【三维感知目标检测论文阅读】《Point RCNN: An Angle-Free Framework for Rotated Object Detection》
今天给大家带来的论文是2019年的《Point RCNN: An Angle-Free Framework for Rotated Object Detection》。尽管这是一篇较早的纯点云检测论文,但我把它放在了最后来讲。因为在了解了各类主流方法后,再回过头来阅读它会有更深的理解。Point RCNN采用自底向上的方式直接从点云生成高质量的3D候选框,其对于旋转框的无角度(Angle-Free)处理方式,对于理解3D边界框的表示和优化问题具有深刻的启发意义,可以帮助我们在更高层次上反思3D检测的核心难点。
论文链接:Point RCNN: An Angle-Free Framework for Rotated Object Detection
首先需要特别指出,这篇论文的应用领域是二维(2D)遥感影像(aerial images)中的旋转目标检测,而不是前面几篇论文所关注的自动驾驶场景中的三维(3D)点云检测。这里的“Point”指的是“代表点”(Representative Points),是一种2D特征点表示,注意不要与3D点云(Point Cloud)中的“PointRCNN”混淆。
1. 论文概述 (Overview)
这篇论文旨在解决遥感影像中旋转目标检测的核心难题。由于航拍视角,物体具有任意方向、巨大的尺度和长宽比变化,且常常密集排列 。现有的SOTA方法大多是基于角度(angle-based)的,即通过回归 (x, y, w, h, θ) 五个参数来定义旋转框。然而,这种方法长期受到一个“边界不连续性问题”(boundary discontinuity problem)的困扰 。
为解决此问题,论文提出了一个纯粹的无角度(angle-free)框架,名为Point RCNN 。它是一个两阶段检测器,由无角度的PointRPN(用于生成候选框)和PointReg(用于精细优化)组成 。其核心思想是,不直接回归角度,而是通过学习物体的“代表点”和“角点”来间接定义和优化旋转框,从而规避角度回归带来的问题。
此外,论文还针对遥感数据集中常见的类别不均衡问题,提出了一个均衡数据集策略,通过对稀有类别图像进行重采样来稳定训练过程并提升性能 。最终,该方法在DOTA、HRSC2016等多个大型遥感影像数据集上取得了SOTA的性能 。
2. 背景与动机:旋转目标检测中的“角度”难题
在旋转目标检测中,如何表示一个旋转框是核心问题。
-
基于角度的表示法:通常使用
(x, y, w, h, θ)五个参数,其中θ表示旋转角 。这种方法虽然直观,但存在一个致命缺陷——边界不连续性。如下图所示,对于一个近乎正方形的物体,当其
w和h的定义因为微小的变化而互换时,θ的值会发生90度的跳变 。这种突变会“迷惑”网络的学习过程,导致训练不稳定,限制了模型的精度上限。
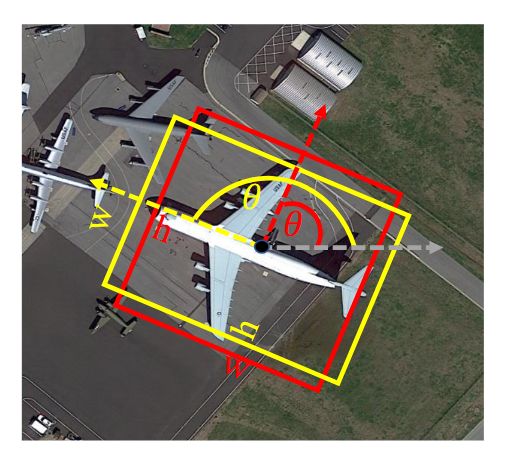
- 无角度的表示法:为了规避上述问题,另一条技术路线是直接回归旋转框的四个角点坐标
(x1, y1, ..., x4, y4)。这种方式更直接,且参数单位统一,但当时已有的无角度方法性能相对有限 。
核心动机:设计一个更有效、更直接的纯无角度框架,以彻底解决角度回归带来的边界问题,并提升旋转目标的检测性能 。
3. Point RCNN 模型详解
Point RCNN是一个两阶段的检测器,其整体流程如下图所示。
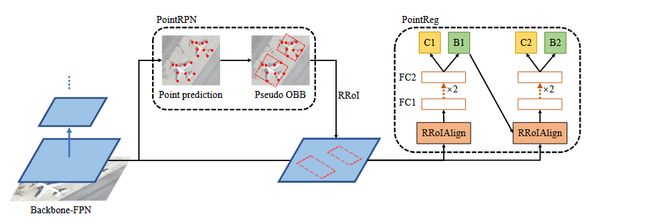
3.1. 第一阶段:PointRPN (生成旋转候选框)
PointRPN是一个无锚框(anchor-free)且无角度的区域提案网络,其目标是生成高质量的旋转候选框(Rotated Region of Interests, RRoI)。
-
代表点学习 (Representative Points Prediction):受到RepPoints的启发,PointRPN的核心任务是学习一组(默认为9个)能够有效描述物体形状和姿态的代表点 。它采用了一个从粗到精(coarse-to-fine)的过程:
