点的文件名数目(关于这个概念涉及到linux文件系统的相关概念知识,自行查阅)
3、文件大小
以inode结点大小为单位来表示的文件大小,可以给ls加上-h参数(表示,这才是给人看的)来更直观的查看文件的大小
使用chown <param> <file>命令可以修改文件file权限(需要root权限)。其中参数param可以是二进制形式,也可以是加减赋值操作形式。
二进制形式如chown 755 some_file,参数中3个数字分别表示拥有者,所属用户组,其他用户的权限值。权限值的计算由r、w、x决定,有权限为1,无权限为0,由二进制加权所得,如7代表rwx,5代表r-x。
加减赋值操作形式如chmod go-rw some_file,’g’’o’还有’u’,分别表示group,others,user,’+’,’-‘就分别表示增加和去掉相应的权限
磁盘管理
关于du和df之类的命令这里就不介绍了,这里主要介绍的是如何添加磁盘和分区、如何添加swap分区以及磁盘配额的内容。
添加磁盘或分区
总共分为4大步。
-
fdisk,划分分区。
- fdisk -l /dev/sdb,查看磁盘分区情况
- fdisk /dev/sdb,对磁盘进行操作,见下面基本操作
- m 帮助
- p 打印分区表
- n 增加新的分区
- t 改变分区文件系统ID
- L 查看文件系统ID
- d 删除分区
- w 保存分区表
- q 退出(不保存)
-
mkfs,创建文件系统。
- mkfs.ext3 /dev/sdb 将分区格式化为ext3文件系统类型
-
mount,挂载分区。
- mount /dev/sdb /mnt 将sdb分区挂载到mnt目录下
-
df -h 查看系统磁盘,可以看到mnt分区

注意:我这是在虚拟机中测试的 -
写入配置文件,编辑/etc/fstab。文件的内容信息格式如下;
物理分区名 挂载点 文件系统 缺省设置 是否检测(1:检测;2:检测) 检测顺序(0:是否检测;1:优先检测;2:期后检测) LABEL=1 / ext3 default 1 2 /dev/sda1 / ext3 default 0 0 /dev/sdb1 /web ext3 default 1 1 - e2label /dev/sdb1 检测是否有卷标
- e2label /dev/sdb1 name添加卷标
添加Swap分区
两种方法扩大swap分区
- 新建磁盘,分swap分区
- 在已有磁盘上使用swapfile文件增大swap分区
第一种方法可以根据上面增加分区的步骤一样进行操作,这里主要记录一下使用swapfile文件增大swap分区的步骤。
- mkdir /var/swap 新建swap目录
- chmod 700 /var/swap 设置目录权限
- dd if=/dev/zero of=/var/swap/file.swp bs=1024 count=3000 创建swp文件
- mkswap /var/swap/file.swp 使文件可用
- vim /etc/fstab 写入配置文件
- free 查看分区
- swapon /var/swap/file.swp 启用swap分区
- free 再次查看分区

之前和之后的swap分区大小
磁盘配额(针对分区)
磁盘配额就是管理员可以为用户所能使用的磁盘空间进行配额限制,每一用户只能使用最大配额范围内的磁盘空间。
可分为三类限制:
- 软限制(Soft limit):定义用户可以占用的磁盘空间数。当用户超过该限制后会收到已超过配额的警告。
- 硬限制(Hard limit):当用户试图将文件存放在其已经超过该限制目录时,报告文件系统错误。
- 宽限制(Grace period):定义用户在软限制下可以使用其文件系统的期限。
操作步骤
- 开启分区配额功能,vim /etc/fstab,编辑配置文件,在挂载属性上加上标志userquota或grpquota,然后重新挂载mount -o remount /home,或重新启动系统sudo init 6;
- 建立配额数据库,quotacheck -Cvuga,会生成aquota.user、aquota.group两文件。
- 启动配额功能,quotaon 分区名称;关闭配额功能,quotaoff 分区名称;
- 编辑配额
- edquota username 编辑用户配额
- edquota -g groupname 编辑用户组配额
- edquota -t 设置宽期限 设置宽期限
- edquota -p 模版用户 复制用户1 复制用户2
- quota username 查看用户的配额使用情况
- repquota -a 管理员查看配额信息
备份
备份几乎是Linux系统运维最频繁的工作了,不过大部分情况下,都是通过自动化脚本进行自动备份。
备份策略
- 完全备份
- 增量备份:通常是这种情况
备份分类
- 系统备份:/etc , /boot , /usr/local , /var , /log...
- 用户备份:/home
备份相关命令
其实主要就是通过cp和tar命令
- cp -Rpu 复制文件
- -p 保持文件原本属性
- -u 增量备份
- -R 循环复制
- scp 远程备份,类似cp命令
- tar -zcf /backup/sys.tar.gz /etc /boot 备份/etc , /boot
- tar -ztf /backup/sys.tar.gz 查看备份包中的文件(不解包)
- tar -zxf /backup/sys.tar.gz 还原备份目录,其实就是解包
- tar -zxf /backup/sys.tar.gz -C ./backup 解压到指定目录backup下
- tar -zxf /backup/sys.tar.gz etc/group 恢复指定文件
- tar -rf /backup/sys.tar /etc/file1 /etc/file2 追加文件到备份包中
- tar -uf /backup/sys.tar /etc/file 将修改过的文件做备份
-
- netstat 命令
它主要的用法和详解!
(netstat -na 命令),本文主要是说Linux下的netstat工具,然后详细说明一下各种网络连接状态。
netstat -nat |awk ‘{print $6}’|sort|uniq -c|sort -nr
1.netstat命令详解
其实我常用的是 netstat -tnl | grep 443 (查看443端口是否被占用),如果有当前是root用户,我喜欢用netstat -pnl | grep 443 (还可显示出占用本机443端口的进程PID)。
netstat
功能说明:显示网络状态。
语 法:netstat [-acCeFghilMnNoprstuvVwx] [-A<网络类型>][--ip]
补充说明:利用netstat指令可让你得知整个Linux系统的网络情况。
参 数:
-a 或–all 显示所有连线中的Socket。
-A <网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。
-c 或–continuous 持续列出网络状态。
-C 或–cache 显示路由器配置的快取信息。
-e 或–extend 显示网络其他相关信息。
-F 或 –fib 显示FIB。
-g 或–groups 显示多重广播功能群组组员名单。
-h 或–help 在线帮助。
-i 或–interfaces 显示网络界面信息表单。
-l 或–listening 显示监控中的服务器的Socket。
-M 或–masquerade 显示伪装的网络连线。
-n 或–numeric 直接使用IP地址,而不通过域名服务器。
-N 或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。
-o 或–timers 显示计时器。
-p 或–programs 显示正在使用Socket的程序识别码和程序名称。
-r 或–route 显示 Routing Table。
-s 或–statistice 显示网络工作信息统计表。
-t 或–tcp 显示TCP 传输协议的连线状况。
-u或–udp 显示UDP传输协议的连线状况。
-v或–verbose 显示指令执行过程。
-V 或–version 显示版本信息。
-w或–raw 显示RAW传输协议的连线状况。
-x或–unix 此参数的效果和指定”-A unix”参数相同。
–ip或–inet 此参数的效果和指定”-A inet”参数相同。
2.网络连接状态详解
共有12中可能的状态,前面11种是按照TCP连接建立的三次握手和TCP连接断开的四次挥手过程来描述的。
1)、LISTEN:首先服务端需要打开一个socket进行监听,状态为LISTEN./* The socket is listening for incoming connections. 侦听来自远方TCP端口的连接请求 */
2)、 SYN_SENT:客户端通过应用程序调用connect进行active open.于是客户端tcp发送一个SYN以请求建立一个连接.之后状态置为SYN_SENT./*The socket is actively attempting to establish a connection. 在发送连接请求后等待匹配的连接请求 */
3)、 SYN_RECV:服务端应发出ACK确认客户端的 SYN,同时自己向客户端发送一个SYN. 之后状态置为SYN_RECV/* A connection request has been received from the network. 在收到和发送一个连接请求后等待对连接请求的确认 */
4)、ESTABLISHED: 代表一个打开的连接,双方可以进行或已经在数据交互了。/* The socket has an established connection. 代表一个打开的连接,数据可以传送给用户 */
5)、 FIN_WAIT1:主动关闭(active close)端应用程序调用close,于是其TCP发出FIN请求主动关闭连接,之后进入FIN_WAIT1状态./* The socket is closed, and the connection is shutting down. 等待远程TCP的连接中断请求,或先前的连接中断请求的确认 */
6)、CLOSE_WAIT:被动关闭(passive close)端TCP接到FIN后,就发出ACK以回应FIN请求(它的接收也作为文件结束符传递给上层应用程序),并进入CLOSE_WAIT./* The remote end has shut down, waiting for the socket to close. 等待从本地用户发来的连接中断请求 */
7)、FIN_WAIT2:主动关闭端接到ACK后,就进入了 FIN-WAIT-2 ./* Connection is closed, and the socket is waiting for a shutdown from the remote end. 从远程TCP等待连接中断请求 */
8)、LAST_ACK:被动关闭端一段时间后,接收到文件结束符的应用程 序将调用CLOSE关闭连接。这导致它的TCP也发送一个 FIN,等待对方的ACK.就进入了LAST-ACK ./* The remote end has shut down, and the socket is closed. Waiting for acknowledgement. 等待原来发向远程TCP的连接中断请求的确认 */
9)、TIME_WAIT:在主动关闭端接收到FIN后,TCP 就发送ACK包,并进入TIME-WAIT状态。/* The socket is waiting after close to handle packets still in the network.等待足够的时间以确保远程TCP接收到连接中断请求的确认 */
10)、CLOSING: 比较少见./* Both sockets are shut down but we still don’t have all our data sent. 等待远程TCP对连接中断的确认 */
11)、CLOSED: 被动关闭端在接受到ACK包后,就进入了closed的状态。连接结束./* The socket is not being used. 没有任何连接状态 */
12)、UNKNOWN: 未知的Socket状态。/* The state of the socket is unknown. */
SYN: (同步序列编号,Synchronize Sequence Numbers)该标志仅在三次握手建立TCP连接时有效。表示一个新的TCP连接请求。
ACK: (确认编号,Acknowledgement Number)是对TCP请求的确认标志,同时提示对端系统已经成功接收所有数据。
FIN: (结束标志,FINish)用来结束一个TCP回话.但对应端口仍处于开放状态,准备接收后续数据。
PS: 在windows下有个小工具挺好的,TCPView is a Windows program that will show you detailed listings of all TCP and UDP endpoints on your system, including the local and remote addresses and state of TCP connections.见 http://technet.microsoft.com/en-us/sysinternals/bb897437 ; 当然如果要详细分析数据包,可选用sniffer、Wireshark等更强大的工具。
参考资料:
http://linux.sheup.com/linux/4/31225.html
http://hi.baidu.com/mqbest_come_on/blog/item/18526dcef73d791a00e928e5.html
http://www.daxigua.com/archives/1355
系统连接状态篇:
1.查看TCP连接状态
netstat -nat |awk ‘{print $6}’|sort|uniq -c|sort -rn
netstat -n | awk ‘/^tcp/ {++S[$NF]};END {for(a in S) print a, S[a]}’ 或
netstat -n | awk ‘/^tcp/ {++state[$NF]}; END {for(key in state) print key,”\t”,state[key]}’
netstat -n | awk ‘/^tcp/ {++arr[$NF]};END {for(k in arr) print k,”\t”,arr[k]}’
netstat -n |awk ‘/^tcp/ {print $NF}’|sort|uniq -c|sort -rn
netstat -ant | awk ‘{print $NF}’ | grep -v ‘[a-z]‘ | sort | uniq -c
2.查找请求数请20个IP(常用于查找攻来源):
netstat -anlp|grep 80|grep tcp|awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -n20
netstat -ant |awk ‘/:80/{split($5,ip,”:”);++A[ip[1]]}END{for(i in A) print A[i],i}’ |sort -rn|head -n20
3.用tcpdump嗅探80端口的访问看看谁最高
tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F”.” ‘{print $1″.”$2″.”$3″.”$4}’ | sort | uniq -c | sort -nr |head -20
4.查找较多time_wait连接
netstat -n|grep TIME_WAIT|awk ‘{print $5}’|sort|uniq -c|sort -rn|head -n20
5.找查较多的SYN连接
netstat -an | grep SYN | awk ‘{print $5}’ | awk -F: ‘{print $1}’ | sort | uniq -c | sort -nr | more
6.根据端口列进程
netstat -ntlp | grep 80 | awk ‘{print $7}’ | cut -d/ -f1
网站日志分析篇1(Apache):
1.获得访问前10位的ip地址
cat access.log|awk ‘{print $1}’|sort|uniq -c|sort -nr|head -10
cat access.log|awk ‘{counts[$(11)]+=1}; END {for(url in counts) print counts[url], url}’
2.访问次数最多的文件或页面,取前20
cat access.log|awk ‘{print $11}’|sort|uniq -c|sort -nr|head -20
3.列出传输最大的几个exe文件(分析下载站的时候常用)
cat access.log |awk ‘($7~/\.exe/){print $10 ” ” $1 ” ” $4 ” ” $7}’|sort -nr|head -20
4.列出输出大于200000byte(约200kb)的exe文件以及对应文件发生次数
cat access.log |awk ‘($10 > 200000 && $7~/\.exe/){print $7}’|sort -n|uniq -c|sort -nr|head -100
5.如果日志最后一列记录的是页面文件传输时间,则有列出到客户端最耗时的页面
cat access.log |awk ‘($7~/\.php/){print $NF ” ” $1 ” ” $4 ” ” $7}’|sort -nr|head -100
6.列出最最耗时的页面(超过60秒的)的以及对应页面发生次数
cat access.log |awk ‘($NF > 60 && $7~/\.php/){print $7}’|sort -n|uniq -c|sort -nr|head -100
7.列出传输时间超过 30 秒的文件
cat access.log |awk ‘($NF > 30){print $7}’|sort -n|uniq -c|sort -nr|head -20
8.统计网站流量(G)
cat access.log |awk ‘{sum+=$10} END {print sum/1024/1024/1024}’
9.统计404的连接
awk ‘($9 ~/404/)’ access.log | awk ‘{print $9,$7}’ | sort
10. 统计http status.
