数据结构1.2——单链表(C语言实现)
一、线性表的链式存储结构
链式存储结构:逻辑上相邻、物理上不一定相邻。
二、单链表
1.单链表的结构体设计
1.1 理解
由于单链表不要求物理上相邻,因此在设计结点时,该结点不仅需要保存自身的数据,也需要保存下一个结点的地址。所以单链表设计有效结点时,需要包含两个域:数据域、指针域(存放下一个结点的地址)。
1.2 代码实现
//单链表的结构体设计
typedef int ELEM_TYPE;
typedef struct Node{
ELEM_TYPE data;//用来存放该结点的数据
struct Node* next;//存储下一个结点的地址(指向下一个结点)
}Node,*PNode;
1.3 说明
本文章的单链表带有辅助结点,对于辅助结点也采用此结构体设计,只是不使用结点的数据域。
辅助结点在栈区申请,因此不需要malloc申请空间。
2.单链表的基本操作
2.1 单链表的初始化
1.理解:对辅助结点进行初始化(因为辅助结点在栈区,所以不需要malloc申请)
①将结点的指针域置空
②结点的数据域不作处理
2.代码设计:
void Init_list(PNode head)
{
//将结点的指针域置为空
head->next=NULL;
} 2.2 单链表的插入
2.2.1 单链表的头插
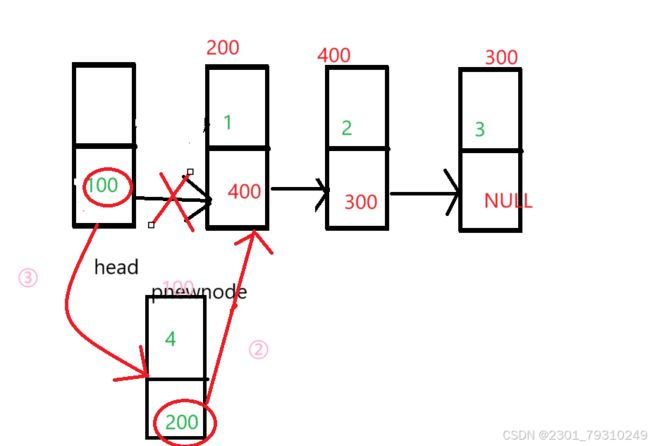
1.理解:每次插入都是在辅助结点之后插入。
①malloc申请新的结点。并对新结点赋值。
②将插入结点的指针域指向辅助结点的下一个结点。
③将辅助结点的指针域指向插入结点。
注意:②③的位置不能改变,改变后将找不到链表的剩余结点。
2.代码实现:
bool Insert_head(PNode head,ELEM_TYPE val)
{
//malloc申请新结点,并判断结点是否申请成功 ,申请成功后赋值
struct Node*pnewnode=(struct Node*)malloc(sizeof(struct Node));
if(pnewnode==NULL)
exit(1);
pnewnode->data=val;
pnewnode->next=NULL;
//先改变插入结点的指向
pnewnode->next=head->next;
//改变辅助结点的指向
head->next=pnewnode;
return true;
} 3.说明:
因为头插每次都是在辅助结点之后插入(可理解为第一个位置),所以打印出来的结果通常是逆置的。
eg:
插入顺序:1、2、3、4
输出顺序:4、3、2、1
2.2.2 单链表的尾插
1.理解:插入位置在最后一个结点之后。
①malloc申请新的结点。并对新结点赋值。
②找插入位置:从辅助结点出发,遍历链表至尾结点。(因为插入操作要改变插入位置前一个结点的指针域,所以需要先找到插入位置的前驱结点)
③先修改插入结点的指针域:插入结点的指针域指向前驱结点的后继结点。
④修改前驱结点的指针域:使其指向插入结点。

