嵌入式学习-PyTorch(4)-day21
1、torchvision中数据集的使用
认识官方的一些数据集
Datasets — Torchvision 0.22 documentation
试了一下CIFAR10数据集,知道了如何下载官方数据集和展示他们去tensorboard中
import torchvision
from torch.utils.tensorboard import SummaryWriter
#处理数据集
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
#下载数据集
train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True,transform=dataset_transform, download=True)
#下载测试集
test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=dataset_transform, download=True)
#将图片显示到tensorboard上
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set", img, i)
print(test_set[0])
writer.close()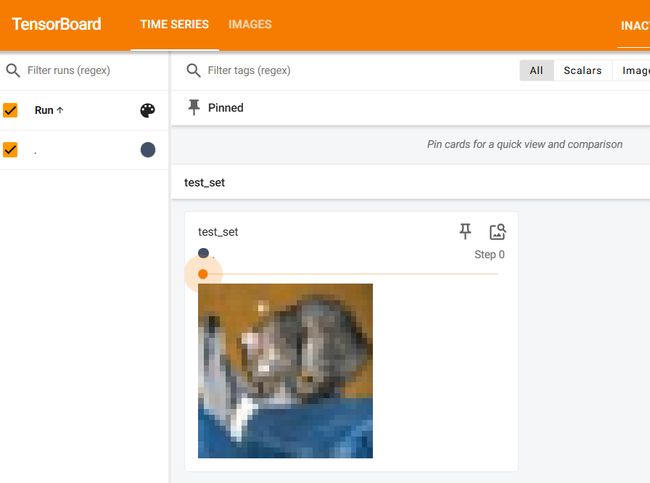
DataLoader的使用
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备测试集
test_data = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor())
#批量输入设置
test_loader = DataLoader(test_data,batch_size=64, shuffle=True,num_workers=0,drop_last=True)
#测试数据集中第一张图片及target
img ,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step = 0
for epoch in range(2):
for data in test_loader:
imgs ,targets = data
writer.add_images(f'epoch:{epoch}',imgs,step)
step += 1
# print(imgs.shape)
# print(targets)
writer.close()
DataLoader 是 PyTorch 数据加载的“管家”,用来帮你批量(batch)取数据、打乱顺序(shuffle)、多线程提速(num_workers)。
基本用法
from torch.utils.data import DataLoader
import torchvision
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=..., download=True)
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=2)
| 参数 | 作用 |
|---|---|
dataset |
传入 Dataset 对象,比如 CIFAR10 |
batch_size |
一次取多少张图片(例如 64 张一批) |
shuffle |
是否打乱顺序(True 用于训练时打乱数据) |
num_workers |
使用多少个线程加速数据读取(常见是 0、2、4,根据你电脑配置) |
小建议
-
shuffle=True训练时常开,防止模型记住样本顺序; -
shuffle=False测试时不开,保持固定顺序; -
num_workers:-
Windows:建议
0或2(多了容易报错); -
Linux:可以
4或8,CPU 核心多可以更高;
-
-
batch_size看你显存大小来选,一般 32、64 起步,爆显存就减。
神经网络的基本骨架 nn.Module
torch.nn.Module 是 PyTorch 神经网络模块的核心基类,所有的神经网络模型都应该继承自它。它帮你把模型的参数、网络层、前向传播逻辑很好地封装起来,同时提供了很多实用功能,比如参数自动管理、模块嵌套、方便的模型保存与加载等。
基本概念
作用:
-
封装网络结构
-
封装可训练参数
-
提供 forward() 方法定义前向传播
所有你写的神经网络模型都应该继承 torch.nn.Module,并且重写 __init__() 和 forward() 方法。
| 特点 | 说明 |
|---|---|
| 模块化设计 | 模型由很多子模块组成,可以嵌套 |
| 参数自动管理 | 定义 nn.Linear、nn.Conv2d 等时,参数自动注册 |
| forward() | 定义前向传播逻辑 |
| 保存加载方便 | .state_dict() 搭配 torch.save() |
-
Module就是一个“神经网络的容器 ”,把层、参数、操作逻辑统统塞进去,训练和推理时自动调用,简单省事。 -
你只负责定义“拼装逻辑”,剩下交给 PyTorch 。
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output = input + 1
return output
tudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)tudui(x) 本质上等价于 tudui.forward(x),底层走的是 __call__() 魔术方法。
先学一下什么是卷积
一、通俗解释:什么是卷积?
卷积(Convolution)本质上是一种**“滑窗提取特征”**的操作。
你可以想象:
-
有一张图片(二维矩阵),
-
有一个小的“滤镜”(也就是卷积核 kernel),
-
这个滤镜从图片的左上角滑动到右下角,
-
每次滑动的时候:
-
截取一小块图像;
-
“乘起来加起来”,输出一个特征值;
-
-
最终得到一张新的“特征图”。
类比:
-
图片 = 原始食材
-
卷积核 = 刀工+调料
-
卷积 = 切切切 ➡️ 做出不同味道的菜
二、数学定义
二维卷积的核心公式:
![]()
翻译成人话:
-
“输入的一个小窗口”和“卷积核”做对应元素相乘、求和,得到输出特征图的某个点值。
三、核心关键点
| 关键词 | 说明 |
|---|---|
| 卷积核(Kernel) | 一组小矩阵,自动学习提取特征 |
| 滑动窗口(Stride) | 每次移动多少步 |
| 填充(Padding) | 是否对原图边缘补0 |
| 特征图(Feature Map) | 卷积完得到的新“图片” |
四、为什么用卷积?