cat access.log |awk ‘{counts[$(9)]+=1}; END {for(code in counts) print code, counts[code]}'
cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn
10.蜘蛛分析
查看是哪些蜘蛛在抓取内容。
/usr/sbin/tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider'
网站日分析2(Squid篇)
2.按域统计流量
zcat squid_access.log.tar.gz| awk '{print $10,$7}' |awk 'BEGIN{FS="[ /]"}{trfc[$4]+=$1}END{for(domain in trfc){printf "%s\t%d\n",domain,trfc[domain]}}'
效率更高的perl版本请到此下载:http://docs.linuxtone.org/soft/tools/tr.pl
数据库篇
1.查看数据库执行的sql
/usr/sbin/tcpdump -i eth0 -s 0 -l -w - dst port 3306 | strings | egrep -i 'SELECT|UPDATE|DELETE|INSERT|SET|COMMIT|ROLLBACK|CREATE|DROP|ALTER|CALL'
系统Debug分析篇
1.调试命令
strace -p pid
2.跟踪指定进程的PID
gdb -p pid
详细访问linuxtone.org
source url:http://linuxsjun.blog.163.com/blog/static/35771271201141710521644/
- linux下解决端口占用
有时候关闭软件后,后台进程死掉,导致端口被占用。下面以JBoss端口8083被占用为例,列出详细解决过程。
解决方法:
1.查找被占用的端口
- netstat -tln
- netstat -tln | grep 8083
netstat -tln 查看端口使用情况,而netstat -tln | grep 8083 则是只查看端口8083的使用情况
2.查看端口属于哪个程序?端口被哪个进程占用
- lsof -i :8083
3.杀掉占用端口的进程
- kill -9 进程id
AWK介绍
如果要格式化报文或从一个大的文本文件中抽取数据包,那么awk可以完成这些任务。它在文本浏览和数据的熟练使用上性能优异。
整体来说,awk是所有shell过滤工具中最难掌握的,不知道为什么,也许是其复杂的语法或含义不明确的错误提示信息。在学习awk语言过程中,就会慢慢掌握诸如Bailing out 和awk:cmd.Line:等错误信息。可以说awk是一种自解释的编程语言,之所以要在shell中使用awk是因为awk本身是学习的好例子,但结合awk与其他工具诸如grep和sed,将会使shell编程更加容易。
本章没有讲述awk的全部特性,也不涉及awk的深层次编程,(这些可以在专门讲述awk的书籍中找到)。本章仅注重于讲述使用awk执行行操作及怎样从文本文件和字符串中抽取信息。
本章内容有:
? 抽取域。
? 匹配正则表达式。
? 比较域。
? 向awk传递参数。
? 基本的awk行操作和脚本。
本书几乎所有包含awk命令的脚本都结合了sed和grep,以从文本文件和字符串中抽取信息。为获得所需信息,文本必须格式化,意即用域分隔符划分抽取域,分隔符可能是任意
符,在以后讲述awk时再详细讨论。
awk以发展这种语言的人Aho.Weninberger和Kernigham命名。还有nawk和gawk,它们扩展了文本特性,但本章不予讨论。
awk语言的最基本功能是在文件或字符串中基于指定规则浏览和抽取信息。awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
9.1 调用awk
有三种方式调用awk,第一种是命令行方式,如:
awk [-F field-separator] ’commands’ input-file(s)
这里,commands是真正的awk命令。本章将经常使用这种方法。
上面例子中,[-F域分隔符]是可选的,因为awk使用空格作为缺省的域分隔符,因此如果要浏览域间有空格的文本,不必指定这个选项,但如果要浏览诸如passwd文件,此文件各域以冒号作为分隔符,则必须指明-F选项,如:
awk -F: ’commands’ input-file
第二种方法是将所有awk命令插入一个文件,并使awk程序可执行,然后用awk命令解释器作为脚本的首行,以便通过键入脚本名称来调用它。
第三种方式是将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-file(s)
-f选项指明在文件awk-script-file中的awk脚本, input-file(s)是使用awk进行浏览的文件名。
9.2 awk脚本
在命令中调用awk时,awk脚本由各种操作和模式组成。
如果设置了-F选项,则awk每次读一条记录或一行,并使用指定的分隔符分隔指定域,但如果未设置-F选项,awk假定空格为域分隔符,并保持这个设置直到发现一新行。当新行出现时,awk命令获悉已读完整条记录,然后在下一个记录启动读命令,这个读进程将持续到文件尾或文件不再存在。
参照表9-1,awk每次在文件中读一行,找到域分隔符(这里是符号#),设置其为域n,直至一新行(这里是缺省记录分隔符),然后,划分这一行作为一条记录,接着awk再次启动下一行读进程。
表9-1 awk读文件记录的方式
域1 分隔符 域2 分隔符 域3 分隔符 域4及换行
P.Bunny(记录1) # 02/99 # 48 # Yellow\n
J.Troll(记录2) # 07/99 # 4842 # Brown-3\n
9.2.1 模式和动作
任何awk语句都由模式和动作组成。在一个awk脚本中可能有许多语句。模式部分决定动作语句何时触发及触发事件。处理即对数据进行的操作。如果省略模式部分,动作将时刻保持执行状态。
模式可以是任何条件语句或复合语句或正则表达式。模式包括两个特殊字段BEGIN和END。使用BEGIN语句设置计数和打印头。BEGIN语句使用在任何文本浏览动作之前,之后文本浏览动作依据输入文件开始执行。END语句用来在awk完成文本浏览动作后打印输出文本总数和结尾状态标志。如果不特别指明模式,awk总是匹配或打印行数。
实际动作在大括号{}内指明。动作大多数用来打印,但是还有些更长的代码诸如if和循环(looping)语句及循环退出结构。如果不指明采取动作,awk将打印出所有浏览出来的记录。
下面将深入讲解这些模式和动作。
9.2.2 域和记录
awk执行时,其浏览域标记为$1,$2...$n。这种方法称为域标识。使用这些域标识将更容易对域进行进一步处理。
使用$1,$3表示参照第1和第3域,注意这里用逗号做域分隔。如果希望打印一个有5个域的记录的所有域,不必指明$1,$2,$3,$4,$5,可使用$0,意即所有域。awk浏览时,到达一新行,即假定到达包含域的记录末尾,然后执行新记录下一行的读动作,并重新设置域分隔。
注意执行时不要混淆符号$和shell提示符$,它们是不同的。
为打印一个域或所有域,使用print命令。这是一个awk动作(动作语法用圆括号括起来)。
1.抽取域
真正执行前看几个例子,现有一文本文件grade.txt,记录了一个称为柔道数据库的行信息。
$ pg grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
此文本文件有7个域,即(1)名字、(2)升段日期、(3)学生序号、(4)腰带级别、(5)年龄、(6)目前比赛积分、(7)比赛最高分。
因为域间使用空格作为域分隔符,故不必用- F选项划分域,现浏览文件并导出一些数据。
在例子中为了利于显示,将空格加宽使各域看得更清晰。
2.保存awk输出
有两种方式保存shell提示符下awk脚本的输出。最简单的方式是使用输出重定向符号>文件名,下面的例子重定向输出到文件wow。
$ awk ’{print $0}’ grade.txt > wow
使用这种方法要注意,显示屏上不会显示输出结果。因为它直接输出到文件。只有在保证输出结果正确时才会使用这种方法。它也会重写硬盘上同名数据。
第二种方法是使用tee命令,在输出到文件的同时输出到屏幕。在测试输出结果正确与否时多使用这种方法。例如输出重定向到文件delete_me_and_die,同时输出到屏幕。使用这种方法,在awk命令结尾写入| tee delete_me_and_die。
$ awk ’{print $0}’ grade.txt | tee delete_me_and_die
3.使用标准输入
在深入讲解这一章之前,先对awk脚本的输入方法简要介绍一下。实际上任何脚本都是从标准输入中接受输入的。为运行本章脚本,使用awk脚本输入文件格式,例如:
$ belts.awk grade_student.txt
也可替代使用下述格式:
使用重定向方法:
$ belts.awk < grade2.txt
或管道方法:
$ grade2.txt | belts.awk
4. 打印所有记录
$ awk ’{print $0}’ grade.txt
awk读每一条记录。因为没有模式部分,只有动作部分{print $0}(打印所有记录),这个动作必须用花括号括起来。上述命令打印整个文件。
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
5.打印单独记录
假定只打印学生名字和腰带级别,通过查看域所在列,可知为field-1和field-4,因此可以使用$1和$4,但不要忘了加逗号以分隔域。
$ awk ’{print $1,$4}’ grade.txt
M.Tansley Green
J.Lulu green
P.Bunny Yellow
J.Troll Brown-3
L.Tansley Brown-2
6.打印报告头
上述命令输出在名字和腰带级别之间用一些空格使之更容易划分,也可以在域间使用tab键加以划分。为加入tab键,使用tab键速记引用符\t,后面将对速记引用加以详细讨论。也可以为输出文本加入信息头。本例中加入name和belt及下划线。下划线使用\n,强迫启动新行,并在\n下一行启动打印文本操作。打印信息头放置在BEGIN模式部分,因为打印信息头被界定为一个动作,必须用大括号括起来。在awk查看第一条记录前,信息头被打印。
$awk 'BEGIN {print "Name Belt\n--------------------------------"} {print $1"\t"$4}' grade.txt
Name Belt
--------------------------------
M.Tansley Green
J.Lulu green
P.Bunny Yellow
J.Troll Brown-3
L.Tansley Brown-2
7.打印信息尾
如果在末行加入end of report信息,可使用END语句。END语句在所有文本处理动作执行完之后才被执行。END语句在脚本中的位置放置在主要动作之后。下面简单打印头信息并告之查询动作完成。
$ awk 'BEGIN {print "Name\n-------"} {print $1} END {print "end-of-report"}' grade.txt
Name
-------
M.Tansley
J.Lulu
P.Bunny
J.Troll
L.Tansley
end-of-report
8.awk错误信息提示
几乎可以肯定,在使用awk时,将会在命令中碰到一些错误。awk将试图打印错误行,但由于大部分命令都只在一行,因此帮助不大。
系统给出的显示错误信息提示可读性不好。使用上述例子,如果丢了一个双引号,a w k将返回:
$ awk 'BEGIN {print "Name\n-------} {print $1} END {print "end-of-report"}' grade.txt
awk: cmd. line:1: BEGIN {print "Name\n-------} {print $1} END {print "end-of-report"}
awk: cmd. line:1: ^ unterminated string
当第一次使用awk时,可能被错误信息搅得不知所措,但通过长时间和不断的学习,可总结出以下规则。在碰到awk错误时,可相应查找:
? 确保整个awk命令用单引号括起来。
? 确保命令内所有引号成对出现。
? 确保用花括号括起动作语句,用圆括号括起条件语句。
? 可能忘记使用花括号,也许你认为没有必要,但awk不这样认为,将按之解释语法。
如果查询文件不存在,将得到下述错误信息:
$ awk 'END {print NR}' grades.txt
awk: cmd. line:2: fatal: cannot open file `grades.txt' for reading (No such file or directory)
9.awk 键盘输入
如果在命令行并没有输入文件grade.txt,将会怎样?