-
初始阶段:网络首先预测一组初步的代表点偏移量。
-
优化阶段:利用初始阶段预测的偏移量,通过**可变形卷积(Deformable Convolution)**对特征图进行对齐和优化,然后再预测一组更精确的代表点偏移量,得到最终的代表点集 。
-
-
从代表点到RRoI:在得到一组代表点后,PointRPN并不直接回归框的参数。而是通过调用OpenCV中的
MinAreaRect函数,计算出能够包围这组代表点的最小面积矩形 。这个矩形就被用作一个高质量的、无角度生成的RRoI。这一步非常巧妙,将点的表示转换为了框的表示。
3.2. 第二阶段:PointReg (优化旋转边界框)
PointReg是RCNN的检测头,负责对PointRPN生成的RRoI进行分类和精细优化。
-
角点回归 (Corner Points Refine):PointReg同样采用无角度设计。对于输入的RRoI,它首先通过RRoIAlign提取特征,然后通过两个全连接层(FC)进行编码 。最后,网络直接回归该RRoI 四个角点的偏移量,从而得到一个更精确的旋转框 。
-
级联结构:这种“优化角点”的过程可以级联进行。即将第一级优化后的框作为第二级的输入,进行再次优化,以达到更高的精度 。
3.3. 均衡数据集策略 (Balanced Dataset Strategy)
遥感影像数据集经常存在严重的长尾分布问题,即某些类别(如舰船)的实例数量远多于其他类别(如田径场) 。这会导致模型在训练时偏向于常见类别。为解决此问题,论文提出了一种重采样(re-sampling)策略:
-
首先,计算数据集中每个类别
c在多少比例的图像中出现过,记为Fc。 -
然后,根据一个阈值
β_thr计算每个类别的重复采样因子rc。Fc越小的稀有类别,其rc值越大 。 -
对于每张图像,其最终的重复采样因子
rI取决于它所包含的所有类别中最大的那个rc。 -
在训练时,根据
rI对图像进行重采样,使得包含稀有类别的图像有更高的概率被选中 。
实验证明,这一策略能有效稳定训练过程,并将在DOTA-v1.0上的mAP从80.37%提升至80.71% 。
4. 关键创新点
-
纯无角度框架 (Angle-Free): PointRPN 和 PointReg 都完全不涉及角度预测,从根本上规避了边界不连续问题。
-
代表点学习 (PointRPN): 通过预测一组代表点来隐式地表示旋转目标,比直接回归旋转框或使用锚框更灵活。
MinAreaRect转换提供了一种无锚框(Anchor-Free)且无角度的RRoI生成方式。 -
角点精炼 (PointReg): 直接在RCNN阶段精炼四个角点,参数单位一致,且采用由粗到精的策略。
-
平衡数据集策略 (Balanced Dataset Strategy): 针对遥感图像中常见的长尾分布问题(某些类别实例极少,如DOTA中“Ground track field” vs “Ship”)做出优化。
5. 实验结果 (SOTA Performance)
-
数据集: DOTA-v1.0, DOTA-v1.5 (更小目标、更多实例), HRSC2016 (船舶), UCAS-AOD (小目标:车、飞机)。
-
主干网络: 主要使用 ReResNet-50-ReFPN (ReDet提出的旋转等变主干),也验证了 Swin-Tiny-FPN (Transformer主干) 的通用性。
-
主要结果 (mAP):
-
DOTA-v1.0: 80.71% (ReR50-ReFPN + 平衡策略),81.32% (Swin-T-FPN),显著优于 ReDet (80.10%) 和 Oriented RCNN (80.32%)。平衡策略带来 +0.34% 提升。
-
DOTA-v1.5: 79.31% (ReR50-ReFPN + 平衡策略),80.14% (Swin-T-FPN + 平衡策略),显著提升 SOTA 约 2.5-2.86% (vs ReDet 76.80%, Oriented RCNN 76.45%)。平衡策略带来 +0.57% 提升。
-
HRSC2016 (VOC2012 metric): 98.53%,优于 ReDet (97.63%) 和 Oriented RCNN (97.60%)。