2.代码实现:
bool Insert_tail(PNode head,ELEM_TYPE val)
{
//malloc申请新结点,并判断结点是否申请成功 ,申请成功后赋值
struct Node*pnewnode=(struct Node*)malloc(sizeof(struct Node));
if(pnewnode==NULL)
exit(1);
pnewnode->data=val;
pnewnode->next=NULL;
//找插入位置:遍历至尾结点
PNode* p=head;
for(;p->next!=NULL;p=p->next) ;
//先改变插入结点的指向
pnewnode->next=p->next;
//改变辅助结点的指向
p->next=pnewnode;
return true;
} 2.2.3 单链表的按位置插
1.理解:根据指定的位置插入结点。
①malloc申请新的结点,并对新节点赋值。
②找插入位置:
先判断插入位置是否合法(此处的合法位置从0开始,到链表长度。[0,length])
合法则再找到插入位置的前驱结点。
③修改插入结点的指针域:将插入结点指向前驱结点的后继结点。
⑤修改前驱结点的指针域:使其指向插入结点。

2.代码实现:
bool Insert_Pos(PNode head,ELEM_TYPE val,int pos)
{
struct Node*pnewnode=(struct Node*)malloc(sizeof(struct Node));
if(pnewnode==NULL)
exit(1);
pnewnode->data=val;
pnewnode->next=NULL;
//判断插入位置是否合法
if(pos<0||pos>Get_length(head))
return false;
//找到插入位置的前驱结点
struct Node*p=head;
for(int i=0;inext;
}
//修改插入位置的指针域
pnewnode->next=p->next;
//修改前驱结点的后继结点
p->next=pnewnode;
return true;
}
2.2.4 总结
①插入时,先申请一个新的结点,并为新节点赋值。
②找到插入位置的前驱结点。
③先修改插入位置的指针域,再修改前驱结点的指针域。
2.3 单链表的删除
2.3.1 单链表的头删
1.理解:删除单链表的第一个有效结点。
①判断单链表是否为空,如果不为空,执行②。
②找到删除位置前驱结点:头插不需要找删除位置。
③修改删除位置前驱结点的指针域:使指向删除位置的后继结点。
④释放删除位置的指针域,并置为空。

2.代码实现:
bool Del_head(PNode head)
{
//判断链表是否为空
if(Is_empty(head))
return false;
//定义指针指向待删除的结点
Node*p=head->next;
//修改前驱结点的指针域
head->next=p->next;
//释放待删除结点
free(p);
p=NULL;
return true;
}2.3.2 单链表的尾删
1.理解:删除单链表的最后一个结点(尾结点)。
①判断单链表是否为空,如果不为空,则执行②。
②找到删除位置的前驱结点:(单链表只能向后遍历)
方法1:从头到尾遍历链表,找到尾结点。再从头到尾,找到尾结点的前驱结点。
方法2:从头到尾遍历链表,先找到尾结点的前驱结点,再找到尾结点。(每次判断两个指针域。)
③修改删除位置前驱结点的指针域:让其指向删除结点的后继结点。
④释放删除位置的指针域,并将其置为空。

2.代码实现:
bool Del_tail(PNode head)
{
//判断链表是否为空
if(Is_empty(head))
return false;
//方法1:
/*//先找到尾结点
Node*q=head;
for(;q->next!=NULL;q=q->next);
//再找尾节点的前驱结点
Node*p=head;
for(;p->next!=q;p=p->next) ;*/
//方法2:
//先找到待删除节点(尾结点)的前驱结点
Node*p=head;//指向待删除结点的前驱
for(;p->next->next!=NULL;p=p->next);
//再找到待删除结点
Node*q=p->next;//指向待删除结点
//修改前驱结点的指针域
p->next=q->next;
//释放待删除结点
free(q);
q=NULL;
return true;
}2.3.3 单链表的按位置删
1.理解:根据指定的位置删除。
①先判断链表是否为空,如果不为空,则执行②。
②判断删除位置是否有效,有效位置[0,length)。此处有效位置不包括length,与按位置插入区别。
③找到删除位置的前驱结点:通过for循环遍历,找到删除位置前驱结点。
③修改删除位置前驱结点的指针域:让其指向删除结点的后继结点。
④释放删除位置的指针域,并将其置为空。