$ awk 'BEGIN {print "Name Belt\n------------------------------------"} {print $1"\t"$4}'
Name Belt
------------------------------------
>
BEGIN部分打印了文件头,但awk最终停止操作并等待,并没有返回shell提示符。这是因为awk期望获得键盘输入。因为没有给出输入文件,awk假定下面将会给出。如果愿意,顺序输入相关文本,并在输入完成后敲<Ctrl-D>键。如果敲入了正确的域分隔符,awk会像第一个例子一样正常处理文本。这种处理并不常用,因为它大多应用于大量的打印稿。
9.2.3 awk中正则表达式及其操作
在grep一章中,有许多例子用到正则表达式,这里将不使用同样的例子,但可以使用条件操作讲述awk中正则表达式的用法。
这里正则表达式用斜线括起来。例如,在文本文件中查询字符串Green,使用/Green/可以查出单词Green的出现情况。
9.2.4 元字符
这里是awk中正则表达式匹配操作中经常用到的字符,详细情况请参阅本书第7章正则表达式概述。
\^$.[]|()*+?
这里有两个字符第7章没有讲到,因为它们只适用于awk而不适用于grep或sed。它们是:
+ 使用+匹配一个或多个字符。
? 匹配模式出现频率。例如使用/XY?Z/匹配XYZ或YZ。
9.2.5 条件操作符
表9-2给出awk条件操作符,后面将给出其用法。
表9-2 awk条件操作符
操作符 描述 操作符 描述
< 小于 >= 大于等于
<= 小于等于 ~ 匹配正则表达式
== 等于 !~ 不匹配正则表达式
!= 不等于
1.匹配
为使一域号匹配正则表达式,使用符号‘~’后紧跟正则表达式,也可以用if语句。awk中if后面的条件用()括起来。
观察文件grade.txt,如果只要打印brown腰带级别可知其所在域为field-4,这样可以写出表达式{if($4~/brown/) print }意即如果field-4包含Brown,打印它。如果条件满足,则打印匹配记录行。可以编写下面脚本,因为这是一个动作,必须用花括号{}括起来。
$ awk '{if($4~/Brown/) print $0}' grade.txt
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
匹配记录找到时,如果不特别声明,awk缺省打印整条记录。使用if语句开始有点难,但不要着急,因为有许多方法可以跳过它,并仍保持同样结果。下面例子意即如果记录包含模式Brown,就打印它:
$ awk '$0 ~/Brown/' grade.txt
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
2.精确匹配
假定要使字符串精确匹配,比如说查看学生序号48,文件中有许多学生序号包含48,如果在field-3中查询序号48,awk将返回所有序号带48的记录:
$ awk '{if($3~/48/) print $0}' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
为精确匹配48,使用等号==,并用单引号括起条件。例如$3== "48 ",这样确保只有48序号得以匹配,其余则不行。
$ awk '$3=="48" {print $0}' grade.txt
P.Bunny 02/99 48 Yellow 12 35 28
3.不匹配
有时要浏览信息并抽取不匹配操作的记录,与~相反的符号是!~,意即不匹配。像原来使用查询brown腰带级别的匹配操作一样,现在看看不匹配情况。表达式$0!~/brown/,意即查询不包含模式brown腰带级别的记录并打印它。
注意,缺省情况下,awk将打印所有匹配记录,因此这里不必加入动作部分。
$ awk '$0!~/Brown/' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
可以只对field-4进行不匹配操作,方法如下:
$ awk '{if($4!~/Brown/) print $0}' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
如果只使用命令awk '$4!="Brown" {print $0}' grade.txt,将返回错误结果,因为用引号括起了Brown,将只匹配Brown而不匹配Brown-2和Brown-3,当然,如果想要查询非Brown-2的腰带级别,可做如下操作:
awk '$4!="Brown-2" {print $0}' grade.txt
4.小于
看看哪些学生可以获得升段机会。测试这一点即判断目前级别分field-6是否小于最高分field-7,在输出结果中,加入这一改动很容易。
$ awk '{if($6<$7) print $1" Try better at the next comp"}' grade.txt
M.Tansley Try better at the next comp
J.Lulu Try better at the next comp
5.小于等于
对比小于,小于等于只在操作符上做些小改动,满足此条件的记录也包括上面例子中的输出情况。
$ awk '{if($6<=$7) print $1}' grade.txt
M.Tansley
J.Lulu
J.Troll
6.大于
大于符号大家都熟知,请看例子:
$ awk '{if($6>$7) print $1}' grade.txt
P.Bunny
L.Tansley
希望读者已经掌握了操作符的基本用法。
7.设置大小写
为查询大小写信息,可使用[]符号。在测试正则表达式时提到可匹配[]内任意字符或单词,因此若查询文件中级别为green的所有记录,不论其大小写,表达式应为'/[Gg]reen/':
$ awk '/[Gg]reen/' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
8.任意字符
抽取名字,其记录第一域的第四个字符a,使用句点.。表达式/^...a/意为行首前三个字符任意,第四个a,尖角符号代表行首。
$ awk '$1~/^...a/' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
L.Tansley 05/99 4712 Brown-2 12 30 28
9.或关系匹配
为抽取级别为Yellow或Brown的记录,使用竖线符|。意为匹配| 两边模式之一。注意,使用竖线符时,语句必须用圆括号括起来。
$ awk '$0~/(Yellow|Brown)/' grade.txt
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
上面例子输出所有级别为Yellow或Brown的记录。
使用这种方法在查询级别为Green或green时,可以得到与使用[]表达式相同的结果。
$ awk '$0~/(Green|green)/' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
10.行首
不必总是使用域号。如果查询文本文件行首包含48的代码,可简单使用下面^符号:
$ awk '/^48/' input-file
这里讲述了在awk中怎样使用第7章中涉及的表达式。像第7章的开头提到的,所有表达式(除字符重复出现外)在awk中都是合法的。
复合模式或复合操作符用于形成复杂的逻辑操作,复杂程度取决于编程者本人。有必要了解的是,复合表达式即为模式间通过使用下述各表达式互相结合起来的表达式:
&& AND:语句两边必须同时匹配为真。
|| OR:语句两边同时或其中一边匹配为真。
! NO:求逆
11.AND
打印记录,使其名字为P.Bunny且级别为Yellow,使用表达式($1=="P.Bunny" && $4=="Yellow"),意为&&两边匹配均为真。完整命令如下:
$ awk '{if($1=="P.Bunny" && $4=="Yellow") print $0}' grade.txt
P.Bunny 02/99 48 Yellow 12 35 28
12.OR
如果查询级别为Yellow或Brown,使用或命令。意为“||”符号两边的匹配模式之一或全部为真。
$ awk '{if($4=="Yellow" || $4~/Brown/) print $0}' grade.txt
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
9.2.6 awk内置变量
awk有许多内置变量用来设置环境信息。这些变量可以被改变。表9-3显示了最常使用的一些变量,并给出其基本含义。
表9-3 awk内置变量
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行-F选项
NF 浏览记录的域个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
ARGC支持命令行中传入awk脚本的参数个数。ARGV是ARGC的参数排列数组,其中每一元素表示为ARGV[n],n为期望访问的命令行参数。
ENVIRON支持系统设置的环境变量,要访问单独变量,使用实际变量名,例如ENVIRON["EDITOR"]="Vi"。
FILENAME支持awk脚本实际操作的输入文件。因为awk可以同时处理许多文件,因此如果访问了这个变量,将告之系统目前正在浏览的实际文件。
FNR支持awk目前操作的记录数。其变量值小于等于NR。如果脚本正在访问许多文件,每一新输入文件都将重新设置此变量。
FS用来在awk中设置域分隔符,与命令行中-F选项功能相同。缺省情况下为空格。如果用逗号来作域分隔符,设置FS=","。
NF支持记录域个数,在记录被读之后再设置。
OFS允许指定输出域分隔符,缺省为空格。如果想设置为#,写入OFS="#"。
ORS为输出记录分隔符,缺省为新行(\n)。
RS是记录分隔符,缺省为新行(\n)。
9.2.7 NF、NR和FILENAME
下面看一看awk内置变量的例子。
要快速查看记录个数,应使用NR。比如说导出一个数据库文件后,如果想快速浏览记录个数,以便对比于其初始状态,查出导出过程中出现的错误。使用NR将打印输入文件的记录个数。print NR放在END语法中。
$ awk 'END {print NR}' grade.txt
以下例子中,所有学生记录被打印,并带有其记录号。使用NF变量显示每一条读记录中有多少个域,并在END部分打印输入文件名。
$ awk '{print NF,NR,$0}END{print FILENAME}' grade.txt
7 1 M.Tansley 05/99 48311 Green 8 40 44
7 2 J.Lulu 06/99 48317 green 9 24 26
7 3 P.Bunny 02/99 48 Yellow 12 35 28
7 4 J.Troll 07/99 4842 Brown-3 12 26 26
7 5 L.Tansley 05/99 4712 Brown-2 12 30 28
grade.txt
在从文件中抽取信息时,最好首先检查文件中是否有记录。下面的例子只有在文件中至少有一个记录时才查询Brown级别记录。使用AND复合语句实现这一功能。意即至少存在一个记录后,查询字符串Brown,最后打印结果。
$ awk '{if(NR>0 && $4~/Brown/) print $0}' grade.txt
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
NF的一个强大功能是将变量$PWD的返回值传入awk并显示其目录。这里需要指定域分隔符/。
$ pwd
/usr/local/etc
$ echo $PWD | awk -F/ '{print $NF}'
etc
另一个例子是显示文件名。
$ echo "/usr/local/etc/rc.sybase" | awk -F/ '{print $NF}'
rc.sybase
9.2.8 awk操作符
在awk中使用操作符,基本表达式可以划分为数字型、字符串型、变量型、域及数组元素,前面已经讲过一些。下面列出其完整列表。
在表达式中可以使用下述任何一种操作符。
= += *= / = %= ^= 赋值操作符
? 条件表达操作符
|| && ! 并、与、非(上一节已讲到)
~!~ 匹配操作符,包括匹配和不匹配
< <= == != >= > 关系操作符
+ - * / % ^ 算术操作符
++ -- 前缀和后缀
前面已经讲到了其中几种操作,下面继续讲述未涉及的部分。
1.设置输入域到域变量名
在awk中,设置有意义的域名是一种好习惯,在进行模式匹配或关系操作时更容易理解。一般的变量名设置方式为name=$n,这里name为调用的域变量名,n为实际域号。例如设置学生域名为name,级别域名为belt,操作为name=$1;belts=$4。注意分号的使用,它分隔awk命令。下面例子中,重新赋值学生名域为name,级别域为belts。查询级别为Yellow的记录,并最终打印名称和级别。
$ awk '{name=$1;belts=$4; if(belts~/Yellow/) print name" is belt "belts}' grade.txt
P.Bunny is belt Yellow
2.域值比较操作
有两种方式测试一数值域是否小于另一数值域。
1) 在BEGIN中给变量名赋值。
2) 在关系操作中使用实际数值。
通常在BEGIN部分赋值是很有益的,可以在awk表达式进行改动时减少很多麻烦。
使用关系操作必须用圆括号括起来。
下面的例子查询所有比赛中得分在27点以下的学生。
用引号将数字引用起来是可选的,“27”、27产生同样的结果。
$ awk '{if($6 < 27) print $0}' grade.txt
J.Lulu 06/99 48317 green 9 24 26
J.Troll 07/99 4842 Brown-3 12 26 26
第二个例子中给数字赋以变量名BASELINE和在BEGIN部分给变量赋值,两者意义相同。
$ awk 'BEGIN {BASELINE="27"}{if($6 < BASELINE) print $0}' grade.txt
J.Lulu 06/99 48317 green 9 24 26
J.Troll 07/99 4842 Brown-3 12 26 26
3.修改数值域取值
当在awk中修改任何域时,重要的一点是要记住实际输入文件是不可修改的,修改的只是保存在缓存里的awk复本。awk会在变量NR或NF变量中反映出修改痕迹。
为修改数值域,简单的给域标识重赋新值,如:$1=$1+5,会将域1数值加5,但要确保赋值域其子集为数值型。
修改M.Tansley的目前级别分域,使其数值从40减为39,使用赋值语句$6=$6-1,当然在实施修改前首先要匹配域名。
$ awk '{if($1=="M.Tansley") $6=$6-1; print $1,$6,$7}' grade.txt
M.Tansley 39 44
J.Lulu 24 26
P.Bunny 35 28
J.Troll 26 26
L.Tansley 30 28
4.修改文本域
修改文本域即对其重新赋值。需要做的就是赋给一个新的字符串。在J.Troll中加入字母,使其成为J.L.Troll,表达式为$1="J.L.Troll",记住字符串要使用双秒号(""),并用圆括号括起整个语法。
$ awk '{if($1=="J.Troll") ($1="J.L.Troll"); print $1}' grade.txt
M.Tansley
J.Lulu
P.Bunny
J.L.Troll
L.Tansley
5.只显示修改记录
上述例子均是对一个小文件的域进行修改,因此打印出所有记录查看修改部分不成问题,但如果文件很大,记录甚至超过100,打印所有记录只为查看修改部分显然不合情理。在模式后面使用花括号将只打印修改部分。取得模式,再根据模式结果实施操作,可能有些抽象,现举一例,只打印修改部分。注意花括号的位置。
$ awk '{if($1=="J.Troll") {$1="J.L.Troll"; print $1}}' grade.txt
J.L.Troll
6.创建新的输出域
在awk中处理数据时,基于各域进行计算时创建新域是一种好习惯。创建新域要通过其他域赋予新域标识符。如创建一个基于其他域的加法新域{$4=$2+$3},这里假定记录包含3个域,则域4为新建域,保存域2和域3相加结果。
在文件grade.txt中创建新域8保存域目前级别分与域最高级别分的减法值。表达式为‘{$8=$7-$6}’,语法首先测试域目前级别分小于域最高级别分。新域因此只打印其值大于零的学生名称及其新域值。在BEGIN部分加入tab键以对齐报告头。