✅ 稀疏连接:只关注局部区域,计算量小
✅ 参数共享:同一个 kernel 在整张图上滑动,用的参数一样
✅ 自动特征提取:不用人工设计特征,模型自己学!
五、视觉演示(文字版)
假设你有:
输入图片:
1 2 3
4 5 6
7 8 9
卷积核:
1 0
0 -1
第一步:卷积核滑到左上角:
1×1+2×0+4×0+5×(−1)=1−5=−41×1 + 2×0 + 4×0 + 5×(-1) = 1 - 5 = -41×1+2×0+4×0+5×(−1)=1−5=−4
然后继续滑动……
输出就是一个新的小矩阵(特征图)。
总结:
“卷积是一个滑动窗口,乘加求和,输出特征的操作,用于提取局部特征,让神经网络自己学会抓重点。”
卷积对神经网络有啥用
卷积的作用用一句话总结:
“卷积帮神经网络自动提取特征,让网络看懂图片、视频、音频的局部模式。”
一、卷积的三大核心价值
| 作用 | 解释 | 通俗类比 |
|---|---|---|
| 1️⃣ 局部特征提取 | 卷积只看输入的一小块区域,能抓住边缘、纹理、角落特征 | 人眼不会每次全局看图,先看局部细节 |
| 2️⃣ 参数共享 | 一个卷积核滑遍整张图,参数大大减少(不用每个像素都单独学参数) | 用同一把尺子测量不同区域,简单省事 |
| 3️⃣ 平移不变性 | 卷积对图像的位移/平移不敏感,核心特征能被稳定抓取 | 你走到房间不同角落,认识椅子的能力不变 |
二、对神经网络的作用
| 神经网络 | 有了卷积后 | 实际表现 |
|---|---|---|
| 无卷积(全连接层) | 参数量超大,训练慢,特征难以提取 | 很难直接处理图片等高维输入 |
| 有卷积 | 参数少,学特征快,模型更稳健 | 成功应用于图像识别、目标检测、语音识别 |
三、直观例子
-
第一层卷积学:边缘、轮廓
-
第二层卷积学:角、纹理
-
第三层卷积学:简单物体形状
-
深层卷积学:复杂物体(猫脸、车轮…)
例子 ✅:
-
卷积神经网络 CNN:图片分类(ResNet、VGG)
-
YOLO/SSD:目标检测
-
U-Net/SegNet:图像分割
-
WaveNet:语音生成
✅ 四、核心总结:
| 卷积 = 特征提取神器 ✅ |
| 它让神经网络具备看懂图片、捕捉特征、少参数高效率三大核心竞争力。|
torch.nn.functional.conv2d
一、作用总结
torch.nn.functional.conv2d() = 手动卷积操作,不自动管理参数。
核心用途:
-
想手动传入卷积核 weight/bias;
-
用自定义的卷积逻辑;
-
实现轻量推理、特定卷积算法。
二、标准用法
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)三、参数详解
| 参数 | 含义 | 常见用法 |
|---|---|---|
input |
输入张量 [batch, in_channels, height, width] |
如 [1, 3, 32, 32] |
weight |
卷积核 [out_channels, in_channels // groups, kernel_h, kernel_w] |
你得自己准备 |
bias |
可选,偏置 [out_channels] |
默认 None |
stride |
步长,单个数字或 (h, w) | 默认 1 |
padding |
填充 | 默认 0,不补零 |
dilation |
卷积核膨胀系数 | 默认 1,标准卷积 |
groups |
分组卷积 | 默认 1,group conv 或 depthwise 用 |
import torch
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input,(1, 1, 5, 5))
kernel = torch.reshape(kernel ,(1, 1, 3, 3))
output = torch.nn.functional.conv2d(input, kernel,stride=1)
print(output)
结果:
E:\Anaconda3\envs\pytorch\python.exe E:\pytorch_learn\nn.conv.py
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
进程已结束,退出代码为 0stride(步长)等于2时:
E:\Anaconda3\envs\pytorch\python.exe E:\pytorch_learn\nn.conv.py
tensor([[[[10, 12],
[13, 3]]]])
进程已结束,退出代码为 0
padding就是在举证四周填充
import torch
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input,(1, 1, 5, 5))
kernel = torch.reshape(kernel ,(1, 1, 3, 3))
output = torch.nn.functional.conv2d(input, kernel,stride=1, padding=1)
print(output)
结果:
E:\Anaconda3\envs\pytorch\python.exe E:\pytorch_learn\nn.conv.py
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
进程已结束,退出代码为 0