2.代码实现:
bool Del_Pos(PNode head,int pos)
{
//判断链表是否为空
if(Is_empty(head))
return false;
//判断插入位置是否合法
if(pos<0||pos>=Get_length(head))
return false;
//找到删除位置的前驱结点
Node*p=head;
for(int i=0;inext;
}
Node*q=p->next;
//修改前驱结点的指针域
p->next=q->next;
//释放待删除结点
free(q);
q=NULL;
return true;
} 2.3.4 单链表的按值删——删除第一次出现的地方
1.理解:根据对应的值,找到删除的位置,并删除。
①先判断链表是否为空,如果不为空,则执行②。
②判断链表中是否能够找到该值,如果能够找到该值,则执行③。
③找到删除位置的前驱结点:通过for循环遍历,找到删除位置前驱结点。
③修改删除位置前驱结点的指针域:让其指向删除结点的后继结点。
④释放删除位置的指针域,并将其置为空。
2.代码实现:
//按值删(删除第一次出现的位置)
bool Del_val(PNode head,ELEM_TYPE val)
{
//判断链表是否为空
if(Is_empty(head))
return false;
//判断是否能够找到该值
struct Node*q=Search(head,val);
if(q==NULL)
return false;
//找到删除结点的前驱结点
Node*p=head;
for(;p->next!=q;p=p->next);
//修改前驱结点的指针域
p->next=q->next;
//释放待删除结点
free(q);
q=NULL;
return true;
}2.3.5 总结
①先判断链表是否为空。
②找到删除结点的前驱结点,使其指向删除节点的后继结点。
③释放删除结点,并将删除结点置空。
2.4 单链表的查找
1.理解:从头到尾遍历单链表,判断是否能够找到该值所在的结点。
2.代码实现:
struct Node*Search(PNode head,ELEM_TYPE val)
{
//判断链表是否为空
if(Is_empty(head))
return false;
//遍历整个链表判断
Node*p=head->next;
for(;p!=NULL;p=p->next)
{
if(p->data==val)
{
return p;
}
}
return NULL;
}2.5 单链表的清空
1.理解:单链表的清空就是销毁。
2.代码实现:
void Clear(PNode head)
{
Destory1(head);
}2.6 单链表的销毁
2.6.1 辅助结点参与
1.理解:借用辅助结点,不断进行头删,直到单链表为空。
2.代码实现:
void Destory1(PNode head)
{
while(!Is_empty(head))
{
Del_head(head);
}
}2.6.2 不需要辅助结点参与
1.理解:使用两个变量一个指向当前结点,一个指向当前结点的后继结点,不断修改当前结点为后继结点,直到当前结点遍历到最后一个结点。
2.代码实现:
void Destory2(PNode head)
{
Node*p=head->next;//指向当前结点
Node*q=NULL;//q指针表示当前结点的后继结点
while(p!=NULL)
{
q=p->next;//指向后继结点
free(p);//删除当前结点
p=q;//当前结点变为后继结点
}
//销毁完毕将辅助结点的指针域置空
head->next=NULL;
}2.7 单链表的判空
1.理解:如果辅助结点的指针域为空,则代表单链表为空。
2.代码实现:
bool Is_empty(PNode head)
{
return head->next==NULL;
}2.8 获取单链表的长度
1.理解:定义一个变量,从头到尾遍历链表,每次遍历,变量+1。
2.代码实现:
int Get_length(PNode head)
{
Node*p=head->next;
int count=0;
for(;p!=NULL;p=p->next)
{
count++;
}
return count;
} 2.9 打印单链表
1.理解:从头到尾遍历链表,并将每个结点的数据域打印。
2.代码实现:
void Show(PNode head)
{
Node*p=head->next;
for(;p!=NULL;p=p->next)
{
printf("%d ",p->data);
}
printf("\n");
}