$ awk 'BEGIN{ print "Name\t Difference"} {if($6 < $7) {$8=$7-$6; print $1,$8}}' grade.txt
Name Difference
M.Tansley 4
J.Lulu 2
当然可以创建新域,并赋给其更有意义的变量名。例如:
$ awk 'BEGIN{ print "Name\t Difference"} {if($6 < $7) {diff=$7-$6; print $1,diff}}' grade.txt
Name Difference
M.Tansley 4
J.Lulu 2
7.增加列值
为增加列数或进行运行结果统计,使用符号+ =。增加的结果赋给符号左边变量值,增加到变量的域在符号右边。例如将$1加入变量total,表达式为total+=$1。列值增加很有用。许多文件都要求统计总数,但输出其统计结果十分繁琐。在awk中这很简单,请看下面的例子。
将所有学生的‘目前级别分’加在一起,方法是tot+=$6,tot即为awk浏览的整个文件的域6结果总和。所有记录读完后,在END部分加入一些提示信息及域6总和。不必在awk中显示说明打印所有记录,每一个操作匹配时,这是缺省动作。
$ awk '(tot+=$6); END{print "Club student total points :" tot}' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
Club student total points :155
如果文件很大,你只想打印结果部分而不是所有记录,在语句的外面加上大括号{}即可。
$ awk '{(tot+=$6)}; END{print "Club student total points :" tot}' grade.txt
Club student total points :155
8.文件长度相加
在目录中查看文件时,如果想快速查看所有文件的长度及其总和,但要排除子目录,使用ls -l命令,然后管道输出到awk,awk首先剔除首字符为d(使用正则表达式)的记录,然后将文件长度列相加,并输出每一文件长度及在END部分输出所有文件的长度。
本例中,首先用ls -l命令查看一下文件属性。注意第二个文件属性首字符为d,说明它是一个目录,文件长度是第5列,文件名是第9列。如果系统不是这样排列文件名及其长度,应适时加以改变。
-rw-r--r-- 1 root root 80 Apr 11 18:56 acc.txt
drwx------ 2 root root 1024 Mar 26 20:53 nsmail
Columns 1 2 3 4 5 6 7 8 9
下面的正则表达式表明必须匹配行首,并排除字符d,表达式为^[^d]。
使用此模式打印文件名及其长度,然后将各长度相加放入变量tot中。
$ ls -l | awk '/^[^d]/ {print $9"\t"$5} {tot+=$5} END {print "total KB:"tot}'
dev_pkg.fail 345
failedlogin 12416
messages 4260
sulog 12810
utmp 1856
wtmp 7104
total KB:41351
9.2.9 内置的字符串函数
awk有许多强大的字符串函数,见表9-4。
表9-4 awk内置字符串函数
gsub(r,s) 在整个$0中用s替代r
gsub(r,s,t) 在整个t中用s替代r
index(s,t) 返回s中字符串t的第一位置
length(s) 返回s长度
match(s,r) 测试s是否包含匹配r的字符串
split(s,a,fs) 在fs上将s分成序列a
sprint(fmt,exp) 返回经fmt格式化后的exp
sub(r,s) 用$0中最左边最长的子串代替s
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分
gsub函数有点类似于sed查找和替换。它允许替换一个字符串或字符为另一个字符串或字符,并以正则表达式的形式执行。第一个函数作用于记录$0,第二个gsub函数允许指定目标,然而,如果未指定目标,缺省为$0。
index(s,t)函数返回目标字符串s中查询字符串t的首位置。length函数返回字符串s字符长度。match函数测试字符串s是否包含一个正则表达式r定义的匹配。split使用域分隔符fs将字符串s划分为指定序列a。sprint函数类似于printf函数(以后涉及),返回基本输出格式fmt的结果字符串exp。sub(r,s)函数将用s替代$ 0中最左边最长的子串,该子串被(r)匹配。sub(s,p)返回字符串s在位置p后的后缀。substr(s,p,n)同上,并指定子串长度为n。
现在看一看awk中这些字符串函数的功能。
1. gsub
要在整个记录中替换一个字符串为另一个,使用正则表达式格式:/目标模式/,替换模式。例如改变学生序号4842到4899:
$ awk 'gsub(/4842/,4899) {print $0}' grade.txt
J.Troll 07/99 4899 Brown-3 12 26 26
2.index
查询字符串s中t出现的第一位置。必须用双引号将字符串括起来。例如返回目标字符串Bunny中ny出现的第一位置,即字符个数。
$ awk 'BEGIN {print index("Bunny","ny")}' grade.txt
4
3.length
返回所需字符串长度,例如检验字符串J.Troll返回名字及其长度,即人名构成的字符个数。
$ awk '$1=="J.Troll" {print length($1)" "$1}' grade.txt
7 J.Troll
还有一种方法,这里字符串加双引号。
$ awk 'BEGIN {print length("A FEW GOOD MEN")}'
14
4.match
match测试目标字符串是否包含查找字符的一部分。可以对查找部分使用正则表达式,返回值为成功出现的字符排列数。如果未找到,返回0,第一个例子在ANCD中查找d。因其不存在,所以返回0。第二个例子在ANCD中查找C。因其存在,所以返回ANCD中D出现的首位置字符数。第三个例子在学生J.Lulu中查找u。
$ awk 'BEGIN{print match("ANCD",/d/)}'
0
$ awk 'BEGIN{print match("ANCD",/C/)}'
3
$ awk '$1=="J.Lulu" {print match($1,"u")}' grade.txt
4
5.split
使用split返回字符串数组元素个数。工作方式如下:如果有一字符串,包含一指定分隔符-,例如AD2-KP9-JU2-LP-1,将之划分成一个数组。使用split,指定分隔符及数组名。此例中,命令格式为("AD2-KP9-JU2-LP-1", parts_array, "-"),split然后返回数组下标数,这里结果为5。
$ awk 'BEGIN {print split("AD2-KP9-JU2-LP-1", parts_array, "-")}'
5
还有一个例子使用不同的分隔符。
$ awk 'BEGIN {print split("123#456#678", myarray, "#")}'
3
这个例子中,split返回数组myarray的下标数。数组myarray取值如下:
Myarray[1]="123"
Myarray[2]="456"
Myarray[3]="678"
本章结尾部分讲述数组概念。
6.sub
使用sub发现并替换模式的第一次出现位置。字符串STR包含'poped pope pill',执行下列sub命令sub(/op/, "OP", STR)。模式op第一次出现时,进行替换操作,返回结果如下:
'pOPed pope pill'。
$ awk 'BEGIN{STR="poped pope pill";sub(/op/,"OP",STR);print STR}'
pOPed pope pill
本章文本文件中,学生J.Troll的记录有两个值一样,“目前级别分”与“最高级别分”。只改变第一个为29,第二个仍为26不动,操作命令为sub(/26/,"29",$0),只替换第一个出现26的位置。注意J.Troll记录需存在。
$ awk '$1=="J.Troll" sub(/26/,"29",$0)' grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 29
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 29 26
L.Tansley 05/99 4712 Brown-2 12 30 28
7.substr
substr是一个很有用的函数。它按照起始位置及长度返回字符串的一部分。例子如下:
$ awk '$1=="L.Tansley" {print substr($1,1,5)}' grade.txt
L.Tan
上面例子中,指定在域1的第一个字符开始,返回其前面5个字符。
如果给定长度值远大于字符串长度,awk将从起始位置返回所有字符,要抽取L.Tansley的姓,只需从第3个字符开始返回长度为7。可以输入长度99,awk返回结果相同。
$ awk '$1=="L.Tansley" {print substr($1,3,99)}' grade.txt
Tansley
substr的另一种形式是返回字符串后缀或指定位置后面字符。这里需要给出指定字符串及其返回字串的起始位置。例如,从文本文件中抽取姓氏,需操作域1,并从第三个字符开始:
$ awk '{print substr($1,3)}' grade.txt
Tansley
Lulu
Bunny
Troll
Tansley
还有一个例子,在BEGIN部分定义字符串,在END部分返回从第7个字符开始抽取的子串。
$ awk 'BEGIN {STR="A FEW GOOD MEN"}END{print substr(STR,7)}' grade.txt
GOOD MEN
8.从shell中向awk传入字符串
本章开始已经提到过,awk脚本大多只有一行,其中很少是字符串表示的。本书大多要求在一行内完成awk脚本,这一点通过将变量传入awk命令行会变得很容易。现就其基本原理讲述一些例子。
使用管道将字符串stand-by传入awk,返回其长度。
$ echo "stand-by" | awk '{print length($0)}'
8
设置文件名为一变量,管道输出到awk,返回不带扩展名的文件名。
$ STR="mydoc.txt"
$ echo $STR | awk '{print substr($STR,1,5)}'
mydoc
设置文件名为一变量,管道输出到awk,只返回其扩展名。
$ STR="mydoc.txt"
$ echo $STR | awk '{print substr($STR,7)}'
txt
9.2.10 字符串屏蔽序列
使用字符串或正则表达式时,有时需要在输出中加入一新行或查询一元字符。
打印一新行时,(新行为字符\n),给出其屏蔽序列,以不失其特殊含义,用法为在字符串前加入反斜线。例如使用\n强迫打印一新行。
如果使用正则表达式,查询花括号({}),在字符前加反斜线,如/\{/,将在awk中失掉其特殊含义。
表9-5列出awk识别的另外一些屏蔽序列
表9-5 awk中使用的屏蔽序列
\b 退格键 \t ab键
\f 走纸换页 \ddd 八进制值
\n 新行 \c 任意其他特殊字符,例如\ \为反斜线符号
\r 回车键
使用上述符号,打印May Day,中间夹tab键,后跟两个新行,再打印May Day,但这次使用八进制数104、141、171、分别代表D、a、y。
$ awk 'BEGIN {print "May\tDay\n\nMay\t\104\141\171"}'
May Day
May Day
注意,\104为D的八进制ASCII码,\141为a的八进制ASCII码,等等。
9.2.11 awk输出函数printf
目前为止,所有例子的输出都是直接到屏幕,除了tab键以外没有任何格式。awk提供函数printf,拥有几种不同的格式化输出功能。例如按列输出、左对齐或右对齐方式。
每一种printf函数(格式控制字符)都以一个%符号开始,以一个决定转换的字符结束。转换包含三种修饰符。
printf函数基本语法是printf ([格式控制符],参数),格式控制字符通常在引号里。
9.2.12 printf修饰符
表9-6 awk printf修饰符
- 左对齐
Width 域的步长,用0表示0步长
.prec 最大字符串长度,或小数点右边的位数
表9-7 awk printf格式
%c ASCII字符
%d 整数
%e 浮点数,科学记数法
%f 浮点数,例如(123.44)
%g awk决定使用哪种浮点数转换e或者f
%o 八进制数
%s 字符串
%x 十六进制数
1.字符转换
观察ASCII码中65的等价值。管道输出65到awk.printf进行ASCII码字符转换。这里也加入换行,因为缺省情况下printf不做换行动作。
$ echo "65" | awk '{printf "%c\n",$0}'
A
当然也可以按同样方式使用awk得到同样结果。
$ awk 'BEGIN {printf "%c\n",65}'
A
所有的字符转换都是一样的,下面的例子表示进行浮点数转换后‘999’的输出结果。整数传入后被加了六个小数点。
$ awk 'BEGIN {printf "%f\n",999}'
999.000000
2.格式化输出
打印所有的学生名字和序列号,要求名字左对齐,15个字符长度,后跟序列号。注意\ n换行符放在最后一个指示符后面。输出将自动分成两列。
$ awk '{printf "%-15s %s\n",$1,$3}' grade.txt
M.Tansley 48311
J.Lulu 48317
P.Bunny 48
J.Troll 4842
L.Tansley 4712
最好加入一些文本注释帮助理解报文含义。可在正文前嵌入头信息。注意这里使用print加入头信息。如果愿意,也可使用printf。
$ awk 'BEGIN {print "Name \t\tS.Number"}{printf "%-15s %s\n",$1,$3}' grade.txt
Name S.Number
M.Tansley 48311
J.Lulu 48317
P.Bunny 48
J.Troll 4842
L.Tansley 4712
3.向一行awk命令传值
在查看awk脚本前,先来查看怎样在awk命令行中传递变量。
在awk执行前将值传入awk变量,需要将变量放在命令行中,格式如下:
awk 命令变量=输入文件值
(后面会讲到怎样传递变量到awk脚本中)。
下面的例子在命令行中设置变量AGE等于10,然后传入awk中,查询年龄在10岁以下的所有学生。
$ awk '{if($5 < AGE) print $0}' AGE=10 grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
要快速查看文件系统空间容量,观察其是否达到一定水平,可使用下面awk一行脚本。因为要监视的已使用空间容量不断在变化,可以在命令行指定一个触发值。首先用管道命令将df -k 传入awk,然后抽出第4列,即剩余可利用空间容量。使用$4~/^[0-9]/取得容量数值(1024块)而不是df的文件头,然后对命令行与'if($4 < TRIGGER) '上变量TRIGGER中指定的值进行查询测试。
$ df -k | awk '($4~/^[0-9]/) {if($4 < TRIGGER) print $6"\t"$4}' TRIGGER=56000
/dos 55808
/apps 51022
在系统中使用df -k命令,产生下列信息:
Filesystem 1K-blocks Used Avail Capacity Mounted on
Column 1 2 3 4 5 6
如果系统中df输出格式不同,必须相应改变列号以适应工作系统。
当然可以使用管道将值传入awk。本例使用who命令,who命令第一列包含注册用户名,这里打印注册用户,并加入一定信息。
$ who | awk '{print $1 " is logged on"}'
louisel is logged on
papam is logged on
awk也允许传入环境变量。下面的例子使用环境变量LOGNAME支持当前用户名。可从who命令管道输出到awk中获得相应信息。
$ who | awk '{if($1==user) print $1" you are connected to "$2}' user=$LOGNAME