-
UCAS-AOD: 90.04%,优于 S²A-Net (89.99%) 等。
-
-
消融实验 (Ablation Studies on DOTA-v1.5):
-
PointReg 有效性: 角点回归 (8参数) 优于 带角度的5参数回归 (77.60% vs 77.25%)。
-
平衡策略有效性: 找到最佳阈值
β_thr=0.3(77.60%)。 -
各模块贡献: PointRPN (+2.81%), 平衡策略 (+0.05%, 但与其他结合效果显著), PointRPN+平衡策略 (+5.89%), 完整PointRCNN (+6.24%) 均有效提升基线 (71.36%)。
-
PointRPN 召回率 (Recall): Top-2000 proposals 可达 90.00% 召回率,证明其生成高质量RRoI的能力。
-
-
可视化: 图8展示了PointRPN学习的代表点能捕捉目标轮廓;图9-11展示了最终检测结果,验证了框架的有效性。
6. 结论 (Conclusions)
-
Point RCNN 是一个纯无角度的两阶段旋转目标检测框架。
-
核心组件是 PointRPN(学习代表点生成RRoI)和 PointReg(精炼角点)。
-
提出了平衡数据集策略缓解遥感图像的长尾问题。
-
在多个大型航空图像数据集上实现了新的SOTA性能,显著超越了之前的基于角度和无角度的方法,证明了其解决边界不连续问题的有效性和优越性。
7. 意义与展望
-
意义: 提供了一种新颖且有效的解决旋转目标检测核心挑战(边界不连续)的思路,性能显著提升。
-
局限与未来工作 (Discussion):
-
在某些类别(如DOTA中的“Plane”)性能仍有提升空间。
-
仍需依赖旋转NMS去除冗余框,可能误删正确检测。
-
未来可探索基于Transformer的端到端NMS-free方法。
-
总结: Point RCNN 通过创新的“代表点学习->RRoI生成->角点精炼”的纯无角度流程,成功规避了旋转目标检测中的边界不连续难题,并结合数据重采样策略处理长尾分布,在多个权威数据集上取得了显著的性能突破,是该领域的一项重要进展。
6篇论文核心思想与技术范式总结
至此,我们已经详细解读了6篇在3D检测/旋转检测领域具有里程碑意义的论文。它们分别代表了不同时期、不同问题域下的技术演进方向。
论文 |
核心领域 |
主要贡献 / 解决的问题 |
技术范式 |
SECOND |
LiDAR 3D检测 |
引入稀疏3D卷积,解决了VoxelNet的效率瓶颈,使3D体素方法变得实用。 |
纯体素(Voxel-based),单模态 |
PointPillars |
LiDAR 3D检测 |
提出Pillar编码器,将3D卷积完全替换为高效的2D卷积,实现了速度的巨大飞跃。 |
纯体素(Pillar也是一种Voxel),单模态 |
PV-RCNN |
LiDAR 3D检测 |
点-体素混合,通过Voxel-to-Keypoint的特征抽象,结合了体素的效率和点云的精度。 |
混合表示(Point-Voxel),单模态 |
Voxel R-CNN |
LiDAR 3D检测 |
提出高效的Voxel RoI Pooling,证明了纯体素两阶段框架也能达到SOTA精度,挑战了点云特征的必要性。 |
纯体素(Voxel-based),单模态 |
TransFusion (PKU/Alibaba) |
LiDAR-相机融合 |
关注鲁棒性,提出解耦双流架构,解决了主流融合方法对LiDAR输入的强依赖和传感器故障问题。 |
BEV空间融合,多模态 |
TransFusion (MIT/Huawei) |
LiDAR-相机融合 |
关注信息保真度,首创用Transformer进行“软关联”融合,解决了硬关联融合对标定和图像质量敏感的问题。 |
隐式查询空间融合,多模态 |
Point RCNN |
2D遥感影像旋转检测 |
关注边界不连续性,提出纯粹的无角度框架,用代表点和角点回归替代角度回归。 |
2D图像,单模态 |
那么我们对于3D目标检测领域的论文阅读暂时告一段落,后续我会将目前正在研究的模型的架构和代码理解分享给大家。