如果root为当前登录用户,输出如下:
root you are connected to ttyp1
4.awk脚本文件
可以将awk脚本写入一个文件再执行它。命令不必很长(尽管这是写入一个脚本文件的主要原因),甚至可以接受一行命令。这样可以保存a w k命令,以使不必每次使用时都需要重新输入。使用文件的另一个好处是可以增加注释,以便于理解脚本的真正用途和功能。
使用前面的几个例子,将之转换成awk可执行文件。像原来做的一样,将学生目前级别分相加awk '(tot+=$6) END{print "club student total points:"tot}' grade.txt。
创建新文件student_tot.awk,给所有awk程序加入awk扩展名是一种好习惯,这样通过查看文件名就知道这是一个awk程序。文本如下:
#!/usr/bin/awk -f
# all comment lines must start with a hash '#'
# name: student_tot.awk
# to call: student_tot.awk grade.txt
# prints total and average of club student points
# print a header first
BEGIN{
print "Student Date Member No. Grade Age Points Max"
print "Name Joined Gained Point Available"
print "=================================================================="
}
# let's add the scores of points gained
(tot+=$6)
# finished processing now let's print the total and average point
END{print "Club student total points : " tot"\nAverage Club Student points: " tot/NR}
第一行是#!/bin/awk -f。这很重要,没有它自包含脚本将不能执行。这一行告之脚本系统中awk的位置。通过将命令分开,脚本可读性提高,还可以在命令之间加入注释。这里加入头信息和结尾的平均值。基本上这是一个一行脚本文件。
执行时,在脚本文件后键入输入文件名,但是首先要对脚本文件加入可执行权限。
$ chmod u+x student_tot.awk
$ ./student_tot.awk grade.txt
Student Date Member No. Grade Age Points Max
Name Joined Gained Point Available
======================================================================
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
P.Bunny 02/99 48 Yellow 12 35 28
J.Troll 07/99 4842 Brown-3 12 26 26
L.Tansley 05/99 4712 Brown-2 12 30 28
Club student total points :155
Average Club Student points:31
系统中运用的帐号核实程序检验数据操作人的数据输入,不幸的是这个程序有一点错误,或者应该说是“非文本特征”。如果一个记录被发现包含一个错误,它应该一次只打印一行 “ERROR*”,但实际上打印了许多这样的错误行。这会给帐号管理员造成误解,因此需要用awk脚本过滤出错误行的出现频率,使得每一个失败记录只对应一个错误行。
在awk实施过滤前先看看部分文件:
...
...
INVALID LCSD 98GJ23
ERROR*
ERROR*
CAUTION LPSS ERROR ON ACC NO.
ERROR*
ERROR*
ERROR*
ERROR*
ERROR*
PASS FIELD INVALID ON LDPS
ERROR*
ERROR*
PASS FIELD INVALID ON GHSI
ERROR*
CAUTION LPSS ERROR ON ACC NO.
ERROR*
ERROR*
awk脚本如下:
#!/bin/awk -f
# error_strip.awk
# to call: error_strip.awk <filename>
# strips out the ERROR* lines if there are more than one
# ERROR* lines after each failed record.
BEGIN {error_line=""}
# tell awk the whole is "ERROR*"
{if($0=="ERROR*" && error_line=="ERROR*")
# go to next line
next;
error_line=$0; print}
awk过滤结果如下:
$ strip.awk strip
INVALID LCSD 98GJ23
ERROR*
CAUTION LPSS ERROR ON ACC NO.
ERROR*
PASS FIELD INVALID ON LDPS
ERROR*
PASS FIELD INVALID ON GHSI
ERROR*
CAUTION LPSS ERROR ON ACC NO.
ERROR*
5.在awk中使用FS变量
如果使用非空格符做域分隔符(FS)浏览文件,例如#或:,编写这样的一行命令很容易,因为使用FS选项可以在命令行中指定域分隔符。
$ awk -F: 'awk {print $0}' input-file
使用awk脚本时,记住设置FS变量是在BEGIN部分。如果不这样做,awk将会发生混淆,不知道域分隔符是什么。
下述脚本指定FS变量。脚本从/etc/passwd文件中抽取第1和第5域,通过冒号“:”分隔passwd文件域。第1域是帐号名,第5域是帐号所有者。
$ pg passwd.awk
#!/bin/awk -f
# to call: passwd.awk /etc/passwd
# print out the first and fifth fields
BEGIN{
FS=":"}
{print $1, "\t",$5}
$ passwd.awk /etc/passwd
root Special Admin login
xdm Restart xdm Login
sysadm Regular Admin login
daemon Daemon Login for daemons needing permissions
6.向awk脚本传值
向awk脚本传值与向awk一行命令传值方式大体相同,格式为:
awk script_file var=value input_file
下述脚本对比检查文件中域号和指定数字。这里使用了NF变量MAX,表示指定检查的域号,使用双引号将域分隔符括起来,即使它是一个空格。
$ pg fieldcheck.awk
#!/bin/awk -f
# check on how many fields in a file
# name:fieldcheck.awk
# to call: fieldcheck MAX=n FS=<separator> filename
#
NF!=MAX{
print("line " NR " does not have" MAX " fields")}
如果以/etc/passwd作输入文件(passwd文件有7个域),运行上述脚本。参数格式如下:
$ fieldcheck.awk MAX=7 FS=":" /etc/passwd
使用前面一行脚本的例子,将之转换成awk脚本如下:
$ pg age.awk
#!/bin/awk -f
# name: age.awk
# to call: age.awk AGE=n grade.txt
# prints ages that are lower than the age supplied on the command line
{if($5 < AGE)
print $0}
文本包括了比实际命令更多的信息,没关系,仔细研读文本后,就可以精确知道其功能及如何调用它。
不要忘了增加脚本的可执行权限,然后将变量和赋值放在命令行脚本名字后、输入文件前执行。
$ age.awk AGE=10 grade.txt
M.Tansley 05/99 48311 Green 8 40 44
J.Lulu 06/99 48317 green 9 24 26
同样可以使用前面提到的管道命令传值,下述awk脚本从du命令获得输入,并输出块和字节数。
$ pg duawk.awk
#!/bin/awk -f
# to call: du | duawk.awk
# prints file/direc's in bytes and blocks
BEGIN{
FS="\t" ;
print "name" "\t\t","bytes","blocks\n"
print "=============================="}
{print $2,"\t\t",$1*512,$1}
为运行这段脚本,使用du命令,并管道输出至awk脚本。
$ du | duawk.awk
name bytes blocks
=================================
./profile.d 2048 4
./X11 135680 265
./rc.d/init.d 27136 53
./rc.d/rc0.d 512 1
./rc.d/rc1.d 512 1
9.2.13 awk数组
前面讲述split函数时,提到怎样使用它将元素划分进一个数组。这里还有一个例子:
$ awk 'BEGIN {print split("123#456#678", myarray, "#")}'
在上面的例子中,split返回数组myarray下标数。实际上myarray数组为:
Myarray[1]="123"
Myarray[2]="456"
Myarray[3]="678"
数组使用前,不必定义,也不必指定数组元素个数。经常使用循环来访问数组。下面是一种循环类型的基本结构:
For (element in array) print array[element]
对于记录“123#456#789”,先使用split函数划分它,再使用循环打印各数组元素。操作脚本如下:
$ pg arraytest.awk
#!/bin/awk -f
# name: arraytest.awk
# prints out an array
BEGIN{
record="123#456#789";
split(record, myarray, "#")}
END{for(i in myarray) {print myarray[i]}}
要运行脚本,使用/dev/null作为输入文件。
$ arraytest.awk /dev/null
123
456
789
数组和记录
上面的例子讲述怎样通过split函数使用数组。也可以预先定义数组,并使用它与域进行比较测试,下面的例子中将使用更多的数组。
下面是从空手道数据库卸载的一部分数据,包含了学生级别及是否是成人或未成年人的信息,有两个域,分隔符为(#),文件如下:
$ pg grade_student.txt
Yellow#Junior
Orange#Senior
Yellow#Junior
Purple#Junior
Brown-2#Junior
White#Senior
Orange#Senior
Red#Junior
Brown-2#Senior
Yellow#Senior
Red#Junior
Blue#Senior
Green#Senior
Purple#Junior
White#Junior
脚本功能是读文件并输出下列信息。
1)俱乐部中Yellow、Orange和Red级别的人各是多少。
2)俱乐部中有多少成年人和未成年人。
查看文件,也许20秒内就会猜出答案,但是如果记录超过60个又怎么办呢?这不会很容易就看出来,必须使用awk脚本。
首先看看awk脚本,然后做进一步讲解。
$ pg belts.awk
#!/bin/awk -f
# name: belts.awk
# to call: belts.awk grade_student.txt
# loops through the grade2.txt file and counts how many
# belts we have in (yellow, orange, red)
# also count how many adults and juniors we have
#
# start of BEGIN
# set FS and load the arrays with our values
BEGIN{FS="#"
# load the belt colours we are interested in only
belt["Yellow"]
belt["Orange"]
belt["Red"]
# end of BEGIN
# load the student type
student["Junior"]
student["Senior"]
}
# loop through array that holds the belt colors against field-1
# if we have a match, keep a runnning total
{for(colour in belt)
{if($1==colour)
belt[colour]++}}
# loop through array that holds the student type against
# field-2 if we have a match, keep a running total
{for(senior_or_junior in student)
{if($2==senior_or_junior)
student[senior_or_junior]++}}
# finished processing so print out the matches..for each array
END{for(colour in belt) print "The club has", belt[colour], colour, "Belts"
for(senior_or_junior in student) print "The club has", student[senior_or_junior]\
, senior_or_junior, "students"}
BEGIN部分设置FS为符号#,即域分隔符,因为要查找Yellow、Orange和Red三个级别。然后在脚本中手工建立数组下标对学生做同样的操作。注意,脚本到此只有下标或元素,并没有给数组名本身加任何注释。初始化完成后, BEGIN部分结束。记住BEGIN部分并没有文件处理操作。
现在可以处理文件了。首先给数组命名为color,使用循环语句测试域1级别列是否等于数组元素之一(Yellow、Orange或Red),如果匹配,依照匹配元素将运行总数保存进数组。
同样处理数组‘Senior_or_junior’,浏览域2时匹配操作满足,运行总数存入junior或senior的匹配数组元素。
END部分打印浏览结果,对每一个数组使用循环语句并打印它。
注意在打印语句末尾有一个\符号,用来通知awk(或相关脚本)命令持续到下一行,当输入一个很长的命令,并且想分行输入时可使用这种方法。运行脚本前记住要加入可执行权限。
$ ./belts.awk grade_student.txt
The club has 2 Red Belts
The club has 2 Orange Belts
The club has 3 Yellow Belts
The club has 7 Senior students
The club has 8 Junior students
9.3 小结
awk语言学起来可能有些复杂,但使用它来编写一行命令或小脚本并不太难。本章讲述了awk的最基本功能,相信大家已经掌握了awk的基本用法。awk是shell编程的一个重要工具。在shell命令或编程中,虽然可以使用awk强大的文本处理能力,但是并不要求你成为这方面的专家。
linux下CURL命令
Curl是Linux下一个很强大的http命令行工具,其功能十分强大。
1) 二话不说,先从这里开始吧!
$ curl http://www.linuxidc.com
回车之后,www.linuxidc.com 的html就稀里哗啦地显示在屏幕上了 ~
2) 嗯,要想把读过来页面存下来,是不是要这样呢?
$ curl http://www.linuxidc.com > page.html
当然可以,但不用这么麻烦的!
用curl的内置option就好,存下http的结果,用这个option: -o
$ curl -o page.html http://www.linuxidc.com
这样,你就可以看到屏幕上出现一个下载页面进度指示。等进展到100%,自然就 OK咯
3) 什么什么?!访问不到?肯定是你的proxy没有设定了。
使用curl的时候,用这个option可以指定http访问所使用的proxy服务器及其端口: -x
$ curl -x 123.45.67.89:1080 -o page.html http://www.linuxidc.com
4) 访问有些网站的时候比较讨厌,他使用cookie来记录session信息。
像IE/NN这样的浏览器,当然可以轻易处理cookie信息,但我们的curl呢?.....
我们来学习这个option: -D <— 这个是把http的response里面的cookie信息存到一个特别的文件中去
$ curl -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,当页面被存到page.html的同时,cookie信息也被存到了cookie0001.txt里面了
5)那么,下一次访问的时候,如何继续使用上次留下的cookie信息呢?要知道,很多网站都是靠监视你的cookie信息,来判断你是不是不按规矩访问他们的网站的。
这次我们使用这个option来把上次的cookie信息追加到http request里面去: -b
$ curl -x 123.45.67.89:1080 -o page1.html -D cookie0002.txt -b cookie0001.txt http://www.linuxidc.com
这样,我们就可以几乎模拟所有的IE操作,去访问网页了!
6)稍微等等 ~我好像忘记什么了 ~
对了!是浏览器信息
有些讨厌的网站总要我们使用某些特定的浏览器去访问他们,有时候更过分的是,还要使用某些特定的版本 NND,哪里有时间为了它去找这些怪异的浏览器呢!?
好在curl给我们提供了一个有用的option,可以让我们随意指定自己这次访问所宣称的自己的浏览器信息: -A
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,服务器端接到访问的要求,会认为你是一个运行在Windows 2000上的 IE6.0,嘿嘿嘿,其实也许你用的是苹果机呢!
而"Mozilla/4.73 [en] (X11; U; Linux 2.2; 15 i686"则可以告诉对方你是一台 PC上跑着的Linux,用的是Netscape 4.73,呵呵呵
7)另外一个服务器端常用的限制方法,就是检查http访问的referer。比如你先访问首页,再访问里面所指定的下载页,这第二次访问的 referer地址就是第一次访问成功后的页面地址。这样,服务器端只要发现对下载页面某次访问的referer地址不是首页的地址,就可以断定那是个盗 连了 ~
讨厌讨厌 ~我就是要盗连 ~!!
幸好curl给我们提供了设定referer的option: -e
$ curl -A "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)" -x 123.45.67.89:1080 -e "mail.linuxidc.com" -o page.html -D cookie0001.txt http://www.linuxidc.com
这样,就可以骗对方的服务器,你是从mail.linuxidc.com点击某个链接过来的了,呵呵呵
8)写着写着发现漏掉什么重要的东西了!——- 利用curl 下载文件
刚才讲过了,下载页面到一个文件里,可以使用 -o ,下载文件也是一样。比如,
$ curl -o 1.jpg http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这里教大家一个新的option: -O 大写的O,这么用:
$ curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen1.JPG
这样,就可以按照服务器上的文件名,自动存在本地了!
再来一个更好用的。
如果screen1.JPG以外还有screen2.JPG、screen3.JPG、....、screen10.JPG需要下载,难不成还要让我们写一个script来完成这些操作?
不干!
在curl里面,这么写就可以了:
$ curl -O http://cgi2.tky.3web.ne.jp/~zzh/screen[1-10].JPG
呵呵呵,厉害吧?! ~
9)再来,我们继续讲解下载!
$ curl -O http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
这样产生的下载,就是
~zzh/001.JPG
~zzh/002.JPG
...
~zzh/201.JPG
~nick/001.JPG
~nick/002.JPG
...
~nick/201.JPG
够方便的了吧?哈哈哈
咦?高兴得太早了。
由于zzh/nick下的文件名都是001,002...,201,下载下来的文件重名,后面的把前面的文件都给覆盖掉了 ~
没关系,我们还有更狠的!
$ curl -o #2_#1.jpg http://cgi2.tky.3web.ne.jp/~{zzh,nick}/[001-201].JPG
—这是.....自定义文件名的下载? —对头,呵呵!
这样,自定义出来下载下来的文件名,就变成了这样:原来: ~zzh/001.JPG —-> 下载后: 001-zzh.JPG 原来: ~nick/001.JPG —-> 下载后: 001-nick.JPG
这样一来,就不怕文件重名啦,呵呵
linux下sed命令
1. Sed简介
sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。以下介绍的是Gnu版本的Sed 3.02。
2. 定址
可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这两行为起止的行的范围(包括行数表示的那两行)。如1,3表示1,2,3行,美元符号($)表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定 。
3. Sed命令
调用sed命令有两种形式:
*
sed [options] 'command' file(s)
*
sed [options] -f scriptfile file(s)
a\
在当前行后面加入一行文本。
b lable
分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
c\
用新的文本改变本行的文本。
d
从模板块(Pattern space)位置删除行。
D
删除模板块的第一行。
i\
在当前行上面插入文本。
h
拷贝模板块的内容到内存中的缓冲区。
H
追加模板块的内容到内存中的缓冲区
g
获得内存缓冲区的内容,并替代当前模板块中的文本。
G
获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l
列表不能打印字符的清单。
n
读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N
追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p
打印模板块的行。
P(大写)
打印模板块的第一行。
q
退出Sed。
r file
从file中读行。
t label
if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label
错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file
写并追加模板块到file末尾。
W file
写并追加模板块的第一行到file末尾。
!
表示后面的命令对所有没有被选定的行发生作用。
s/re/string
用string替换正则表达式re。
=
打印当前行号码。
#
把注释扩展到下一个换行符以前。
以下的是替换标记
*
g表示行内全面替换。
*
p表示打印行。
*
w表示把行写入一个文件。
*
x表示互换模板块中的文本和缓冲区中的文本。
*
y表示把一个字符翻译为另外的字符(但是不用于正则表达式)
4. 选项
-e command, --expression=command
允许多台编辑。
-h, --help
打印帮助,并显示bug列表的地址。
-n, --quiet, --silent
取消默认输出。
-f, --filer=script-file
引导sed脚本文件名。
-V, --version
打印版本和版权信息。
5. 元字符集^
锚定行的开始 如:/^sed/匹配所有以sed开头的行。
$
锚定行的结束 如:/sed$/匹配所有以sed结尾的行。
.
匹配一个非换行符的字符 如:/s.d/匹配s后接一个任意字符,然后是d。
*
匹配零或多个字符 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[]
匹配一个指定范围内的字符,如/[Ss]ed/匹配sed和Sed。
[^]
匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\)
保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
&
保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\<
锚定单词的开始,如:/\<love/匹配包含以love开头的单词的行。
\>
锚定单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\}
重复字符x,m次,如:/0\{5\}/匹配包含5个o的行。
x\{m,\}
重复字符x,至少m次,如:/o\{5,\}/匹配至少有5个o的行。
x\{m,n\}
重复字符x,至少m次,不多于n次,如:/o\{5,10\}/匹配5--10个o的行。
6. 实例
删除:d命令
*
$ sed '2d' example-----删除example文件的第二行。
*
$ sed '2,$d' example-----删除example文件的第二行到末尾所有行。
*
$ sed '$d' example-----删除example文件的最后一行。
*
$ sed '/test/'d example-----删除example文件所有包含test的行。
替换:s命令
*
$ sed 's/test/mytest/g' example-----在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。
*
$ sed -n 's/^test/mytest/p' example-----(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
*
$ sed 's/^192.168.0.1/&localhost/' example-----&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。
*
$ sed -n 's/\(love\)able/\1rs/p' example-----love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。
*
$ sed 's#10#100#g' example-----不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
选定行的范围:逗号
*
$ sed -n '/test/,/check/p' example-----所有在模板test和check所确定的范围内的行都被打印。
*
$ sed -n '5,/^test/p' example-----打印从第五行开始到第一个包含以test开始的行之间的所有行。
*
$ sed '/test/,/check/s/$/sed test/' example-----对于模板test和west之间的行,每行的末尾用字符串sed test替换。
多点编辑:e命令
*
$ sed -e '1,5d' -e 's/test/check/' example-----(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用check替换test。命令的执 行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
*
$ sed --expression='s/test/check/' --expression='/love/d' example-----一个比-e更好的命令是--expression。它能给sed表达式赋值。
从文件读入:r命令
*
$ sed '/test/r file' example-----file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
写入文件:w命令
*
$ sed -n '/test/w file' example-----在example中所有包含test的行都被写入file里。
追加命令:a命令
*
$ sed '/^test/a\\--->this is a example' example<-----'this is a example'被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。
插入:i命令
$ sed '/test/i\\
new line
-------------------------' example
如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。
下一个:n命令
*
$ sed '/test/{ n; s/aa/bb/; }' example-----如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。
变形:y命令
*
$ sed '1,10y/abcde/ABCDE/' example-----把1--10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。
退出:q命令
*
$ sed '10q' example-----打印完第10行后,退出sed。
保持和获取:h命令和G命令
*
$ sed -e '/test/h' -e '$G example-----在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保 持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中 的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h命令和x命令
*
$ sed -e '/test/h' -e '/check/x' example -----互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。
7. 脚本
Sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
linux下AWK使用总结
AWK 实用工具带有其自己的自包含语言,它不仅是 Linux 中也是任何环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言(其名称得自于它的创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母)的最大功能取决于一个人所拥有的知识。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报 表,还有无数其他的功能。
AWK 是什么?
最简单地说,AWK 是一种用于处理文本的编程语言工具。AWK 实用工具的语言在很多方面类似于 shell 编程语言,尽管 AWK 具有完全属于其本身的语法。在最初创造 AWK 时,其目的是用于文本处理,并且这种语言的基础是,只要在输入数据中有模式匹配,就执行一系列指令。该实用工具扫描文件中的每一行,查找与命令行中所给定 内容相匹配的模式。如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行。
尽管操作可能会很复杂,但命令的语法始终是:
awk '{pattern + action}' {filenames} 其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号 ({}) 不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。
了解字段
实用工具将每个输入行分为记录和字段。记录是单行的输入,而每条记录包含若干字段。默认的字段分隔符是空格或制表符,而记录的分隔符是换行。虽然在默认情况下将制表符和空格都看作字段分隔符(多个空格仍然作为一个分隔符),但是可以将分隔符从空格改为任何其它字符。
为了进行演示,请查看以下保存为 emp_names 的员工列表文件:
46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AR46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN当 AWK 读取输入内容时,整条记录被分配给变量 $0。每个字段以字段分隔符分开,被分配给变量 $1、$2、$3 等等。一行在本质上可以包含无数个字段,通过字段号来访问每个字段。因此,命令
awk '{print $1,$2,$3,$4,$5}' names将会产生的打印输出是
46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AR46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN值得注意的一项重要内容是,AWK 解释由空格分隔的五个字段,但当它打印显示内容时,在每个字段间只有一个空格。利用为每个字段指定了唯一号码的功能,您可以选择只打印特定的字段。例如,只打印每条记录的姓名时,只需选择第二个和第三个字段进行打印:
$ awk '{print $2,$3}' emp_namesDULANEY EVANDURHAM JEFFSTEEN BILLFELDMAN EVANSWIM STEVEBOGUE ROBERTJUNE MICAHKANE SHERYLWOOD WILLIAMFERGUS SARAHBUCK SARAHTUTTLE BOB$您还可以指定按任何顺序打印字段,而无论它们在记录中是如何存在的。因此,只需要显示姓名字段,并且使其顺序颠倒,先显示名字再显示姓氏:
$ awk '{print $3,$2}' emp_namesEVAN DULANEYJEFF DURHAMBILL STEENEVAN FELDMANSTEVE SWIMROBERT BOGUEMICAH JUNESHERYL KANEWILLIAM WOODSARAH FERGUSSARAH BUCKBOB TUTTLE$使用模式
通过包含一个必须匹配的模式,您可以选择只对特定的记录而不是所有的记录进行操作。模式匹配的最简单形式是搜索,其中要匹配的项目被包含在斜线 (/pattern/) 中。例如,只对那些居住在阿拉巴马州的员工执行前面的操作:
$ awk '/AL/ {print $3,$2}' emp_namesEVAN DULANEYJEFF DURHAMBILL STEENEVAN FELDMANSTEVE SWIM$如果您不指定要打印的字段,则会打印整个匹配的条目:
$ awk '/AL/' emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL$对同一数据集的多个命令可以用分号 (;) 分隔开。例如,在一行中打印姓名,而在另一行中打印城市和州名:
$ awk '/AL/ {print $3,$2 ; print $4,$5}' emp_namesEVAN DULANEYMOBILE ALJEFF DURHAMMOBILE ALBILL STEENMOBILE ALEVAN FELDMANMOBILE ALSTEVE SWIMUNKNOWN AL$如果没有使用分号 (print $3,$2,$4,$5),则会在同一行中显示所有内容。另一方面,如果分别给出两个打印语句,则会产生完全不同的结果:
$ awk '/AL/ {print $3,$2} {print $4,$5}' emp_namesEVAN DULANEYMOBILE ALJEFF DURHAMMOBILE ALBILL STEENMOBILE ALEVAN FELDMANMOBILE ALSTEVE SWIMUNKNOWN ALPHOENIX AZPHOENIX AZUNKNOWN ARMUNCIE INMUNCIE INMUNCIE INMUNCIE IN$只有在列表中找到 AL 时才会给出字段三和字段二。但是,字段四和字段五是无条件的,始终打印它们。只有第一组花括号中的命令对前面紧邻的命令 (/AL/) 起作用。
结果非常不便于阅读,可以使其稍微更清晰一些。首先,在城市与州之间插入一个空格和逗号。然后,在每两行显示之后放置一个空行:
$ awk '/AL/ {print $3,$2 ; print $4", "$5"\n"}' emp_namesEVAN DULANEYMOBILE, ALJEFF DURHAMMOBILE, ALBILL STEENMOBILE, ALEVAN FELDMANMOBILE, ALSTEVE SWIMUNKNOWN, AL$在第四和第五个字段之间,添加一个逗号和一个空格(在引号之间),在第五个字段后面,打印一个换行符 (\n)。在 AWK 打印语句中还可以使用那些可在 echo 命令中使用的所有特殊字符,包括:
\n(换行)
\t(制表)
\b(退格)
\f(进纸)
\r(回车)
因此,要读取全部五个最初由制表符分隔开的字段,并且也利用制表符打印它们,您可以编程如下
$ awk '{print $1"\t"$2"\t"$3"\t"$4"\t"$5}' emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AR46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN$通过连续设置多项标准并用管道 (|) 符号将其分隔开,您可以一次搜索多个模式匹配:
$ awk '/AL|IN/' emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN$这样可找到每个阿拉巴马州和印第安那州居民的匹配记录。但是在试图找出居住在亚利桑那州的人时,出现了一个问题:
$ awk '/AR/' emp_names46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AZ46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN$员工 46026 和 46027 没有住在亚利桑那州;但是他们的名字中包含所搜索的字符序列。切记,当在 AWK 中进行模式匹配时,例如 grep、sed 或者大部分其他 Linux/Unix 命令,将在记录(行)中的任何位置查找匹配,除非指定进行其他操作。为解决这一问题,必须将搜索与特定字段联系起来。通过利用代字号 (˜) 以及对特定字段的说明,可以达到这一目的,如下例所示:
$ awk '$5 ˜ /AR/' emp_names46019 BOGUE ROBERT PHOENIX AZ46021 JUNE MICAH PHOENIX AZ46022 KANE SHERYL UNKNOWN AZ$代字号(表示匹配)的对应符号是一个前面带有感叹号的代字号 (!˜)。这些字符通知程序,如果搜索序列没有出现在指定字段中,则找出与搜索序列相匹配的所有行:
$ awk '$5 !˜ /AR/' names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL46017 FELDMAN EVAN MOBILE AL46018 SWIM STEVE UNKNOWN AL46024 WOOD WILLIAM MUNCIE IN46026 FERGUS SARAH MUNCIE IN46027 BUCK SARAH MUNCIE IN46029 TUTTLE BOB MUNCIE IN$在这种情况下,将显示第五个字段中没有 AR 的所有行 — 包括两个 Sarah 条目,这两个条目确实包含 AR,但却是在第三个字段而不是第五个字段中。
花括号和字段分隔符
括号字符在 AWK 命令中起着很重要的作用。出现在括号之间的操作指出将要发生什么以及何时发生。当只使用一对括号时:
{print $3,$2}括号间的所有操作同时发生。当使用多于一对的括号时:
{print $3}{print $2}执行第一组命令,在该命令完成后执行第二组命令。注意以下两列清单的区别:
$ awk '{print $3,$2}' namesEVAN DULANEYJEFF DURHAMBILL STEENEVAN FELDMANSTEVE SWIMROBERT BOGUEMICAH JUNESHERYL KANEWILLIAM WOODSARAH FERGUSSARAH BUCKBOB TUTTLE$$ awk '{print $3}{print $2}' namesEVANDULANEYJEFFDURHAMBILLSTEENEVANFELDMANSTEVESWIMROBERTBOGUEMICAHJUNESHERYLKANEWILLIAMWOODSARAHFERGUSSARAHBUCKBOBTUTTLE$要利用多组括号进行重复查找,执行第一组中的命令直到完成为止;然后处理第二组命令。如果有第三组命令, 则在第二组命令完成后执行它,以此类推。在所生成的打印输出中,有两个分隔的打印命令,因此先执行第一个命令,随后执行第二个命令,这样导致每个条目显示 在两行而不是一行中。
区分两个字段的字段分隔符不一定始终是空格;它可以是任何可识别的字符。为进行演示,假定 emp_names 文件利用冒号而不是制表符来分隔字段:
$ cat emp_names46012:DULANEY:EVAN:MOBILE:AL46013:DURHAM:JEFF:MOBILE:AL46015:STEEN:BILL:MOBILE:AL46017:FELDMAN:EVAN:MOBILE:AL46018:SWIM:STEVE:UNKNOWN:AL46019:BOGUE:ROBERT:PHOENIX:AZ46021:JUNE:MICAH:PHOENIX:AZ46022:KANE:SHERYL:UNKNOWN:AR46024:WOOD:WILLIAM:MUNCIE:IN46026:FERGUS:SARAH:MUNCIE:IN46027:BUCK:SARAH:MUNCIE:IN46029:TUTTLE:BOB:MUNCIE:IN$如果试图通过指定所需要的第二个字段来打印姓氏
$ awk '{print $2}' emp_names您最后会得到十二个空行。因为文件中没有空格,除了第一个字段之外没有可认别的字段。为解决这一问题,必须通知 AWK 是空格之外的另一个字符作为分隔符,有两种方法可通知 AWK 使用新的字段分隔符:使用命令行参数 -F,或在程序中指定变量 FS。两种方法的效果相同,只有一种例外情况,如下例所示:
$ awk '{FS=":"}{print $2}' emp_namesDURHAMSTEENFELDMANSWIMBOGUEJUNEKANEWOODFERGUSBUCKTUTTLE$$ awk -F: '{print $2}' emp_namesDULANEYDURHAMSTEENFELDMANSWIMBOGUEJUNEKANEWOODFERGUSBUCKTUTTLE$在第一个命令中,头一条记录返回不正确的空行,而其他结果正确。直到读取第二条记录时,才识别字段分隔符并正确地执行。通过使用 BEGIN 语句可以纠正这一缺点(在后文详述)。-F 的功能非常类似于 BEGIN,能够正确地读取第一条记录并按要求执行。
在本文开始处我曾提到,默认的显示/输出字段分隔符是空格。通过使用输出字段分隔符 (OFS) 变量,可以在程序中更改此特性。例如,要读取文件(由冒号分隔)并以短划线显示,则命令是
$ awk -F":" '{OFS="-"}{print $1,$2,$3,$4,$5}' emp_names46012-DULANEY-EVAN-MOBILE-AL46013-DURHAM-JEFF-MOBILE-AL46015-STEEN-BILL-MOBILE-AL46017-FELDMAN-EVAN-MOBILE-AL46018-SWIM-STEVE-UNKNOWN-AL46019-BOGUE-ROBERT-PHOENIX-AZ46021-JUNE-MICAH-PHOENIX-AZ46022-KANE-SHERYL-UNKNOWN-AR46024-WOOD-WILLIAM-MUNCIE-IN46026-FERGUS-SARAH-MUNCIE-IN46027-BUCK-SARAH-MUNCIE-IN46029-TUTTLE-BOB-MUNCIE-IN$FS 和 OFS 是(输入)字段分隔符和输出字段分隔符,它们只是一对可以在 AWK 实用工具中使用的变量。例如,要在打印时为每行编号,可以采用以下方式使用 NR 变量:
$ awk -F":" '{print NR,$1,$2,$3}' emp_names1 46012 DULANEY EVAN2 46013 DURHAM JEFF3 46015 STEEN BILL4 46017 FELDMAN EVAN5 46018 SWIM STEVE6 46019 BOGUE ROBERT7 46021 JUNE MICAH8 46022 KANE SHERYL9 46024 WOOD WILLIAM10 46026 FERGUS SARAH11 46027 BUCK SARAH12 46029 TUTTLE BOB$找出员工号码处于 46012 和 46015 之间的所有行:
$ awk -F":" '/4601[2-5]/' emp_names46012 DULANEY EVAN MOBILE AL46013 DURHAM JEFF MOBILE AL46015 STEEN BILL MOBILE AL$添加文本
可以按照添加控制序列或其他字符的相同方式将文本添加到显示中。例如,要将分隔符从空格改为冒号,则命令是
awk '{print $1":"$2":"$3":"$4":"$5}' emp_names > new_emp_names在这种情况下,字符 (:) 包含在引号 ("/") 中,它被添加到每个字段之间。在引号之间的值可以是任何内容。例如,创建一个关于居住在阿拉巴马州的员工的外观类似数据库的显示:
$ awk '$5 ~ /AL/ {print "NAME: "$2", "$3"\nCITY-STATE: "$4", "$5"\n"}' emp_namesNAME: DULANEY, EVANCITY-STATE: MOBILE, ALNAME: DURHAM, JEFFCITY-STATE: MOBILE, ALNAME: STEEN, BILLCITY-STATE: MOBILE, ALNAME: FELDMAN, EVANCITY-STATE: MOBILE, ALNAME: SWIM, STEVECITY-STATE: UNKNOWN, AL$数学操作
AWK 除了提供文本功能,还提供全部范围的算术操作符,包括以下符号:
+ 将数字相加
- 减
* 乘
/ 除
^ 执行指数运算
% 提供模
++ 将变量值加一
+= 将其他操作的结果分配给变量
— 将变量减一
-= 将减法操作的结果分配给变量
*= 分配乘法操作的结果
/= 分配除法操作的结果
%= 分配求模操作的结果
例如,假定您的机器上存在以下的文件,详细地列出硬件商店中的物品:
$ cat inventoryhammers 5 7.99drills 2 29.99punches 7 3.59drifts 2 4.09bits 55 1.19saws 123 14.99nails 800 .19screws 80 .29brads 100 .24$第一项业务定单是通过将第二个字段(数量)的值乘以第三个字段(价格)的值,计算每种物品的库存价值:
$ awk '{print $1,"QTY: "$2,"PRICE: "$3,"TOTAL: "$2*$3}' inventoryhammers QTY: 5 PRICE: 7.99 TOTAL: 39.95drills QTY: 2 PRICE: 29.99 TOTAL: 59.98punches QTY: 7 PRICE: 3.59 TOTAL: 25.13drifts QTY: 2 PRICE: 4.09 TOTAL: 8.18bits QTY: 55 PRICE: 1.19 TOTAL: 65.45saws QTY: 123 PRICE: 14.99 TOTAL: 1843.77nails QTY: 800 PRICE: .19 TOTAL: 152screws QTY: 80 PRICE: .29 TOTAL: 23.2brads QTY: 100 PRICE: .24 TOTAL: 24$如果这些行本身并不重要,您只是希望确定商店中有多少件物品,则可以分配一个普通变量,按照每条记录中的物品数量增加:
$ awk '{x=x+$2} {print x}' inventory5714167119499410741174$根据这一数据,商店中有 1174 件物品。第一次执行时,变量 x 没有值,因此它采用第一行第二个字段的值。第二次执行时,它保留了第一行的值并加上第二行的值,以此类推,直到达到累计的总合。
可以应用相同的过程来确定现有库存的总价值:
$ awk '{x=x+($2*$3)} {print x}' inventory39.9599.93125.06133.24198.692042.462194.462217.662241.66$因此,1174 件物品的价值是 $2,241.66。虽然这一过程可以获得总计值,但它的外观很差,需要加工成实际的报表。利用一些附加项,很容易使显示变得更整洁:
$ awk '{x=x+($2*$3)}{print $1,"QTY: "$2,"PRICE: "$3,"TOTAL: "$2*$3,"BAL: "x}' inventoryhammers QTY: 5 PRICE: 7.99 TOTAL: 39.95 BAL: 39.95drills QTY: 2 PRICE: 29.99 TOTAL: 59.98 BAL: 99.93punches QTY: 7 PRICE: 3.59 TOTAL: 25.13 BAL: 125.06drifts QTY: 2 PRICE: 4.09 TOTAL: 8.18 BAL: 133.24bits QTY: 55 PRICE: 1.19 TOTAL: 65.45 BAL: 198.69saws QTY: 123 PRICE: 14.99 TOTAL: 1843.77 BAL: 2042.46nails QTY: 800 PRICE: .19 TOTAL: 152 BAL: 2194.46screws QTY: 80 PRICE: .29 TOTAL: 23.2 BAL: 2217.66brads QTY: 100 PRICE: .24 TOTAL: 24 BAL: 2241.66$该过程提供了每条记录的清单,同时将总价值分配给库存值,并保持商店资产的运作平衡。
BEGIN 和 END
使用 BEGIN 和 END 语句可以分别指定在处理实际开始之前或者完成之后进行操作。BEGIN 语句最常用于建立变量或显示标题。另一方面,END 语句可用于在程序结束后继续进行处理。
在前面的示例中,利用以下例程生成了物品的总价值:
awk '{x=x+($2*$3)} {print x}' inventory该例程在运行总计累加时显示了文件中的每一行。没有其他方法可以指定它,而不让在每一行进行打印也导致它始终不打印出来。但是,利用 END 语句可以避免这一问题:
$ awk '{x=x+($2*$3)} END {print "Total Value of Inventory:"x}' inventoryTotal Value of Inventory: 2241.66$定义了变量 x,它对每一行进行处理;但是,在所有处理完成之前不会生成显示。尽管可以作为独立例程使用,它也可以置入到先前的代码列表,添加更多信息并生成更完整的报表:
$ awk '{x=x+($2*$3)} {print $1,"QTY: "$2,"PRICE: "$3,"TOTAL: "$2*$3} END {print "Total Value of Inventory: " x}' inventoryhammers QTY: 5 PRICE: 7.99 TOTAL: 39.95drills QTY: 2 PRICE: 29.99 TOTAL: 59.98punches QTY: 7 PRICE: 3.59 TOTAL: 25.13drifts QTY: 2 PRICE: 4.09 TOTAL: 8.18bits QTY: 55 PRICE: 1.19 TOTAL: 65.45saws QTY: 123 PRICE: 14.99 TOTAL: 1843.77nails QTY: 800 PRICE: .19 TOTAL: 152screws QTY: 80 PRICE: .29 TOTAL: 23.2brads QTY: 100 PRICE: .24 TOTAL: 24Total Value of Inventory: 2241.66$BEGIN 命令与 END 的工作方式相同,但它建立了那些需要在完成其他工作之前所做的项目。该过程最常见的目的是创建报表的标题。此例程的语法类似于
$ awk 'BEGIN {print "ITEM QUANTITY PRICE TOTAL"}'输入、输出和源文件
AWK 工具可以从文件中读取其输入,正如在此之前所有示例所做的那样,它也可以从其他命令的输出中获取输入。例如:
$ sort emp_names | awk '{print $3,$2}'awk 命令的输入是排序操作的输出。除了 sort,还可以使用任何其他的 Linux 命令 — 例如 grep。该过程允许您在离开所选定字段前对文件执行其他操作。
类似于解释程序,AWK 使用输出改向操作符 > 和 >> 将其输出放入文件中而不是标准输出设备。这些符号的作用类似于它们在解释程序中的对应符号,因此 > 在不存在文件时创建文件,而 >> 追加到现有文件的尾部。请看以下的示例:
$ awk '{print NR, $1 ) > "/tmp/filez" }' emp_names$ cat /tmp/filez1 460122 460133 460154 460175 460186 460197 460218 460229 4602410 4602611 4602712 46029$检查该语句的语法,您会看到输出改向是在打印语句完成后进行的。必须将文件名包含在引号中,否则它只是一 个未初始化的 AWK 变量,而将指令联接起来会在 AWK 中产生错误。(如果不正确地使用改向符号,则 AWK 无法了解该符号意味着“改向”还是一个关系操作符。)
在 AWK 中输出到管道也类似于解释程序中所实现的相同操作。要将打印命令的输出发送到管道中,可以在打印命令后附加管道符号以及命令的名称,如下所示:
$ awk '{ print $2 | "sort" }' emp_namesBOGUEBUCKDULANEYDURHAMFELDMANFERGUSJUNEKANESTEENSWIMTUTTLEWOOD$这是输出改向的情况,必须将命令包含在引号中,而管道的名称是被执行命令的名称。
AWK 所使用的命令可以来自两个地方。首先,可以在命令行中指定它们,如示例中所示。其次,它们可以由源文件提供。如果是这种情况,通过 -f 选项将这种情况向 AWK 发出警告。演示如下:
$ cat awklist{print $3,$2}{print $4,$5,"\n"}$$ awk -f awklist emp_namesEVAN DULANEYMOBILE ALJEFF DURHAMMOBILE ALBILL STEENMOBILE ALEVAN FELDMANMOBILE ALSTEVE SWIMUNKNOWN ALROBERT BOGUEPHOENIX AZMICAH JUNEPHOENIX AZSHERYL KANEUNKNOWN ARWILLIAM WOODMUNCIE INSARAH FERGUSMUNCIE INSARAH BUCKMUNCIE INBOB TUTTLEMUNCIE IN$注意,在源文件中的任何地方或者在命令行中调用它时,不使用单引号。单引号只用于区别命令行中的命令与文件名称。
如果简单的输出不能处理您的程序中所需要的复杂信息,则可以尝试由 printf 命令获得的更加复杂的输出,其语法是
printf( format, value, value ...)该语法类似于 C 语言中的 printf 命令,而格式的规格是相同的。通过插入一项定义如何打印数值的规格,可以定义该格式。格式规格包含一个跟有字母的 %。类似于打印命令,printf 不必包含在圆括号中,但是可以认为使用圆括号是一种良好的习惯。
下表列出 printf 命令提供的各种规格。
规格 说明
%c 打印单个 ASCII 字符
%d 打印十进制数
%e 打印数字的科学计数表示
%f 打印浮点表示
%g 打印 %e 或 %f;两种方式都更简短
%o 打印无符号的八进制数
s 打印 ASCII 字符串
%x 打印无符号的十六进制数
%% 打印百分号;不执行转换
可以在 % 与字符之间提供某些附加的格式化参数。这些参数进一步改进数值的打印方式:
参数 说明
- 将字段中的表达式向左对齐
,width 根据需要将字段补齐到指定宽度(前导零使用零将字段补齐)
.prec 小数点右面数字的最大字符串宽度或最大数量
printf 命令能够控制并将数值从一种格式转换为另一种格式。当需要打印变量的值时,只需提供一种规格,指示 printf 如何打印信息(通常包含在双引号中)即可。必须为每个传递到 printf 的变量包含一个规格参数;如果包含过少的参数,则 printf 不会打印所有的数值。
处理错误
AWK 工具报告所发生错误的方式很令人恼火。一个错误会阻碍任何操作的进行,所提供的错误信息非常含混不清:
awk: syntax error near line 2awk: bailing out near line 2您可能会花几小时的时间查看第 2 行,试图找出它为什么阻碍程序运行;这就是支持使用源文件的一个有力论据。
切记有两条规则可以帮助您避免出现语法错误:
1. 确保命令位于括号中,而括号位于单引号中。没有使用这些字符之一必然导致程序无法运行。
2. 搜索命令需要位于斜线之间。要找出住在印第安那州的员工,您必须使用“/IN/”而不是“IN”。
结论
尽管 AWK 完全代表另外的含意,但它应该是管理员智能工具包的首字母缩写。连同 SED 一起,AWK 实用工具是 Linux 管理员所拥有的功能最强大和灵活的工具之一。通过了解其语言的一些特性,您可以开辟出能够简化任务的领域,否则这些任务将会是非常费时和困难的。
linux服务器在运转过程中,总要监控一些性能方面的东西,比如磁盘、CPU、内存的使用,以及网络的性能之类的,下面是一些监控方法:
linux系统性能监控
1、进程
- (1)top
- (2)ps
- 找出前10个最多占用系统内存的进程
- # ps -auxf | sort -nr -k 4 | head -10
- 找出前10个最多占用CPU资源的进程
- # ps -auxf | sort -nr -k 3 | head -10
- (3)查看进程下面的线程
- 总数 ps huH p <PID> | wc -l
- 某个的详情 ps huH p <PID>
- 或者查看这个目录 /proc/<pid>/task
2、系统相关
- (1)vmstat(vmstat 命令报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息)
- (2)uptime (系统运行时间)
- (3)sar -A(帮助我们掌握系统资源的使用情况,特别是内存和CPU 的使用情况)
- (4)/proc
- 系统关键参数
- # cat /proc/cpuinfo
- # cat /proc/meminfo
- # cat /proc/zoneinfo
- # cat /proc/mounts
- (5)查看系统调用
- strace(跟踪程式执行时的系统调用和所接收的信号)
- strace cat /dev/null
- strace的每一行输出包括系统调用名称,然后是参数和返回值
3、cpu
- iostat (cpu平均负载、磁盘)
- mpstat cpu状况
4、磁盘
- iostat
- iotop
5、内存
- (1)free
- (2)pmap + pid (进程的内存消耗)
6、网络状态
- netstat ss iptraf(实时网络状况)
- sudo tcpdump -i eth0(监控某个设备的网络请求)
7、查看用户
- w